So berechnen sie einen gleitenden durchschnitt in pandas
Ein gleitender Durchschnitt ist einfach der Durchschnitt einer Reihe vorheriger Perioden in einer Zeitreihe.
Um den gleitenden Durchschnitt einer oder mehrerer Spalten in einem Pandas-DataFrame zu berechnen, können wir die folgende Syntax verwenden:
df[' column_name ']. rolling ( rolling_window ). mean ()
Dieses Tutorial bietet mehrere Beispiele für die praktische Verwendung dieser Funktion.
Beispiel: Berechnung des gleitenden Durchschnitts in Pandas
Angenommen, wir haben den folgenden Pandas-DataFrame:
import numpy as np import pandas as pd #make this example reproducible n.p. random . seeds (0) #create dataset period = np. arange (1, 101, 1) leads = np. random . uniform (1, 20, 100) sales = 60 + 2*period + np. random . normal (loc=0, scale=.5*period, size=100) df = pd. DataFrame ({' period ': period, ' leads ': leads, ' sales ': sales}) #view first 10 rows df. head (10) period leads sales 0 1 11.427457 61.417425 1 2 14.588598 64.900826 2 3 12.452504 66.698494 3 4 11.352780 64.927513 4 5 9.049441 73.720630 5 6 13.271988 77.687668 6 7 9.314157 78.125728 7 8 17.943687 75.280301 8 9 19.309592 73.181613 9 10 8.285389 85.272259
Mit der folgenden Syntax können wir eine neue Spalte erstellen, die den gleitenden Durchschnitt der „Verkäufe“ der letzten fünf Zeiträume enthält:
#find rolling mean of previous 5 sales periods df[' rolling_sales_5 '] = df[' sales ']. rolling (5). mean () #view first 10 rows df. head (10) period leads sales rolling_sales_5 0 1 11.427457 61.417425 NaN 1 2 14.588598 64.900826 NaN 2 3 12.452504 66.698494 NaN 3 4 11.352780 64.927513 NaN 4 5 9.049441 73.720630 66.332978 5 6 13.271988 77.687668 69.587026 6 7 9.314157 78.125728 72.232007 7 8 17.943687 75.280301 73.948368 8 9 19.309592 73.181613 75.599188 9 10 8.285389 85.272259 77.909514
Wir können manuell überprüfen, ob der für Periode 5 angezeigte gleitende Umsatzdurchschnitt dem Durchschnitt der vorherigen 5 Perioden entspricht:
Gleitender Durchschnitt in Periode 5: (61,417+64,900+66,698+64,927+73,720)/5 = 66,33
Wir können eine ähnliche Syntax verwenden, um den gleitenden Durchschnitt mehrerer Spalten zu berechnen:
#find rolling mean of previous 5 leads periods df[' rolling_leads_5 '] = df[' leads ']. rolling (5). mean () #find rolling mean of previous 5 leads periods df[' rolling_sales_5 '] = df[' sales ']. rolling (5). mean () #view first 10 rows df. head (10) period leads sales rolling_sales_5 rolling_leads_5 0 1 11.427457 61.417425 NaN NaN 1 2 14.588598 64.900826 NaN NaN 2 3 12.452504 66.698494 NaN NaN 3 4 11.352780 64.927513 NaN NaN 4 5 9.049441 73.720630 66.332978 11.774156 5 6 13.271988 77.687668 69.587026 12.143062 6 7 9.314157 78.125728 72.232007 11.088174 7 8 17.943687 75.280301 73.948368 12.186411 8 9 19.309592 73.181613 75.599188 13.777773 9 10 8.285389 85.272259 77.909514 13.624963
Mit Matplotlib können wir auch ein schnelles Liniendiagramm erstellen, um den Bruttoumsatz im Vergleich zum gleitenden Umsatzdurchschnitt zu visualisieren:
import matplotlib. pyplot as plt
plt. plot (df[' rolling_sales_5 '], label=' Rolling Mean ')
plt. plot (df[' sales '], label=' Raw Data ')
plt. legend ()
plt. ylabel (' Sales ')
plt. xlabel (' Period ')
plt. show ()
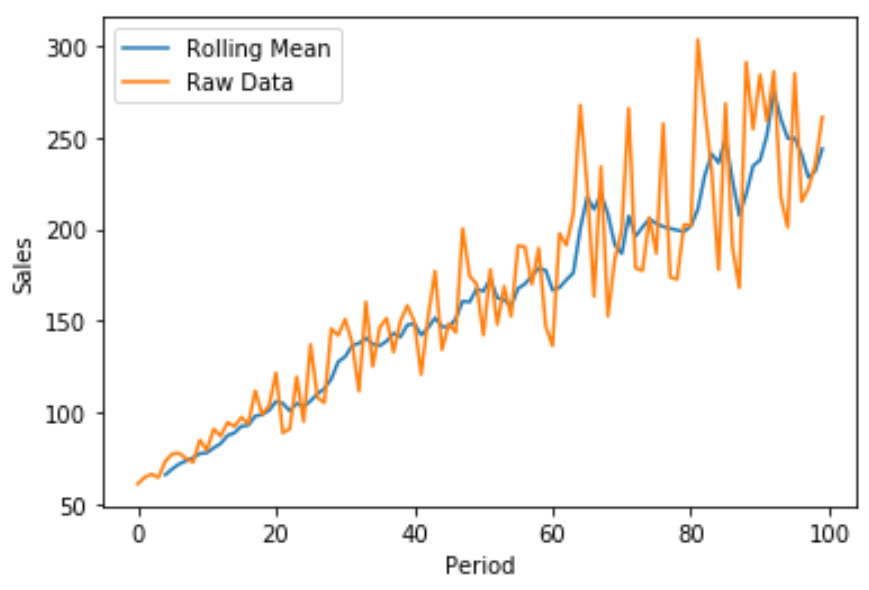
Die blaue Linie zeigt den gleitenden 5-Perioden-Durchschnitt der Verkäufe und die orange Linie zeigt die Rohverkaufsdaten.
Zusätzliche Ressourcen
In den folgenden Tutorials wird erläutert, wie Sie andere häufige Aufgaben in Pandas ausführen:
So berechnen Sie die gleitende Korrelation bei Pandas
So berechnen Sie den Durchschnitt der Spalten in Pandas
Über den Autor
Dr. Benjamin Anderson
Hallo, ich bin Benjamin, ein pensionierter Statistikprofessor, der sich zum engagierten Statorials-Lehrer entwickelt hat. Mit umfassender Erfahrung und Fachwissen auf dem Gebiet der Statistik bin ich bestrebt, mein Wissen zu teilen, um Studenten durch Statorials zu befähigen. Mehr wissen