So führen sie einen chi-quadrat-anpassungstest in stata durch
Mithilfe eines Chi-Quadrat-Anpassungstests wird ermittelt, ob eine kategoriale Variable einer hypothetischen Verteilung folgt oder nicht.
In diesem Tutorial wird erläutert, wie Sie in Stata einen Chi-Quadrat-Anpassungstest durchführen.
Beispiel: Chi-Quadrat-Anpassungstest in Stata
Um zu veranschaulichen, wie dieser Test durchgeführt wird, verwenden wir einen Datensatz namens nlsw88 , der Informationen zur Arbeitsstatistik von Frauen in den Vereinigten Staaten im Jahr 1988 enthält.
Befolgen Sie die folgenden Schritte, um einen Chi-Quadrat-Anpassungstest durchzuführen, um zu bestimmen, ob die wahre Verteilung der Rasse in diesem Datensatz wie folgt lautet: 70 % Weiße, 20 % Schwarze, 10 % Andere.
Schritt 1: Rohdaten laden und anzeigen.
Zuerst laden wir die Daten, indem wir den folgenden Befehl eingeben:
nlsw88-System
Wir können die Rohdaten anzeigen, indem wir den folgenden Befehl eingeben:
br
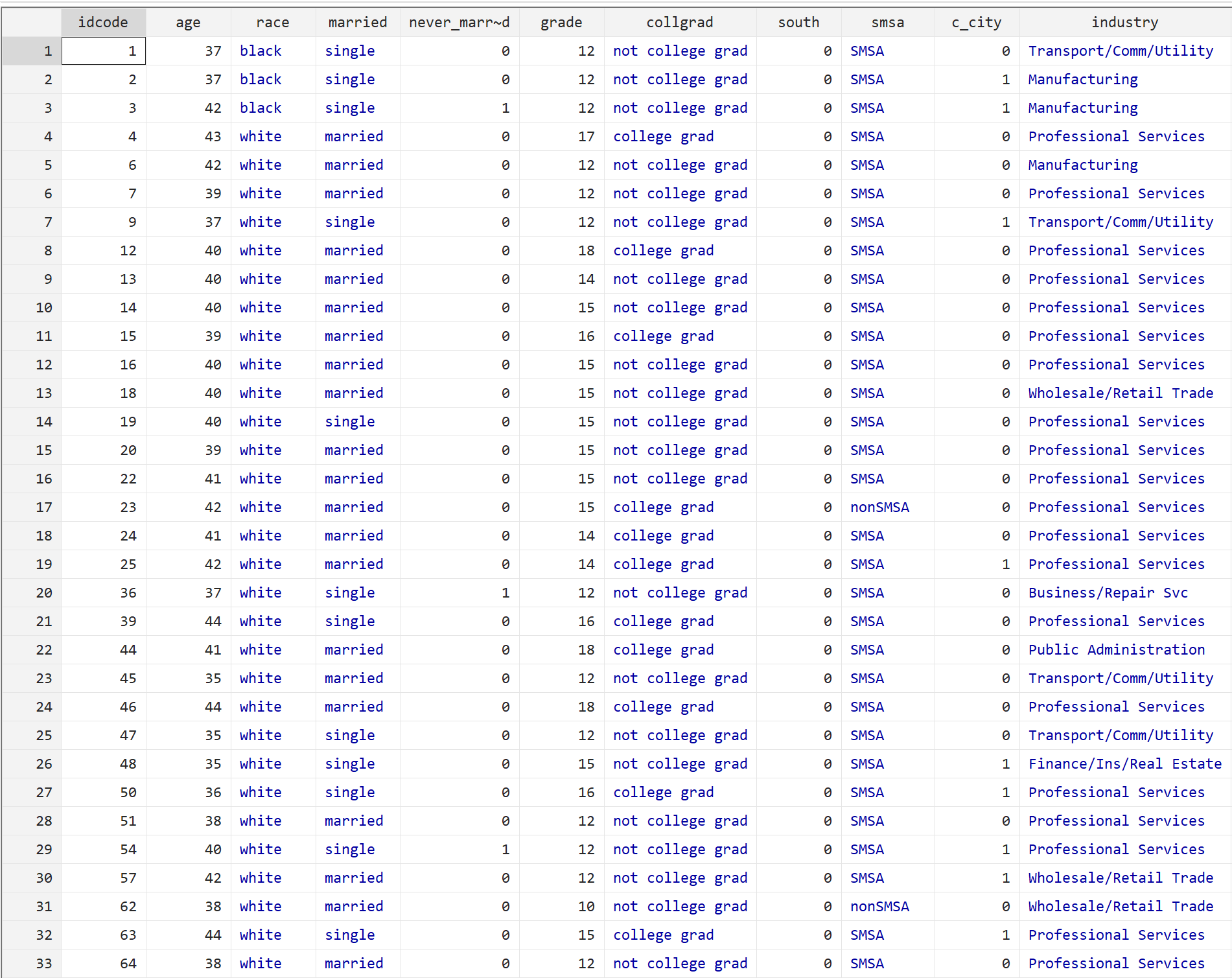
In jeder Zeile werden Informationen zu einer Person angezeigt, darunter Alter, Rasse, Familienstand, Bildungsniveau und verschiedene andere Faktoren.
Schritt 2: Laden Sie das Anpassungspaket.
Um einen Eignungstest durchzuführen, müssen wir das csgof- Paket installieren. Wir können dies tun, indem wir den folgenden Befehl eingeben:
finde csgof
Es erscheint ein neues Fenster. Klicken Sie auf den Link „csgof“ von https://stats.idre.ucla.edu/stat/stata/ado/analysis .
Es erscheint ein weiteres Fenster. Klicken Sie auf den Link „Klicken Sie hier, um zu installieren“ .
Die Installation des Pakets sollte nur wenige Sekunden dauern.
Schritt 3: Führen Sie den Fit-Test durch.
Sobald das Paket installiert ist, können wir den Anpassungstest an den Daten durchführen, um festzustellen, ob die tatsächliche Rassenverteilung wie folgt aussieht: 70 % Weiße, 20 % Schwarze, 10 % Andere.
Wir werden die folgende Syntax verwenden, um den Test durchzuführen:
csgof variable_of_interest, expperc(list_of_expected_percentages)
Hier ist die genaue Syntax, die wir in unserem Fall verwenden werden:
csgof ausführen, expperc(70, 20, 10)

So interpretieren Sie das Ergebnis:
Zusammenfassungsfeld: Dieses Feld zeigt uns den erwarteten Prozentsatz, die erwartete Häufigkeit und die beobachtete Häufigkeit für jedes Rennen. Zum Beispiel:
- Der erwartete Anteil weißer Personen betrug 70 %. Dies ist der Prozentsatz, den wir angegeben haben.
- Die erwartete Häufigkeit weißer Personen betrug 1.572,2. Dies wird anhand der Tatsache berechnet, dass der Datensatz 2.246 Personen enthielt, sodass 70 % dieser Zahl 1.572,2 sind.
- Die beobachtete Häufigkeit weißer Personen betrug 1.637. Dies ist die tatsächliche Anzahl weißer Personen im Datensatz.
Chisq(2): Dies ist die Chi-Quadrat-Teststatistik für den Anpassungstest. Es stellt sich heraus, dass es 218,13 ist.
p: Dies ist der p-Wert, der der Chi-Quadrat-Teststatistik zugeordnet ist. Es stellt sich heraus, dass es 0 ist. Da es weniger als 0,05 ist, können wir die Nullhypothese nicht zurückweisen, dass die wahre Rassenverteilung 70 % Weiße, 20 % Schwarze und 10 % Andere beträgt. Wir haben genügend Beweise, um zu dem Schluss zu kommen, dass sich die wahre Rassenverteilung von dieser hypothetischen Verteilung unterscheidet.
Über den Autor
Dr. Benjamin Anderson
Hallo, ich bin Benjamin, ein pensionierter Statistikprofessor, der sich zum engagierten Statorials-Lehrer entwickelt hat. Mit umfassender Erfahrung und Fachwissen auf dem Gebiet der Statistik bin ich bestrebt, mein Wissen zu teilen, um Studenten durch Statorials zu befähigen. Mehr wissen