So führen sie einen chow-test in python durch
Mit einem Chow-Test wird getestet, ob die Koeffizienten zweier unterschiedlicher Regressionsmodelle auf unterschiedlichen Datensätzen gleich sind.
Dieser Test wird typischerweise im Bereich der Ökonometrie mit Zeitreihendaten verwendet, um festzustellen, ob zu einem bestimmten Zeitpunkt ein Strukturbruch in den Daten vorliegt.
Das folgende Schritt-für-Schritt-Beispiel zeigt, wie Sie einen Chow-Test in Python durchführen.
Schritt 1: Erstellen Sie die Daten
Zuerst erstellen wir gefälschte Daten:
import pandas as pd #createDataFrame df = pd. DataFrame ({' x ': [1, 1, 2, 3, 4, 4, 5, 5, 6, 7, 7, 8, 8, 9, 10, 10, 11, 12, 12, 13, 14, 15, 15, 16, 17, 18, 18, 19, 20, 20], ' y ': [3, 5, 6, 10, 13, 15, 17, 14, 20, 23, 25, 27, 30, 30, 31, 33, 32, 32, 30, 32, 34, 34, 37, 35, 34, 36, 34, 37, 38, 36]}) #view first five rows of DataFrame df. head () x y 0 1 3 1 1 5 2 2 6 3 3 10 4 4 13
Schritt 2: Visualisieren Sie die Daten
Als Nächstes erstellen wir ein einfaches Streudiagramm zur Visualisierung der Daten:
import matplotlib. pyplot as plt
#create scatterplot
plt. plot (df. x , df. y , ' o ')
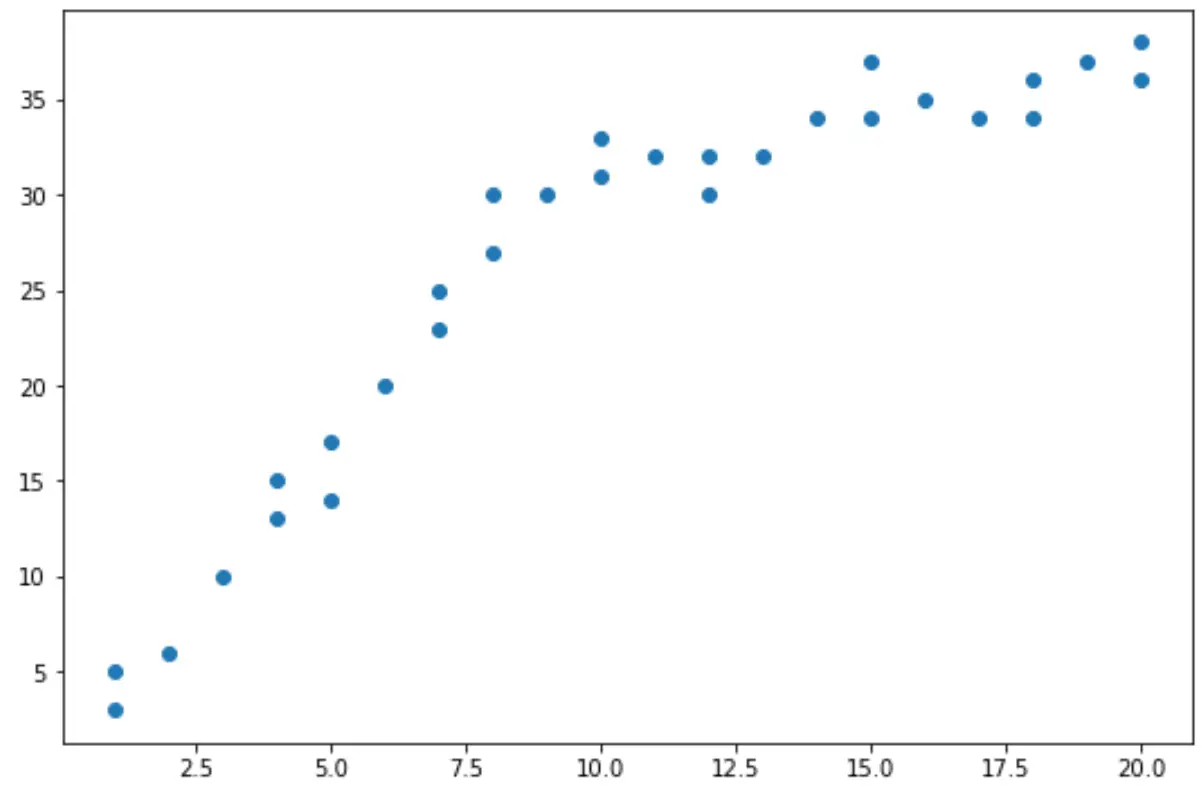
Aus dem Streudiagramm können wir ersehen, dass sich der Trend in den Daten bei x = 10 zu ändern scheint.
Somit können wir den Chow-Test durchführen, um festzustellen, ob es in den Daten bei x = 10 einen strukturellen Haltepunkt gibt.
Schritt 3: Führen Sie den Chow-Test durch
Wir können die Funktion chowtest des Pakets chowtest in Python verwenden, um einen Chow-Test durchzuführen.
Zuerst müssen wir dieses Paket mit pip installieren:
pip install chowtest
Dann können wir die folgende Syntax verwenden, um den Chow-Test durchzuführen:
from chow_test import chowtest chowtest ( y=df[[' y ']], last_index_in_model_1= 15 , first_index_in_model_2= 16 , significance_level= .05 ) ************************************************** ********************************* Reject the null hypothesis of equality of regression coefficients in the 2 periods. ************************************************** ********************************* Chow Statistic: 118.14097335479373 p value: 0.0 ************************************************** ********************************* (118.14097335479373, 1.1102230246251565e-16)
Die einzelnen Argumente in der Funktion chowtest() bedeuten Folgendes:
- y : Die Antwortvariable im DataFrame
- x : Die Vorhersagevariable im DataFrame
- last_index_in_model_1 : Der Indexwert des letzten Punkts vor dem Strukturbruch
- first_index_in_model_2 : Der Indexwert für den ersten Punkt nach dem Strukturbruch
- Signifikanzniveau : Das für den Hypothesentest zu verwendende Signifikanzniveau
Aus dem Testergebnis können wir erkennen:
- F-Test- Statistik : 118,14
- p-Wert: <.0000
Da der p-Wert kleiner als 0,05 ist, können wir die Nullhypothese des Tests ablehnen. Das bedeutet, dass wir genügend Beweise dafür haben, dass in den Daten ein struktureller Bruchpunkt vorhanden ist.
Mit anderen Worten: Zwei Regressionslinien können das Modell effektiver in die Daten einpassen als eine einzelne Regressionslinie.
Zusätzliche Ressourcen
In den folgenden Tutorials wird erläutert, wie Sie andere gängige Tests in Python durchführen:
So führen Sie einen Granger-Kausalitätstest in Python durch
So führen Sie einen Breusch-Pagan-Test in Python durch
So führen Sie den White-Test in Python durch
Über den Autor
Dr. Benjamin Anderson
Hallo, ich bin Benjamin, ein pensionierter Statistikprofessor, der sich zum engagierten Statorials-Lehrer entwickelt hat. Mit umfassender Erfahrung und Fachwissen auf dem Gebiet der Statistik bin ich bestrebt, mein Wissen zu teilen, um Studenten durch Statorials zu befähigen. Mehr wissen