So erstellen sie schnell pivottables in r
In Excel bieten Pivot-Tabellen eine einfache Möglichkeit, Daten zu gruppieren und zusammenzufassen.
Wenn wir beispielsweise den folgenden Datensatz in Excel haben, können wir eine Pivot-Tabelle verwenden, um den Gesamtumsatz nach Region schnell zusammenzufassen:
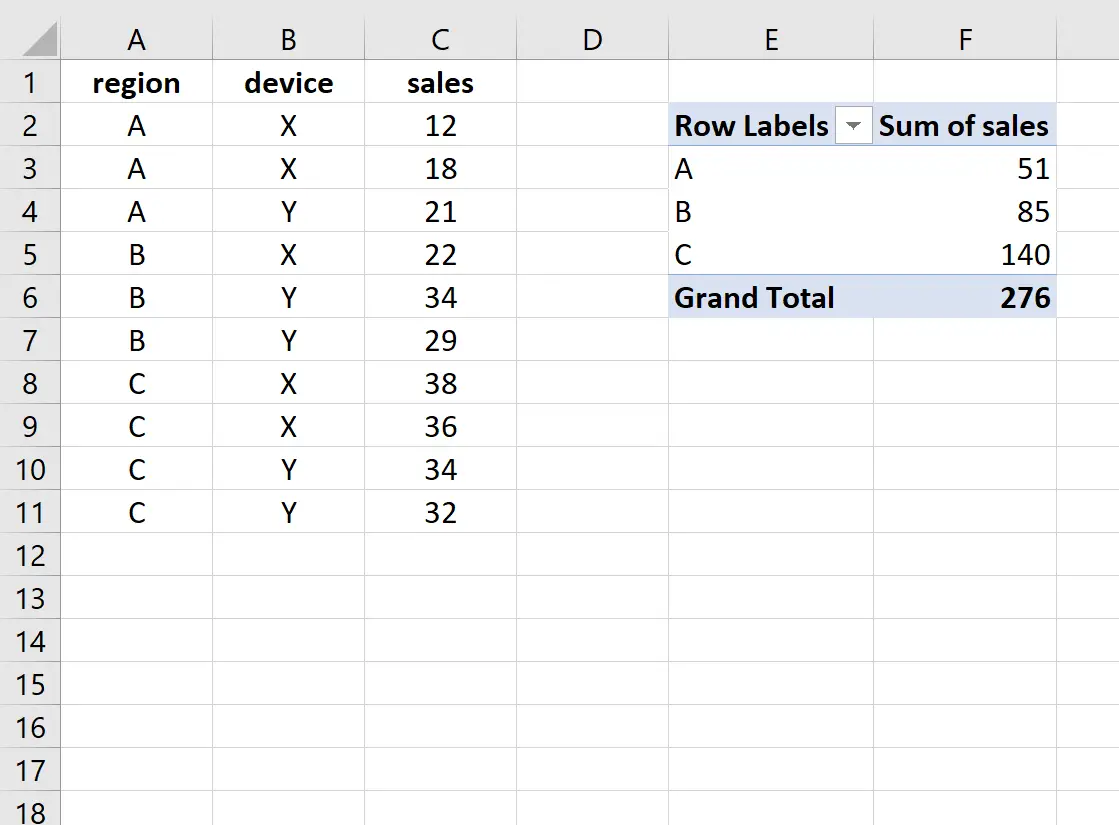
Das sagt uns:
- Region A verzeichnete insgesamt 51 Verkäufe
- Region B verzeichnete insgesamt 85 Verkäufe
- Region C erzielte insgesamt 140 Verkäufe
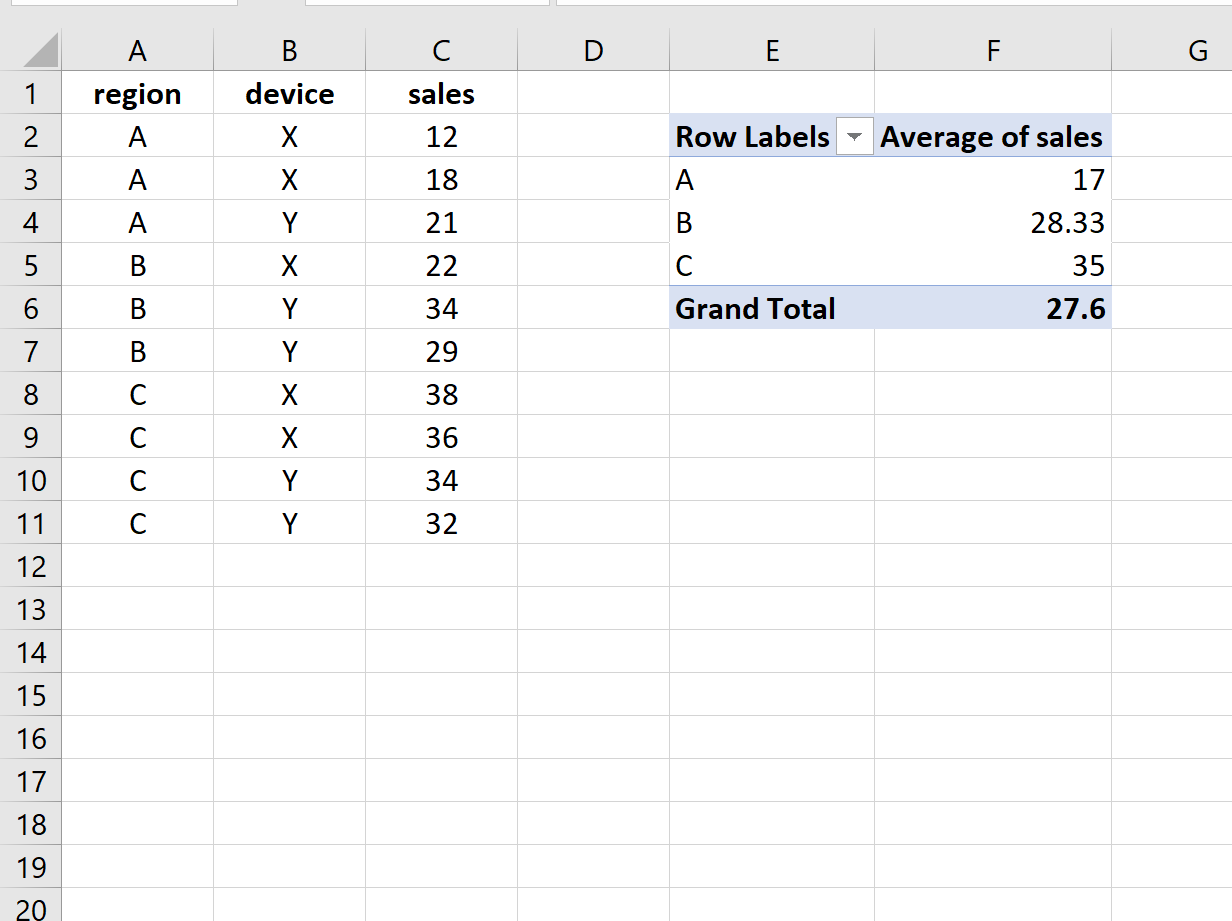
Oder wir könnten anhand einer anderen Kennzahl zusammenfassen, beispielsweise dem durchschnittlichen Umsatz nach Region:
Es stellt sich heraus, dass wir mit den Funktionen group_by() und summary() aus dem dplyr- Paket schnell ähnliche Pivot-Tabellen in R erstellen können.
Dieses Tutorial enthält mehrere Beispiele dafür.
Beispiel: PivotTables in R erstellen
Erstellen wir zunächst denselben Datensatz in R, den wir in den vorherigen Beispielen aus Excel verwendet haben:
#create data frame df <- data. frame (region=c('A', 'A', 'A', 'B', 'B', 'B', 'C', 'C', 'C', 'C'), device=c('X', 'X', 'Y', 'X', 'Y', 'Y', 'X', 'X', 'Y', 'Y'), sales=c(12, 18, 21, 22, 34, 29, 38, 36, 34, 32)) #view data frame df region device sales 1AX 12 2AX18 3 AY 21 4 BX22 5 BY 34 6 BY 29 7 CX 38 8CX36 9 CY 34 10 CY 32
Als nächstes laden wir das dplyr-Paket und verwenden die Funktionen group_by() und summary(), um nach Region zu gruppieren und die Summe der Verkäufe nach Region zu ermitteln:
library (dplyr) #find sum of sales by region df %>% group_by (region) %>% summarize (sum_sales = sum (sales)) # A tibble: 3 x 2 region sum_sales 1 to 51 2 B 85 3 C 140
Wir können sehen, dass diese Zahlen mit den im Excel-Einführungsbeispiel gezeigten Zahlen übereinstimmen.
Wir können auch den durchschnittlichen Umsatz nach Region berechnen:
#find average sales by region df %>% group_by (region) %>% summarize (mean_sales = mean (sales)) # A tibble: 3 x 2 region mean_sales 1 to 17 2 B 28.3 3 C 35
Auch hier stimmen diese Zahlen mit den im vorherigen Excel-Beispiel gezeigten Zahlen überein.
Beachten Sie, dass wir auch nach mehreren Variablen gruppieren können. Beispielsweise könnten wir die Summe der Verkäufe gruppiert nach Region und Gerätetyp ermitteln:
#find sum of sales by region and device type df %>% group_by (region, device) %>% summarize (sum_sales = sum (sales)) # A tibble: 6 x 3 # Groups: region [3] region device sum_sales 1AX30 2 AY 21 3 BX22 4 BY 63 5 CX 74 6 CY 66
Zusätzliche Ressourcen
So führen Sie einen VLOOKUP (ähnlich wie Excel) in R durch
Der vollständige Leitfaden: So gruppieren und fassen Sie Daten in R zusammen
Über den Autor
Dr. Benjamin Anderson
Hallo, ich bin Benjamin, ein pensionierter Statistikprofessor, der sich zum engagierten Statorials-Lehrer entwickelt hat. Mit umfassender Erfahrung und Fachwissen auf dem Gebiet der Statistik bin ich bestrebt, mein Wissen zu teilen, um Studenten durch Statorials zu befähigen. Mehr wissen