So verwenden sie die elbow-methode in python, um optimale cluster zu finden
Einer der gebräuchlichsten Clustering-Algorithmen beim maschinellen Lernen ist das sogenannte K-Means-Clustering .
K-Means-Clustering ist eine Technik, bei der wir jede Beobachtung aus einem Datensatz in einem von K Clustern platzieren.
Das Endziel besteht darin, K- Cluster zu haben, in denen die Beobachtungen innerhalb jedes Clusters einander ziemlich ähnlich sind, während sich die Beobachtungen in verschiedenen Clustern deutlich voneinander unterscheiden.
Beim K-Means-Clustering besteht der erste Schritt darin, einen Wert für K auszuwählen – die Anzahl der Cluster, in denen wir Beobachtungen platzieren möchten.
Eine der gebräuchlichsten Methoden zur Auswahl eines Werts für K ist die sogenannte Ellbogenmethode . Dabei wird ein Diagramm mit der Anzahl der Cluster auf der x-Achse und der Summe der Quadratsummen auf der y-Achse erstellt und anschließend identifiziert wo ein „Knie“ oder eine Wendung in der Handlung erscheint.
Der Punkt auf der x-Achse, an dem das „Knie“ auftritt, gibt uns die optimale Anzahl von Clustern an, die im k-means-Clustering-Algorithmus verwendet werden sollen.
Das folgende Beispiel zeigt, wie die Elbow-Methode in Python verwendet wird.
Schritt 1: Importieren Sie die erforderlichen Module
Zuerst importieren wir alle Module, die wir zum Durchführen von K-Means-Clustering benötigen:
import pandas as pd
import numpy as np
import matplotlib. pyplot as plt
from sklearn. cluster import KMeans
from sklearn. preprocessing import StandardScaler
Schritt 2: Erstellen Sie den DataFrame
Als Nächstes erstellen wir einen DataFrame, der drei Variablen für 20 verschiedene Basketballspieler enthält:
#createDataFrame
df = pd. DataFrame ({' points ': [18, np.nan, 19, 14, 14, 11, 20, 28, 30, 31,
35, 33, 29, 25, 25, 27, 29, 30, 19, 23],
' assists ': [3, 3, 4, 5, 4, 7, 8, 7, 6, 9, 12, 14,
np.nan, 9, 4, 3, 4, 12, 15, 11],
' rebounds ': [15, 14, 14, 10, 8, 14, 13, 9, 5, 4,
11, 6, 5, 5, 3, 8, 12, 7, 6, 5]})
#drop rows with NA values in any columns
df = df. dropna ()
#create scaled DataFrame where each variable has mean of 0 and standard dev of 1
scaled_df = StandardScaler(). fit_transform (df)
Schritt 3: Verwenden Sie die Ellbogenmethode, um die optimale Anzahl von Clustern zu ermitteln
Nehmen wir an, wir möchten K-Means-Clustering verwenden, um ähnliche Akteure basierend auf diesen drei Metriken zu gruppieren.
Um K-Means-Clustering in Python durchzuführen, können wir die KMeans- Funktion aus dem Sklearn- Modul verwenden.
Das wichtigste Argument dieser Funktion ist n_clusters , das angibt, in wie vielen Clustern Beobachtungen platziert werden sollen.
Um die optimale Anzahl an Clustern zu ermitteln, erstellen wir ein Diagramm, das die Anzahl der Cluster sowie die SSE (Summe der quadratischen Fehler) des Modells anzeigt.
Wir werden dann nach einem „Knie“ suchen, an dem sich die Summe der Quadrate zu „beugen“ oder zu stabilisieren beginnt. Dieser Punkt stellt die optimale Anzahl von Clustern dar.
Der folgende Code zeigt, wie man diese Art von Diagramm erstellt, das die Anzahl der Cluster auf der x-Achse und den SSE auf der y-Achse anzeigt:
#initialize kmeans parameters kmeans_kwargs = { " init ": " random ", " n_init ": 10, " random_state ": 1, } #create list to hold SSE values for each k sse = [] for k in range(1, 11): kmeans = KMeans(n_clusters=k, ** kmeans_kwargs) kmeans. fit (scaled_df) sse. append (kmeans.inertia_) #visualize results plt. plot (range(1, 11), sse) plt. xticks (range(1, 11)) plt. xlabel (" Number of Clusters ") plt. ylabel (“ SSE ”) plt. show ()
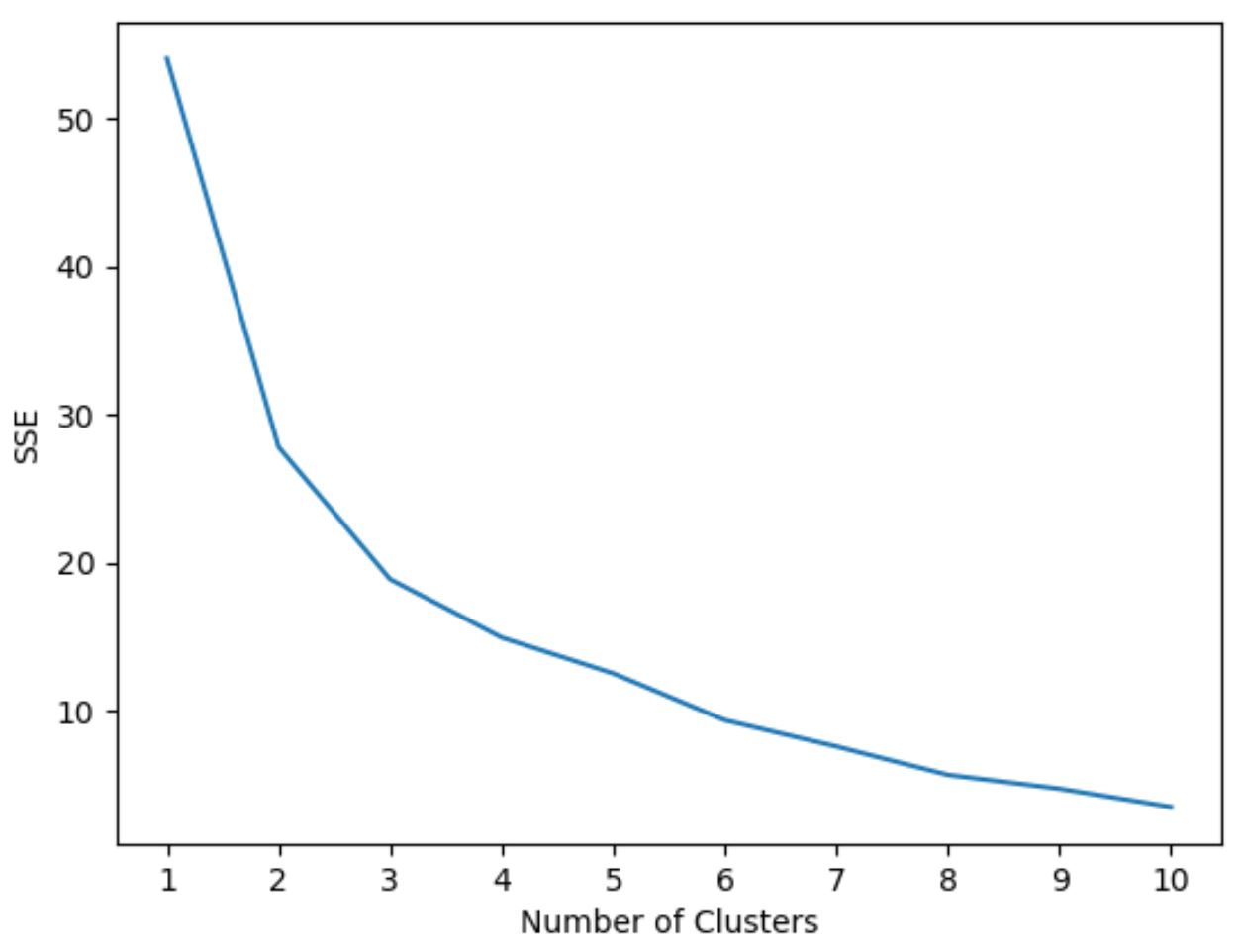
In diesem Diagramm scheint es, dass es bei k = 3 Clustern einen Knick oder ein „Knie“ gibt.
Daher werden wir im nächsten Schritt 3 Cluster verwenden, wenn wir unser k-Means-Clustering-Modell anpassen.
Schritt 4: Führen Sie K-Means-Clustering mit optimalem K durch
Der folgende Code zeigt, wie man k-Means-Clustering für den Datensatz unter Verwendung des optimalen Werts für k von 3 durchführt:
#instantiate the k-means class, using optimal number of clusters
kmeans = KMeans(init=" random ", n_clusters= 3 , n_init= 10 , random_state= 1 )
#fit k-means algorithm to data
kmeans. fit (scaled_df)
#view cluster assignments for each observation
kmeans. labels_
array([1, 1, 1, 1, 1, 1, 2, 2, 0, 0, 0, 0, 2, 2, 2, 0, 0, 0])
Die resultierende Tabelle zeigt die Clusterzuweisungen für jede Beobachtung im DataFrame.
Um die Interpretation dieser Ergebnisse zu erleichtern, können wir dem DataFrame eine Spalte hinzufügen, die die Clusterzuweisung jedes Spielers anzeigt:
#append cluster assingments to original DataFrame
df[' cluster '] = kmeans. labels_
#view updated DataFrame
print (df)
points assists rebounds cluster
0 18.0 3.0 15 1
2 19.0 4.0 14 1
3 14.0 5.0 10 1
4 14.0 4.0 8 1
5 11.0 7.0 14 1
6 20.0 8.0 13 1
7 28.0 7.0 9 2
8 30.0 6.0 5 2
9 31.0 9.0 4 0
10 35.0 12.0 11 0
11 33.0 14.0 6 0
13 25.0 9.0 5 0
14 25.0 4.0 3 2
15 27.0 3.0 8 2
16 29.0 4.0 12 2
17 30.0 12.0 7 0
18 19.0 15.0 6 0
19 23.0 11.0 5 0
Die Cluster- Spalte enthält eine Cluster-Nummer (0, 1 oder 2), der jeder Spieler zugewiesen wurde.
Spieler, die demselben Cluster angehören, haben ungefähr ähnliche Werte für die Spalten Punkte , Assists und Rebounds .
Hinweis : Die vollständige Dokumentation für die KMeans- Funktion von sklearn finden Sie hier .
Zusätzliche Ressourcen
Die folgenden Tutorials erklären, wie Sie andere häufige Aufgaben in Python ausführen:
So führen Sie eine lineare Regression in Python durch
So führen Sie eine logistische Regression in Python durch
So führen Sie eine K-Fold-Kreuzvalidierung in Python durch
Über den Autor
Dr. Benjamin Anderson
Hallo, ich bin Benjamin, ein pensionierter Statistikprofessor, der sich zum engagierten Statorials-Lehrer entwickelt hat. Mit umfassender Erfahrung und Fachwissen auf dem Gebiet der Statistik bin ich bestrebt, mein Wissen zu teilen, um Studenten durch Statorials zu befähigen. Mehr wissen