Entscheidungsbaum vs. zufallswälder: was ist der unterschied?
Ein Entscheidungsbaum ist eine Art maschinelles Lernmodell, das verwendet wird, wenn die Beziehung zwischen einer Reihe von Prädiktorvariablen und einer Antwortvariablen nichtlinear ist.
Die Grundidee eines Entscheidungsbaums besteht darin, mithilfe einer Reihe von Prädiktorvariablen einen „Baum“ zu erstellen, der mithilfe von Entscheidungsregeln den Wert einer Antwortvariablen vorhersagt.
Beispielsweise könnten wir die Prädiktorvariablen „gespielte Jahre“ und „durchschnittliche Homeruns“ verwenden, um das Jahresgehalt professioneller Baseballspieler vorherzusagen.
Unter Verwendung dieses Datensatzes könnte das Entscheidungsbaummodell so aussehen:
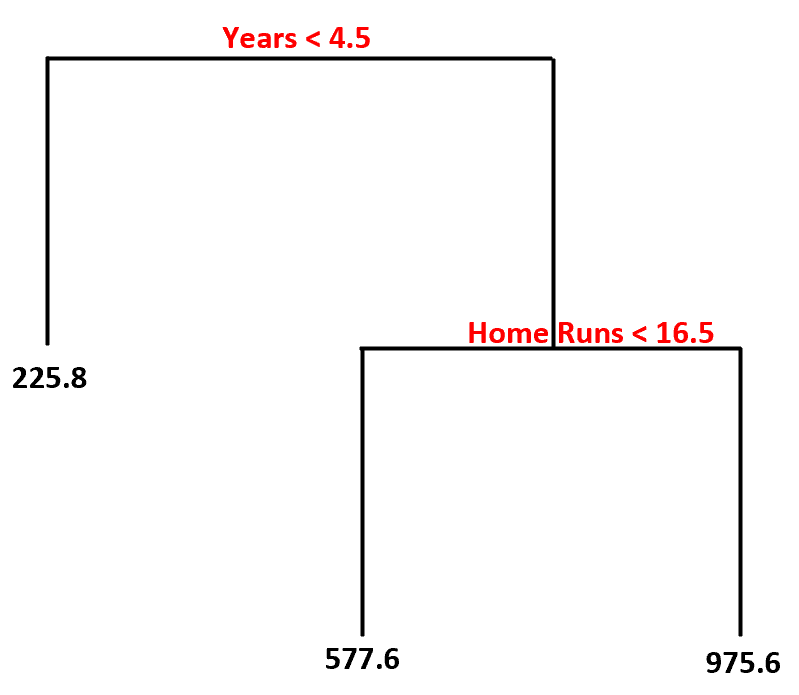
So würden wir diesen Entscheidungsbaum interpretieren:
- Spieler, die weniger als 4,5 Jahre gespielt haben, haben ein voraussichtliches Gehalt von 225,8.000 US-Dollar .
- Spieler, die mehr als 4,5 Jahre oder länger gespielt haben und im Durchschnitt weniger als 16,5 Homeruns absolviert haben, haben ein voraussichtliches Gehalt von 577,6.000 US-Dollar .
- Spieler mit 4,5 Jahren oder mehr Erfahrung und durchschnittlich 16,5 oder mehr Homeruns haben ein erwartetes Gehalt von 975,6.000 $ .
Der Hauptvorteil eines Entscheidungsbaums besteht darin, dass er schnell an einen Datensatz angepasst werden kann und das endgültige Modell mithilfe eines „Baum“-Diagramms wie dem oben genannten klar visualisiert und interpretiert werden kann.
Der Hauptnachteil besteht darin, dass ein Entscheidungsbaum dazu neigt, einen Trainingsdatensatz zu stark anzupassen , was bedeutet, dass er bei unsichtbaren Daten wahrscheinlich eine schlechte Leistung erbringt. Dies kann auch stark durch Ausreißer im Datensatz beeinflusst werden.
Eine Erweiterung des Entscheidungsbaums ist ein Modell namens Random Forest , das im Wesentlichen aus einer Reihe von Entscheidungsbäumen besteht.
Hier sind die Schritte, die wir verwenden, um ein zufälliges Gesamtstrukturmodell zu erstellen:
1. Nehmen Sie Bootstrap-Beispiele aus dem Originaldatensatz.
2. Erstellen Sie für jede Bootstrap-Stichprobe einen Entscheidungsbaum unter Verwendung einer zufälligen Teilmenge von Prädiktorvariablen.
3. Mitteln Sie die Vorhersagen jedes Baums, um ein endgültiges Modell zu erhalten.
Der Vorteil von Random Forests besteht darin, dass sie bei unsichtbaren Daten tendenziell eine viel bessere Leistung erbringen als Entscheidungsbäume und weniger anfällig für Ausreißer sind.
Der Nachteil von Random Forests besteht darin, dass es keine Möglichkeit gibt, das endgültige Modell zu visualisieren, und der Aufbau kann lange dauern, wenn Sie nicht über genügend Rechenleistung verfügen oder der Datensatz, mit dem Sie arbeiten, extrem umfangreich ist.
Vor- und Nachteile: Entscheidungsbäume vs. Zufällige Wälder
Die folgende Tabelle fasst die Vor- und Nachteile von Entscheidungsbäumen im Vergleich zu Zufallswäldern zusammen:
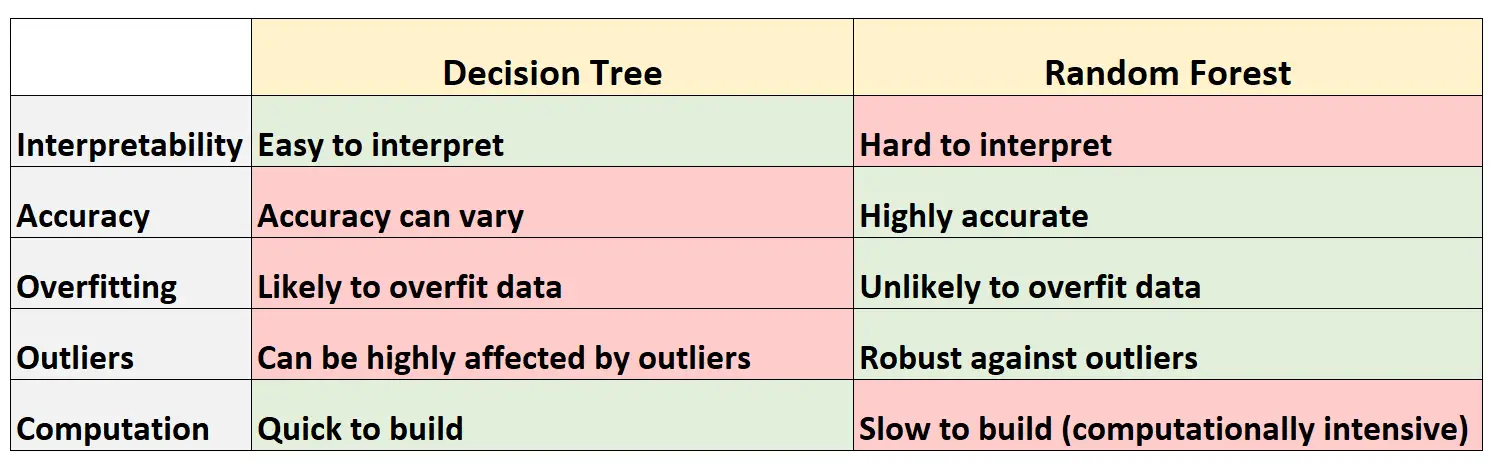
Hier ist eine kurze Erklärung jeder Zeile in der Tabelle:
1. Interpretierbarkeit
Entscheidungsbäume sind leicht zu interpretieren, da wir ein Baumdiagramm erstellen können, um das endgültige Modell zu visualisieren und zu verstehen.
Umgekehrt können wir uns einen Zufallswald nicht vorstellen, und es kann oft schwierig sein zu verstehen, wie das endgültige Zufallswaldmodell Entscheidungen trifft.
2. Genauigkeit
Da Entscheidungsbäume wahrscheinlich zu stark an einen Trainingsdatensatz angepasst sind, schneiden sie bei nicht sichtbaren Datensätzen tendenziell schlechter ab.
Umgekehrt sind Zufallswälder in der Regel bei unsichtbaren Datensätzen sehr genau, da sie eine Überanpassung von Trainingsdatensätzen vermeiden.
3. Überanpassung
Wie bereits erwähnt, passen Entscheidungsbäume häufig zu stark zu den Trainingsdaten: Dies bedeutet, dass sie sich wahrscheinlich an das „Rauschen“ eines Datensatzes anpassen, im Gegensatz zum eigentlichen zugrunde liegenden Modell.
Umgekehrt werden die endgültigen Bäume tendenziell dekoriert, da zufällige Gesamtstrukturen nur bestimmte Prädiktorvariablen verwenden, um jeden einzelnen Entscheidungsbaum zu erstellen, was bedeutet, dass zufällige Gesamtstrukturmodelle wahrscheinlich keine Überanpassung an Datensätze vornehmen.
4. Ausreißer
Entscheidungsbäume sind sehr anfällig für Ausreißer.
Da ein Random-Forest-Modell hingegen viele einzelne Entscheidungsbäume erstellt und dann den Durchschnitt der Vorhersagen dieser Bäume ermittelt, ist die Wahrscheinlichkeit, dass es von Ausreißern beeinflusst wird, deutlich geringer.
5. Berechnung
Entscheidungsbäume können schnell an Datensätze angepasst werden.
Umgekehrt sind Random Forests viel rechenintensiver und die Erstellung kann je nach Größe des Datensatzes lange dauern.
Wann werden Entscheidungsbäume oder Zufallswälder verwendet?
Allgemein:
Sie sollten einen Entscheidungsbaum verwenden, wenn Sie schnell ein nichtlineares Modell erstellen und einfach interpretieren möchten, wie das Modell Entscheidungen trifft.
Sie sollten jedoch eine zufällige Gesamtstruktur verwenden, wenn Sie über viel Rechenleistung verfügen und ein Modell erstellen möchten, das wahrscheinlich sehr genau ist, ohne sich Gedanken über die Interpretation des Modells machen zu müssen.
In der realen Welt verwenden Ingenieure für maschinelles Lernen und Datenwissenschaftler häufig Random Forests, da diese sehr genau sind und moderne Computer und Systeme häufig große Datensätze verarbeiten können, die zuvor nicht verarbeitet werden konnten.
Zusätzliche Ressourcen
Die folgenden Tutorials bieten eine Einführung in Entscheidungsbäume und Random-Forest-Modelle:
Die folgenden Tutorials erklären, wie Entscheidungsbäume und Zufallswälder in R angepasst werden:
Über den Autor
Dr. Benjamin Anderson
Hallo, ich bin Benjamin, ein pensionierter Statistikprofessor, der sich zum engagierten Statorials-Lehrer entwickelt hat. Mit umfassender Erfahrung und Fachwissen auf dem Gebiet der Statistik bin ich bestrebt, mein Wissen zu teilen, um Studenten durch Statorials zu befähigen. Mehr wissen