Eine einfache einführung zur förderung des maschinellen lernens
Die meisten überwachten Algorithmen für maschinelles Lernen basieren auf der Verwendung eines einzelnen Vorhersagemodells wie linearer Regression , logistischer Regression , Ridge-Regression usw.
Allerdings erstellen Methoden wie Bagging und Random Forests viele verschiedene Modelle basierend auf wiederholten Bootstrapping-Stichproben des Originaldatensatzes. Vorhersagen zu neuen Daten werden getroffen, indem der Durchschnitt der Vorhersagen der einzelnen Modelle gebildet wird.
Diese Methoden bieten tendenziell eine Verbesserung der Vorhersagegenauigkeit im Vergleich zu Methoden, die nur ein einziges Vorhersagemodell verwenden, da sie den folgenden Prozess verwenden:
- Erstellen Sie zunächst einzelne Modelle mit hoher Varianz und geringer Verzerrung (z. B. tief gewachsene Entscheidungsbäume ).
- Anschließend werden die Vorhersagen der einzelnen Modelle gemittelt, um die Varianz zu verringern.
Eine andere Methode, die tendenziell eine noch größere Verbesserung der Vorhersagegenauigkeit bietet, ist das sogenannte Boosting .
Was ist Boosten?
Boosting ist eine Methode, die mit jedem Modelltyp verwendet werden kann, am häufigsten wird sie jedoch bei Entscheidungsbäumen verwendet.
Die Idee hinter Boosting ist einfach:
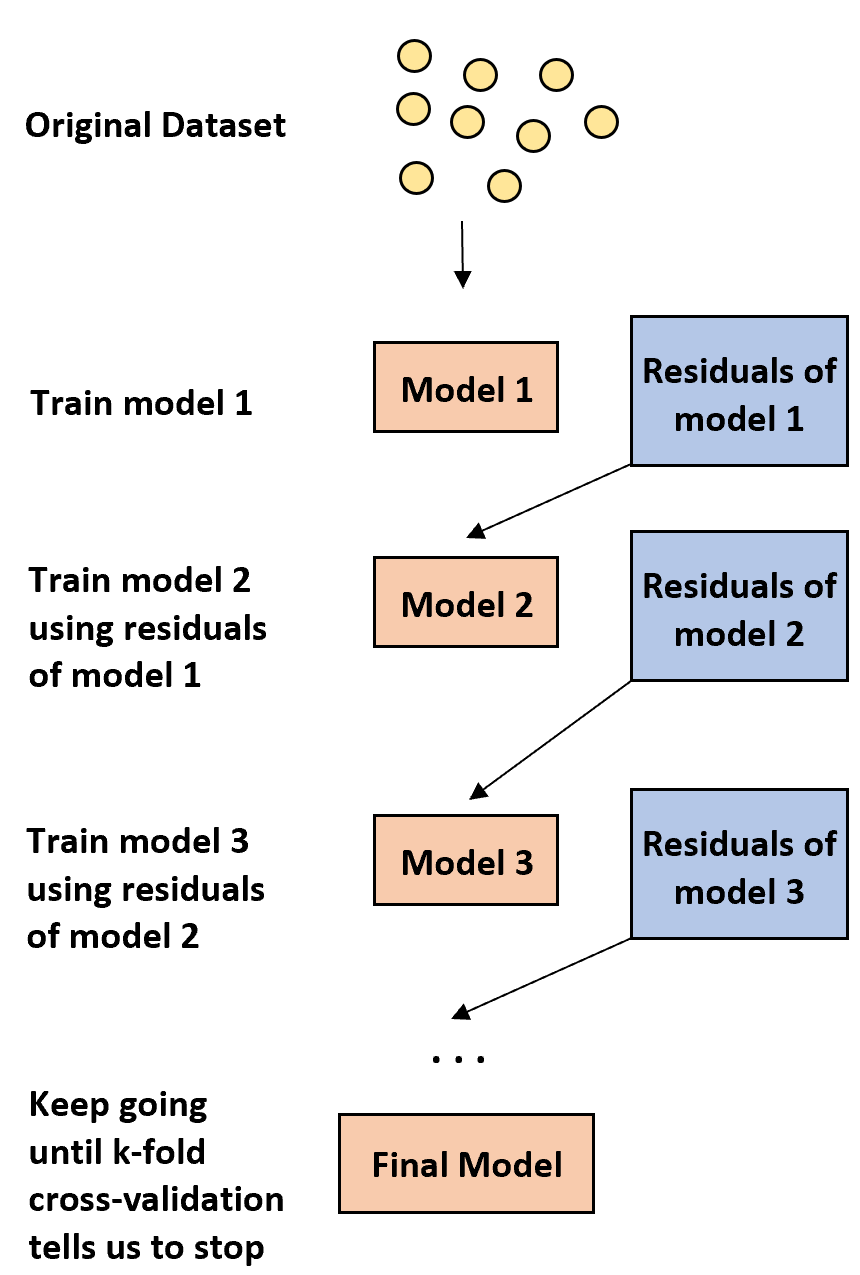
1. Erstellen Sie zunächst ein schwaches Modell.
- Ein „schwaches“ Modell ist eines, dessen Fehlerquote nur geringfügig besser ist als eine Zufallsschätzung.
- In der Praxis handelt es sich dabei meist um einen Entscheidungsbaum mit nur einer oder zwei Unterteilungen.
2. Erstellen Sie als Nächstes ein weiteres schwaches Modell basierend auf den Residuen des vorherigen Modells.
- In der Praxis verwenden wir die Residuen des vorherigen Modells (dh die Fehler in unseren Vorhersagen), um ein neues Modell anzupassen, das die Gesamtfehlerrate leicht verbessert.
3. Setzen Sie diesen Vorgang fort, bis uns die k-fache Kreuzvalidierung zum Stoppen auffordert.
- In der Praxis verwenden wir eine k-fache Kreuzvalidierung, um zu ermitteln, wann wir mit der Entwicklung des verstärkten Modells aufhören sollten.
Mit dieser Methode können wir mit einem schwachen Modell beginnen und seine Leistung weiter „verbessern“, indem wir nacheinander neue Bäume erstellen, die die Leistung des vorherigen Baums verbessern, bis wir ein endgültiges Modell mit hoher Vorhersagegenauigkeit erhalten.
Warum funktioniert Boosting?
Es stellt sich heraus, dass Boosting in der Lage ist, einige der leistungsstärksten Modelle im gesamten maschinellen Lernen zu erzeugen.
In vielen Branchen werden verstärkte Modelle als Referenzmodelle in der Produktion verwendet, da sie tendenziell alle anderen Modelle übertreffen.
Der Grund, warum Boosted-Vorlagen so gut funktionieren, liegt im Verständnis einer einfachen Idee:
1. Erstens erstellen die verbesserten Modelle einen schwachen Entscheidungsbaum mit geringer Vorhersagegenauigkeit. Dieser Entscheidungsbaum soll eine geringe Varianz und eine hohe Verzerrung aufweisen.
2. Da die verbesserten Modelle dem sequentiellen Verbesserungsprozess früherer Entscheidungsbäume folgen, ist das Gesamtmodell in der Lage, die Verzerrung bei jedem Schritt langsam zu reduzieren, ohne die Varianz wesentlich zu erhöhen.
3. Das endgültige angepasste Modell weist tendenziell eine ausreichend geringe Verzerrung und Varianz auf, was zu einem Modell führt, das in der Lage ist, niedrige Testfehlerraten bei neuen Daten zu erzeugen.
Vor- und Nachteile des Boostens
Der offensichtliche Vorteil des Boosting besteht darin, dass damit im Vergleich zu fast allen anderen Modelltypen Modelle mit hoher Vorhersagegenauigkeit erstellt werden können.
Ein möglicher Nachteil besteht darin, dass ein angepasstes verbessertes Modell sehr schwer zu interpretieren ist. Obwohl es eine enorme Fähigkeit bietet, Antwortwerte neuer Daten vorherzusagen, ist es schwierig, den genauen Prozess zu erklären, mit dem es dies erreicht.
In der Praxis erstellen die meisten Datenwissenschaftler und Praktiker des maschinellen Lernens verbesserte Modelle, weil sie die Antwortwerte neuer Daten genau vorhersagen möchten. Die Tatsache, dass verbesserte Modelle schwer zu interpretieren sind, stellt daher im Allgemeinen kein Problem dar.
Booster in der Praxis
In der Praxis werden viele Arten von Algorithmen zum Boosten verwendet, darunter:
Abhängig von der Größe Ihres Datensatzes und der Rechenleistung Ihres Computers ist möglicherweise eine dieser Methoden der anderen vorzuziehen.
Über den Autor
Dr. Benjamin Anderson
Hallo, ich bin Benjamin, ein pensionierter Statistikprofessor, der sich zum engagierten Statorials-Lehrer entwickelt hat. Mit umfassender Erfahrung und Fachwissen auf dem Gebiet der Statistik bin ich bestrebt, mein Wissen zu teilen, um Studenten durch Statorials zu befähigen. Mehr wissen