So generieren sie eine normalverteilung in python (mit beispielen)
Sie können in Python schnell eineNormalverteilung generieren, indem Sie die Funktion numpy.random.normal() verwenden, die die folgende Syntax verwendet:
numpy. random . normal (loc=0.0, scale=1.0, size=None)
Gold:
- loc: Durchschnitt der Verteilung. Der Standardwert ist 0.
- Skala: Standardabweichung der Verteilung. Der Standardwert ist 1.
- Größe: Stichprobengröße.
Dieses Tutorial zeigt ein Beispiel für die Verwendung dieser Funktion zum Generieren einer Normalverteilung in Python.
Verwandte Themen:So erstellen Sie eine Glockenkurve in Python
Beispiel: Generieren einer Normalverteilung in Python
Der folgende Code zeigt, wie man eine Normalverteilung in Python generiert:
from numpy. random import seed
from numpy. random import normal
#make this example reproducible
seed(1)
#generate sample of 200 values that follow a normal distribution
data = normal (loc=0, scale=1, size=200)
#view first six values
data[0:5]
array([ 1.62434536, -0.61175641, -0.52817175, -1.07296862, 0.86540763])
Wir können den Mittelwert und die Standardabweichung dieser Verteilung schnell ermitteln:
import numpy as np
#find mean of sample
n.p. mean (data)
0.1066888148479486
#find standard deviation of sample
n.p. std (data, ddof= 1 )
0.9123296653173484
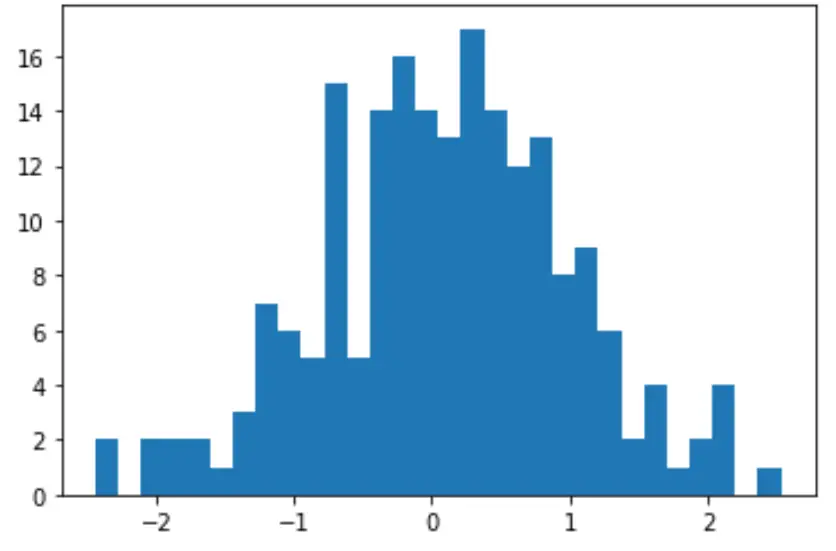
Wir können auch ein schnelles Histogramm erstellen, um die Verteilung der Datenwerte zu visualisieren:
import matplotlib. pyplot as plt
count, bins, ignored = plt. hist (data, 30)
plt. show ()
Wir können sogar einen Shapiro-Wilk-Test durchführen, um zu sehen, ob der Datensatz aus einer normalen Population stammt:
from scipy. stats import shapiro
#perform Shapiro-Wilk test
shapiro(data)
ShapiroResult(statistic=0.9958659410, pvalue=0.8669294714)
Der p-Wert des Tests beträgt 0,8669 . Da dieser Wert nicht kleiner als 0,05 ist, können wir davon ausgehen, dass die Stichprobendaten aus einer normalverteilten Grundgesamtheit stammen.
Dieses Ergebnis sollte nicht überraschen, da wir die Daten mit der Funktion numpy.random.normal() generiert haben, die eine zufällige Datenstichprobe aus einer Normalverteilung generiert.
Über den Autor
Dr. Benjamin Anderson
Hallo, ich bin Benjamin, ein pensionierter Statistikprofessor, der sich zum engagierten Statorials-Lehrer entwickelt hat. Mit umfassender Erfahrung und Fachwissen auf dem Gebiet der Statistik bin ich bestrebt, mein Wissen zu teilen, um Studenten durch Statorials zu befähigen. Mehr wissen