So berechnen sie die gewichtete standardabweichung in r
Die gewichtete Standardabweichung ist eine nützliche Methode zur Messung der Streuung von Werten in einem Datensatz, wenn einige Werte im Datensatz höhere Gewichte haben als andere.
Die Formel zur Berechnung einer gewichteten Standardabweichung lautet:
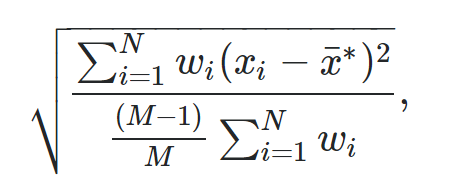
Gold:
- N: Die Gesamtzahl der Beobachtungen
- M: Die Anzahl der Gewichte ungleich Null
- w i : Ein Gewichtsvektor
- x i : Ein Vektor von Datenwerten
- x : Der gewichtete Durchschnitt
Der einfachste Weg, eine gewichtete Standardabweichung in R zu berechnen, ist die Verwendung der Funktion wt.var() aus dem Hmisc- Paket, die die folgende Syntax verwendet:
#define data values x <- c(4, 7, 12, 13, ...) #define weights wt <- c(.5, 1, 2, 2, ...) #calculate weighted variance weighted_var <- wtd. var (x, wt) #calculate weighted standard deviation weighted_sd <- sqrt(weighted_var)
Die folgenden Beispiele zeigen, wie Sie diese Funktion in der Praxis nutzen können.
Beispiel 1: Gewichtete Standardabweichung für einen Vektor
Der folgende Code zeigt, wie die gewichtete Standardabweichung für einen einzelnen Vektor in R berechnet wird:
library (Hmisc) #define data values x <- c(14, 19, 22, 25, 29, 31, 31, 38, 40, 41) #define weights wt <- c(1, 1, 1.5, 2, 2, 1.5, 1, 2, 3, 2) #calculate weighted variance weighted_var <- wtd. var (x, wt) #calculate weighted standard deviation sqrt(weighted_var) [1] 8.570051
Die gewichtete Standardabweichung beträgt 8,57 .
Beispiel 2: Gewichtete Standardabweichung für eine Spalte im Datenrahmen
Der folgende Code zeigt, wie die gewichtete Standardabweichung für eine Spalte eines Datenrahmens in R berechnet wird:
library (Hmisc) #define data frame df <- data. frame (team=c('A', 'A', 'A', 'A', 'A', 'B', 'B', 'C'), wins=c(2, 9, 11, 12, 15, 17, 18, 19), dots=c(1, 2, 2, 2, 3, 3, 3, 3)) #define weights wt <- c(1, 1, 1.5, 2, 2, 1.5, 1, 2) #calculate weighted standard deviation of points sqrt(wtd. var (df$points, wt)) [1] 0.6727938
Die gewichtete Standardabweichung für die Punktespalte beträgt 0,673 .
Beispiel 3: Gewichtete Standardabweichung für mehrere Spalten in einem Datenrahmen
Der folgende Code zeigt, wie die Funktion sapply() in R verwendet wird, um die gewichtete Standardabweichung für mehrere Spalten in einem Datenrahmen zu berechnen:
library (Hmisc) #define data frame df <- data. frame (team=c('A', 'A', 'A', 'A', 'A', 'B', 'B', 'C'), wins=c(2, 9, 11, 12, 15, 17, 18, 19), dots=c(1, 2, 2, 2, 3, 3, 3, 3)) #define weights wt <- c(1, 1, 1.5, 2, 2, 1.5, 1, 2) #calculate weighted standard deviation of points and wins sapply(df[c(' wins ', ' points ')], function(x) sqrt(wtd. var (x, wt))) win points 4.9535723 0.6727938
Die gewichtete Standardabweichung für die Spalte „Siege“ beträgt 4,954 und die gewichtete Standardabweichung für die Spalte „Punkte“ beträgt 0,673 .
Zusätzliche Ressourcen
So berechnen Sie die gewichtete Standardabweichung in Excel
So berechnen Sie die Standardabweichung in R
So berechnen Sie den Variationskoeffizienten von R
So berechnen Sie die Reichweite in R
Über den Autor
Dr. Benjamin Anderson
Hallo, ich bin Benjamin, ein pensionierter Statistikprofessor, der sich zum engagierten Statorials-Lehrer entwickelt hat. Mit umfassender Erfahrung und Fachwissen auf dem Gebiet der Statistik bin ich bestrebt, mein Wissen zu teilen, um Studenten durch Statorials zu befähigen. Mehr wissen