Equal frequency binning in python
Unter Gruppierung versteht man in der Statistik den Vorgang der Einordnung numerischer Werte in Gruppen .
Die gebräuchlichste Form des Clusterings ist das sogenannte Equal-Width-Clustering , bei dem wir einen Datensatz in k Gruppen gleicher Breite unterteilen.
Eine weniger häufig verwendete Form des Clusterings ist das sogenannte Equal-Frequency-Clustering , bei dem wir einen Datensatz in k Gruppen aufteilen, die alle die gleiche Anzahl von Häufigkeiten haben.
In diesem Tutorial wird erläutert, wie Sie in Python ein Clustering mit gleicher Häufigkeit durchführen.
Equal Frequency Binning in Python
Angenommen, wir haben einen Datensatz mit 100 Werten:
import numpy as np import matplotlib.pyplot as plt #create data np.random.seed(1) data = np.random.randn(100) #view first 5 values data[:5] array([ 1.62434536, -0.61175641, -0.52817175, -1.07296862, 0.86540763])
Gruppierung gleicher Breite:
Wenn wir ein Histogramm erstellen, um diese Werte anzuzeigen, verwendet Python standardmäßig die Gruppierung gleicher Breite:
#create histogram with equal-width bins n, bins, patches = plt.hist(data, edgecolor='black') plt.show() #display bin boundaries and frequency per bin bins, n (array([-2.3015387 , -1.85282729, -1.40411588, -0.95540447, -0.50669306, -0.05798165, 0.39072977, 0.83944118, 1.28815259, 1.736864, 2.18557541]), array([ 3., 1., 6., 17., 19., 20., 14., 12., 5., 3.]))
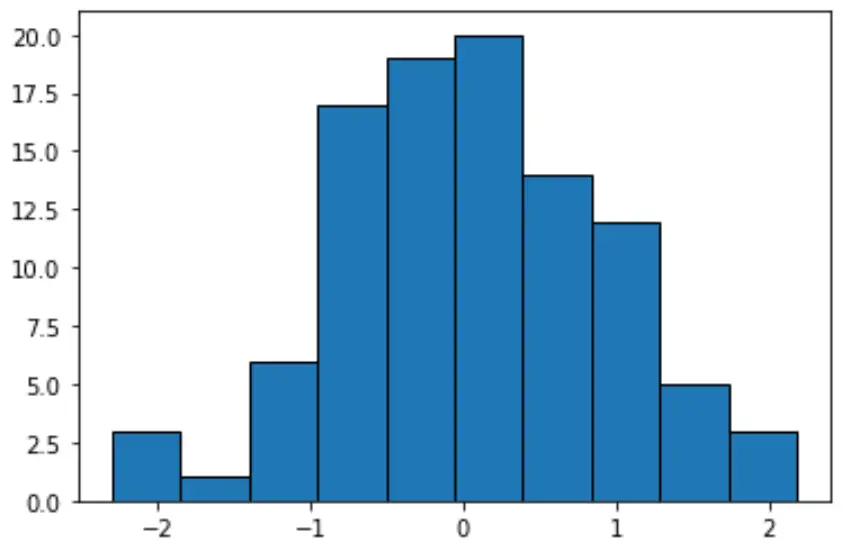
Jede Gruppe hat die gleiche Breite von etwa 0,4487, aber jede Gruppe enthält nicht die gleiche Anzahl an Beobachtungen. Zum Beispiel:
- Der erste Abschnitt reicht von -2,3015387 bis -1,8528279 und enthält 3 Beobachtungen.
- Der zweite Abschnitt erstreckt sich von -1,8528279 bis -1,40411588 und enthält 1 Beobachtung.
- Der dritte Bereich reicht von -1,40411588 bis -0,95540447 und enthält 6 Beobachtungen.
Und so weiter.
Gleiche Frequenzgruppierung:
Um Buckets zu erstellen, die eine gleiche Anzahl an Beobachtungen enthalten, können wir die folgende Funktion verwenden:
#define function to calculate equal-frequency bins def equalObs(x, nbin): nlen = len(x) return np.interp(np.linspace(0, nlen, nbin + 1), np.arange(nlen), np.sort(x)) #create histogram with equal-frequency bins n, bins, patches = plt.hist(data, equalObs(data, 10), edgecolor='black') plt.show() #display bin boundaries and frequency per bin bins, n (array([-2.3015387 , -0.93576943, -0.67124613, -0.37528495, -0.20889423, 0.07734007, 0.2344157, 0.51292982, 0.86540763, 1.19891788, 2.18557541]), array([10., 10., 10., 10., 10., 10., 10., 10., 10., 10.]))
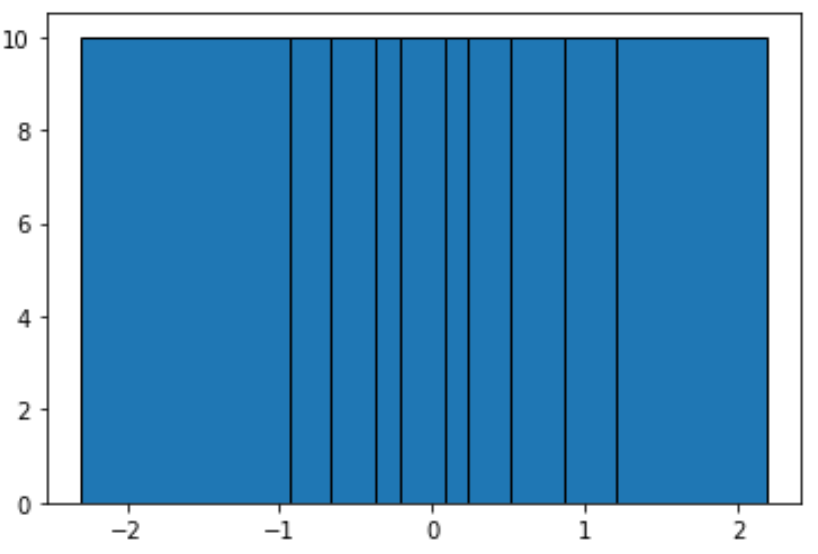
Jede Gruppe ist nicht gleich breit, aber jede Gruppe enthält die gleiche Anzahl an Beobachtungen. Zum Beispiel:
- Der erste Abschnitt erstreckt sich von -2,3015387 bis -0,93576943 und enthält 10 Beobachtungen.
- Der zweite Bereich reicht von -0,93576943 bis -0,67124613 und enthält 10 Beobachtungen.
- Der dritte Bereich reicht von -0,67124613 bis -0,37528495 und enthält 10 Beobachtungen.
Und so weiter.
Aus dem Histogramm können wir ersehen, dass jeder Abschnitt eindeutig nicht die gleiche Breite hat, aber jeder Abschnitt die gleiche Anzahl von Beobachtungen enthält, was durch die Tatsache bestätigt wird, dass die Höhe jedes Abschnitts gleich ist.
Über den Autor
Dr. Benjamin Anderson
Hallo, ich bin Benjamin, ein pensionierter Statistikprofessor, der sich zum engagierten Statorials-Lehrer entwickelt hat. Mit umfassender Erfahrung und Fachwissen auf dem Gebiet der Statistik bin ich bestrebt, mein Wissen zu teilen, um Studenten durch Statorials zu befähigen. Mehr wissen