Was sind hochdimensionale daten? (definition & beispiele)
Hochdimensionale Daten beziehen sich auf einen Datensatz, in dem die Anzahl der Merkmale p größer ist als die Anzahl der Beobachtungen N , oft geschrieben als p >> N.
Beispielsweise würde ein Datensatz mit p = 6 Merkmalen und nur N = 3 Beobachtungen als hochdimensionale Daten betrachtet, da die Anzahl der Merkmale größer ist als die Anzahl der Beobachtungen.
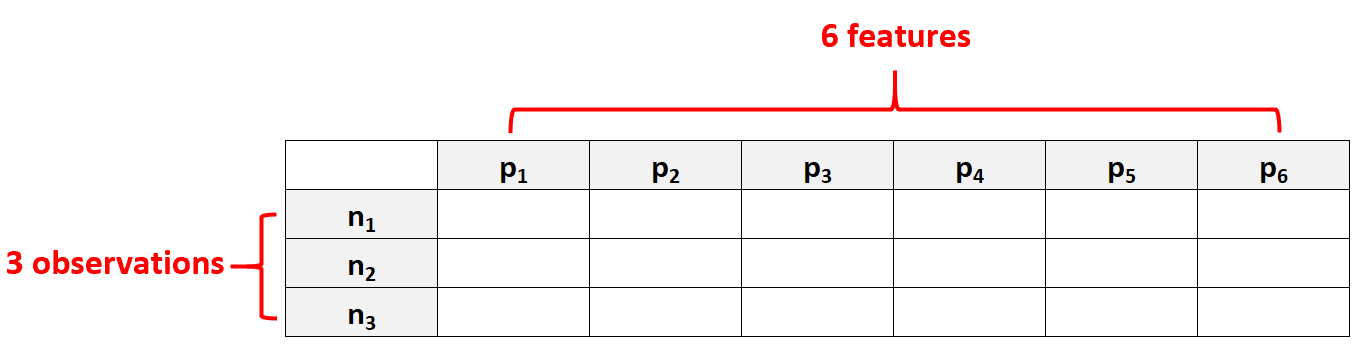
Ein häufiger Fehler besteht darin, anzunehmen, dass „hochdimensionale Daten“ einfach einen Datensatz mit vielen Funktionen bedeuten. Dies ist jedoch falsch. Ein Datensatz kann 10.000 Features enthalten, aber wenn er 100.000 Beobachtungen enthält, ist er nicht hochdimensional.
Hinweis: Eine ausführliche Diskussion der Mathematik hinter hochdimensionalen Daten finden Sie in Kapitel 18 von „Elemente des statistischen Lernens“ .
Warum sind hochdimensionale Daten ein Problem?
Wenn die Anzahl der Features in einem Datensatz die Anzahl der Beobachtungen übersteigt, erhalten wir nie eine deterministische Antwort.
Mit anderen Worten: Es wird unmöglich, ein Modell zu finden, das die Beziehung zwischen den Prädiktorvariablen und der Antwortvariablen beschreiben kann, da wir nicht über genügend Beobachtungen verfügen, anhand derer wir das Modell trainieren können.
Beispiele für hochdimensionale Daten
Die folgenden Beispiele veranschaulichen hochdimensionale Datensätze in verschiedenen Domänen.
Beispiel 1: Gesundheitsdaten
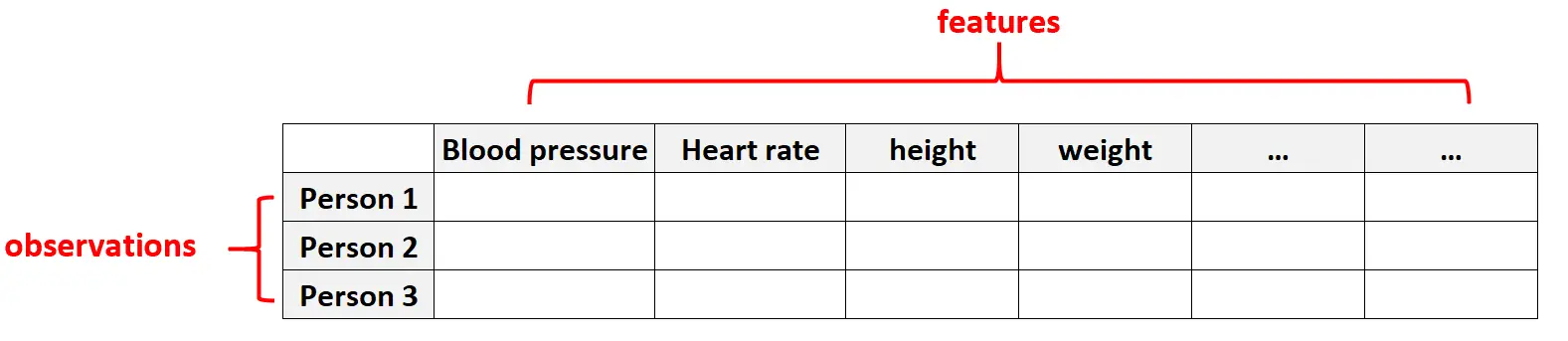
Hochdimensionale Daten sind in Gesundheitsdatensätzen üblich, in denen die Anzahl der Merkmale für eine bestimmte Person enorm sein kann (z. B. Blutdruck, Ruheherzfrequenz, Status des Immunsystems, chirurgische Vorgeschichte, Größe, Gewicht, bestehende Erkrankungen usw.).
In diesen Datensätzen ist es üblich, dass die Anzahl der Features größer ist als die Anzahl der Beobachtungen.
Beispiel 2: Finanzdaten
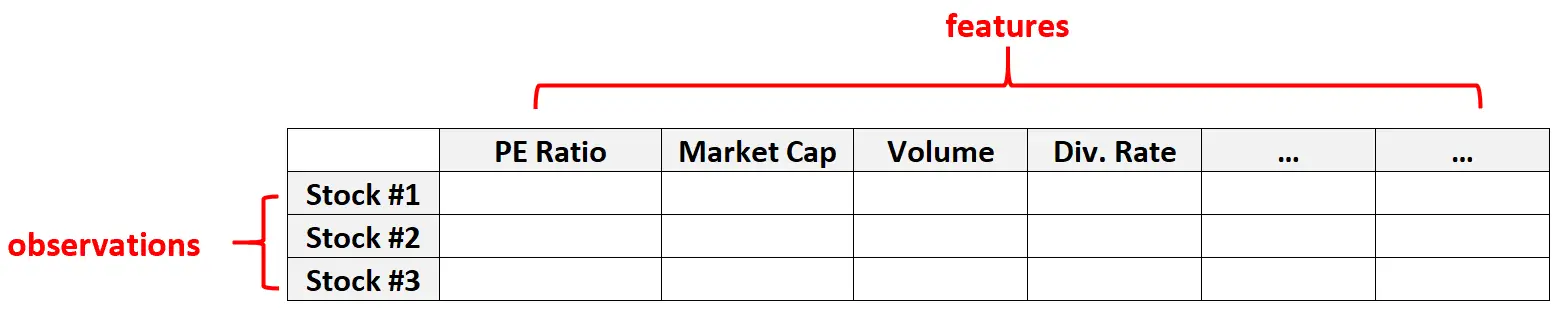
Hochdimensionale Daten sind auch in Finanzdatensätzen üblich, wo die Anzahl der Merkmale für eine bestimmte Aktie recht groß sein kann (z. B. KGV, Marktkapitalisierung, Handelsvolumen, Dividendensatz usw.).
Bei solchen Datensätzen ist es üblich, dass die Anzahl der Entitäten viel größer ist als die Anzahl der einzelnen Aktionen.
Beispiel 3: Genomik
Hochdimensionale Daten sind auch im Bereich der Genomik üblich, wo die Anzahl genetischer Merkmale eines bestimmten Individuums enorm sein kann.

Wie man mit großen Datenmengen umgeht
Es gibt zwei gängige Methoden zur Verarbeitung hochdimensionaler Daten:
1. Wählen Sie, ob Sie weniger Funktionen einschließen möchten.
Der offensichtlichste Weg, den Umgang mit hochdimensionalen Daten zu vermeiden, besteht darin, einfach weniger Features in den Datensatz aufzunehmen.
Es gibt mehrere Möglichkeiten zu entscheiden, welche Features aus einem Datensatz entfernt werden sollen, darunter:
- Entfernen Sie Features mit vielen fehlenden Werten: Wenn eine bestimmte Spalte in einem Datensatz viele fehlende Werte aufweist, können Sie sie möglicherweise vollständig entfernen, ohne viele Informationen zu verlieren.
- Merkmale mit geringer Varianz entfernen: Wenn eine bestimmte Spalte in einem Datensatz Werte aufweist, die sich nur sehr wenig ändern, können Sie sie möglicherweise entfernen, da sie wahrscheinlich nicht so viele nützliche Informationen über eine Antwortvariable bietet wie andere Merkmale.
- Entfernen Sie Features mit einer geringen Korrelation mit der Antwortvariablen: Wenn ein bestimmtes Feature nicht stark mit der gewünschten Antwortvariablen korreliert, können Sie es wahrscheinlich aus dem Datensatz entfernen, da es unwahrscheinlich ist, dass es sich um ein nützliches Feature in einem Modell handelt.
2. Verwenden Sie eine Regularisierungsmethode.
Eine andere Möglichkeit, hochdimensionale Daten zu verarbeiten, ohne Features aus dem Datensatz zu entfernen, ist die Verwendung einer Regularisierungstechnik wie:
Mit jeder dieser Techniken lassen sich hochdimensionale Daten effizient verarbeiten.
Eine vollständige Liste aller Tutorials zum statistischen maschinellen Lernen finden Sie auf dieser Seite .
Über den Autor
Dr. Benjamin Anderson
Hallo, ich bin Benjamin, ein pensionierter Statistikprofessor, der sich zum engagierten Statorials-Lehrer entwickelt hat. Mit umfassender Erfahrung und Fachwissen auf dem Gebiet der Statistik bin ich bestrebt, mein Wissen zu teilen, um Studenten durch Statorials zu befähigen. Mehr wissen