Vollständiger leitfaden: so interpretieren sie anova-ergebnisse in sas
Eine einfaktorielle ANOVA wird verwendet, um zu bestimmen, ob ein statistisch signifikanter Unterschied zwischen den Mittelwerten von drei oder mehr unabhängigen Gruppen besteht.
Das folgende Beispiel zeigt, wie die Ergebnisse einer einfaktoriellen ANOVA in SAS interpretiert werden.
Beispiel: Interpretation der ANOVA-Ergebnisse in SAS
Angenommen, ein Forscher rekrutiert 30 Studenten für die Teilnahme an einer Studie. Den Studierenden wird nach dem Zufallsprinzip eine von drei Lernmethoden zugewiesen , um sich auf eine Prüfung vorzubereiten.
Die Prüfungsergebnisse für jeden Studenten sind unten aufgeführt:
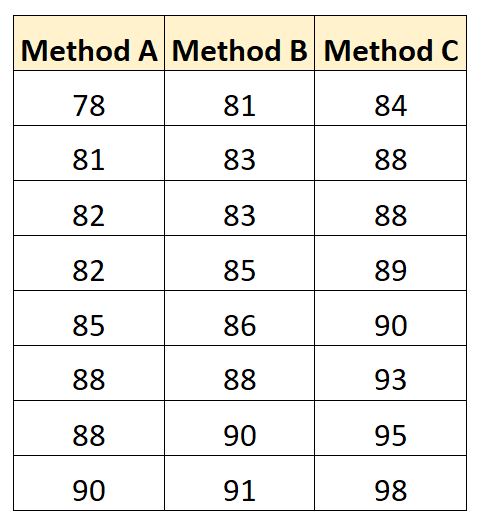
Wir können den folgenden Code verwenden, um diesen Datensatz in SAS zu erstellen:
/*create dataset*/
data my_data;
input Method $Score;
datalines ;
At 78
At 81
At 82
At 82
At 85
At 88
At 88
At 90
B 81
B 83
B 83
B85
B 86
B 88
B90
B91
C 84
C 88
C 88
C 89
C 90
C 93
C 95
C 98
;
run ;
Als nächstes verwenden wir proc ANOVA, um die einfaktorielle ANOVA durchzuführen:
/*perform one-way ANOVA*/
proc ANOVA data =my_data;
classMethod ;
modelScore = Method;
means Method / tukey cldiff ;
run ;
Hinweis : Wir haben die Mittelanweisung zusammen mit den Optionen tukey und cldiff verwendet, um anzugeben, dass ein Tukey-Post-hoc-Test (mit Konfidenzintervallen) durchgeführt werden soll, wenn der Gesamt-p-Wert der einfaktoriellen ANOVA statistisch signifikant ist.
Zuerst schauen wir uns die ANOVA-Tabelle im Ergebnis an:
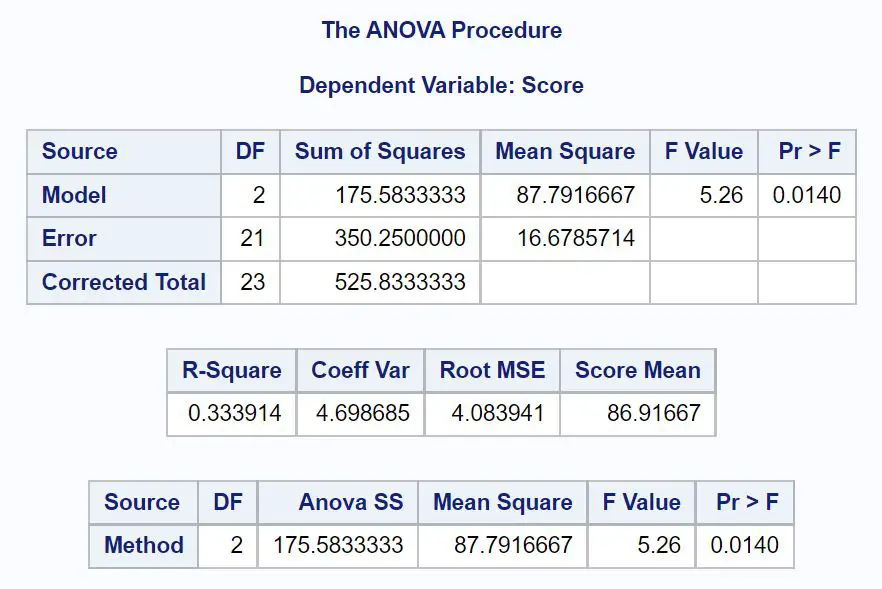
So interpretieren Sie jeden Wert in der Ausgabe:
DF-Modell: Die Freiheitsgrade für die Variablenmethode . Dies wird als #Gruppen -1 berechnet. In diesem Fall gab es drei verschiedene Untersuchungsmethoden, daher lautet dieser Wert: 3-1 = 2 .
DF-Fehler: die Freiheitsgrade für die Residuen. Dies wird als #Gesamtbeobachtungen – #Gruppen berechnet. In diesem Fall gab es 24 Beobachtungen und 3 Gruppen, daher ist dieser Wert: 24-3 = 21 .
Korrigierte Summe : die Summe des DF-Modells und des DF-Fehlers. Dieser Wert ist 2 + 21 = 23 .
Quadratsummenmodell: Die Summe der Quadrate, die mit der Variablenmethode verknüpft sind. Dieser Wert beträgt 175,583 .
Summe der Fehlerquadrate: Summe der mit Residuen oder „Fehlern“ verbundenen Quadrate. Dieser Wert beträgt 350,25 .
Korrigierte Summe der Quadrate insgesamt : Die Summe des SS-Modells und des SS-Fehlers. Dieser Wert beträgt 525,833 .
Modell der mittleren Quadrate: mittlere Summe der mit der Methode verbundenen Quadrate. Dies wird als SS-Modell / DF-Modell oder 175,583 / 2 = 87,79 berechnet.
Mittlerer quadratischer Fehler: mittlere Summe der mit den Residuen verbundenen Quadrate. Dies wird als SS-Fehler / DF-Fehler berechnet, was 350,25 / 21 = 16,68 beträgt.
F-Wert: Die Gesamt-F-Statistik des ANOVA-Modells. Dies wird als mittlerer quadratischer Modellfehler/mittlerer quadratischer Fehler oder 87,79/16,68 = 5,26 berechnet.
Pr >F: Der p-Wert, der der F-Statistik mit Zähler df = 2 und Nenner df = 21 zugeordnet ist. In diesem Fall beträgt der p-Wert 0,0140 .
Der wichtigste Wert in der Ergebnismenge ist der p-Wert, denn er sagt uns, ob es einen signifikanten Unterschied in den Mittelwerten zwischen den drei Gruppen gibt.
Denken Sie daran, dass eine einfaktorielle ANOVA die folgenden Null- und Alternativhypothesen verwendet:
- H 0 (Nullhypothese): Alle Gruppenmittelwerte sind gleich.
- H A (Alternativhypothese): Mindestens ein Gruppendurchschnitt unterscheidet sich von den anderen.
Da der p-Wert in unserer ANOVA-Tabelle (0,0140) kleiner als 0,05 ist, lehnen wir die Nullhypothese ab.
Das bedeutet, dass wir genügend Beweise dafür haben, dass die durchschnittliche Prüfungspunktzahl bei allen drei Studienmethoden nicht gleich ist.
Um genau zu bestimmen, welche Gruppenmittelwerte unterschiedlich sind, müssen wir uns auf die endgültige Ergebnistabelle beziehen, die die Ergebnisse der Post-hoc-Tests von Tukey zeigt:
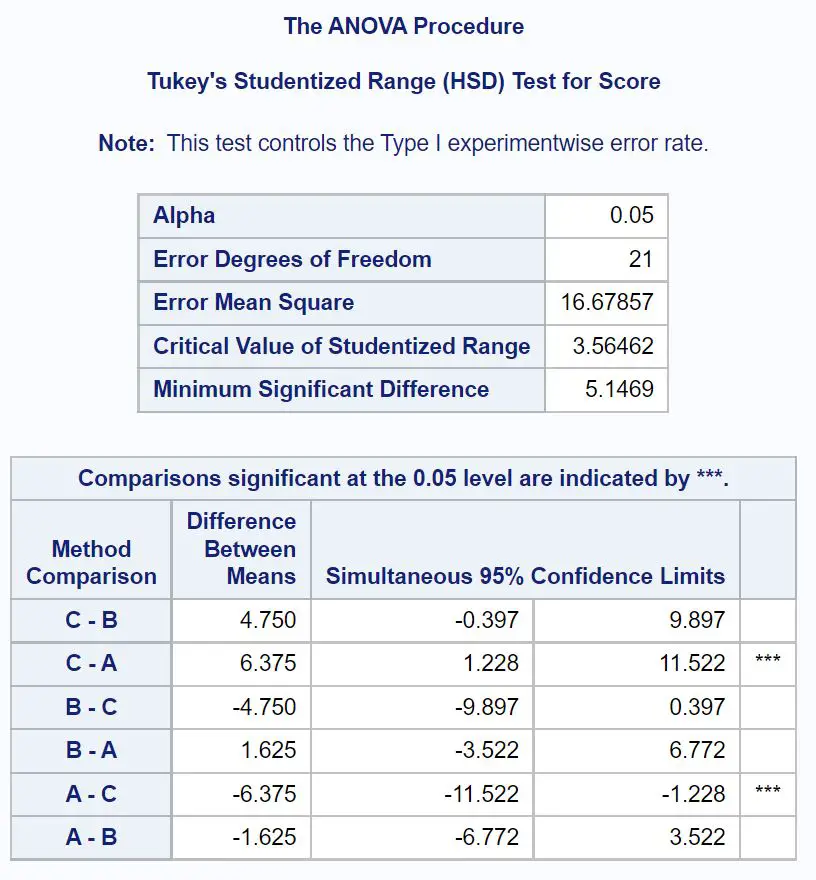
Um herauszufinden, welche Gruppenmittelwerte unterschiedlich sind, müssen wir uns ansehen, bei welchen paarweisen Vergleichen Sterne ( *** ) neben ihnen stehen.
Die Tabelle zeigt, dass es einen statistisch signifikanten Unterschied in den durchschnittlichen Prüfungsergebnissen zwischen Gruppe A und Gruppe C gibt.
Konkret beträgt der durchschnittliche Unterschied in den Prüfungsergebnissen zwischen Gruppe C und Gruppe A 6,375 .
Das 95 %-Konfidenzintervall für die mittlere Differenz beträgt [1,228, 11,522] .
Es gibt keine statistisch signifikanten Unterschiede zwischen den Mittelwerten der anderen Gruppen.
Zusätzliche Ressourcen
Die folgenden Tutorials bieten zusätzliche Informationen zu ANOVA-Modellen:
Ein Leitfaden zur Verwendung von Post-Hoc-Tests mit ANOVA
So führen Sie eine einfaktorielle ANOVA in SAS durch
So führen Sie eine zweifaktorielle ANOVA in SAS durch
Über den Autor
Dr. Benjamin Anderson
Hallo, ich bin Benjamin, ein pensionierter Statistikprofessor, der sich zum engagierten Statorials-Lehrer entwickelt hat. Mit umfassender Erfahrung und Fachwissen auf dem Gebiet der Statistik bin ich bestrebt, mein Wissen zu teilen, um Studenten durch Statorials zu befähigen. Mehr wissen