Eine vollständige anleitung zum iris-datensatz in r
Der Iris- Datensatz ist ein integrierter Datensatz in R, der Messungen zu 4 verschiedenen Attributen (in Zentimetern) für 50 Blüten von 3 verschiedenen Arten enthält.
In diesem Tutorial wird am Beispiel des Iris-Datensatzes erläutert, wie ein Datensatz in R untersucht und zusammengefasst wird.
Verwandt: Eine vollständige Anleitung zum mtcars-Datensatz in R
Iris-Datensatz laden
Da es sich bei dem Iris-Datensatz um einen in R integrierten Datensatz handelt, können wir ihn mit dem folgenden Befehl laden:
data(iris)
Mit der Funktion head() können wir uns die ersten sechs Zeilen des Datensatzes ansehen:
#view first six rows of iris dataset
head(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
Fassen Sie den Iris-Datensatz zusammen
Mit der Funktion summary() können wir jede Variable im Datensatz schnell zusammenfassen:
#summarize iris dataset
summary(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width
Min. :4,300 Min. :2,000 Min. :1,000 Min. :0.100
1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600 1st Qu.:0.300
Median: 5,800 Median: 3,000 Median: 4,350 Median: 1,300
Mean:5.843 Mean:3.057 Mean:3.758 Mean:1.199
3rd Qu.:6,400 3rd Qu.:3,300 3rd Qu.:5,100 3rd Qu.:1,800
Max. :7,900 Max. :4,400 Max. :6,900 Max. :2,500
Species
setosa:50
versicolor:50
virginica :50
Für jede der numerischen Variablen können wir die folgenden Informationen sehen:
- Min : Der Mindestwert.
- 1. Qu : Der Wert des ersten Quartils (25. Perzentil).
- Median : Der Medianwert.
- Durchschnitt : Der Durchschnittswert.
- 3. Qu : Der Wert des dritten Quartils (75. Perzentil).
- Max : Der Maximalwert.
Für die einzige kategoriale Variable im Datensatz (Art) sehen wir eine Häufigkeitszählung für jeden Wert:
- setosa : Diese Art kommt 50 Mal vor.
- versicolor : Diese Art kommt 50 Mal vor.
- virginica : Diese Art kommt 50 Mal vor.
Mit der Funktion dim() können wir die Dimensionen des Datensatzes in Bezug auf die Anzahl der Zeilen und Spalten ermitteln:
#display rows and columns
dim(iris)
[1] 150 5
Wir können sehen, dass der Datensatz 150 Zeilen und 5 Spalten hat.
Wir können auch die Funktion „names()“ verwenden, um die Spaltennamen des Datenrahmens anzuzeigen:
#display column names
names(iris)
[1] "Sepal.Length" "Sepal.Width" "Petal.Length" "Petal.Width" "Species"
Visualisieren Sie den Iris-Datensatz
Wir können auch Diagramme erstellen, um die Werte des Datensatzes zu visualisieren.
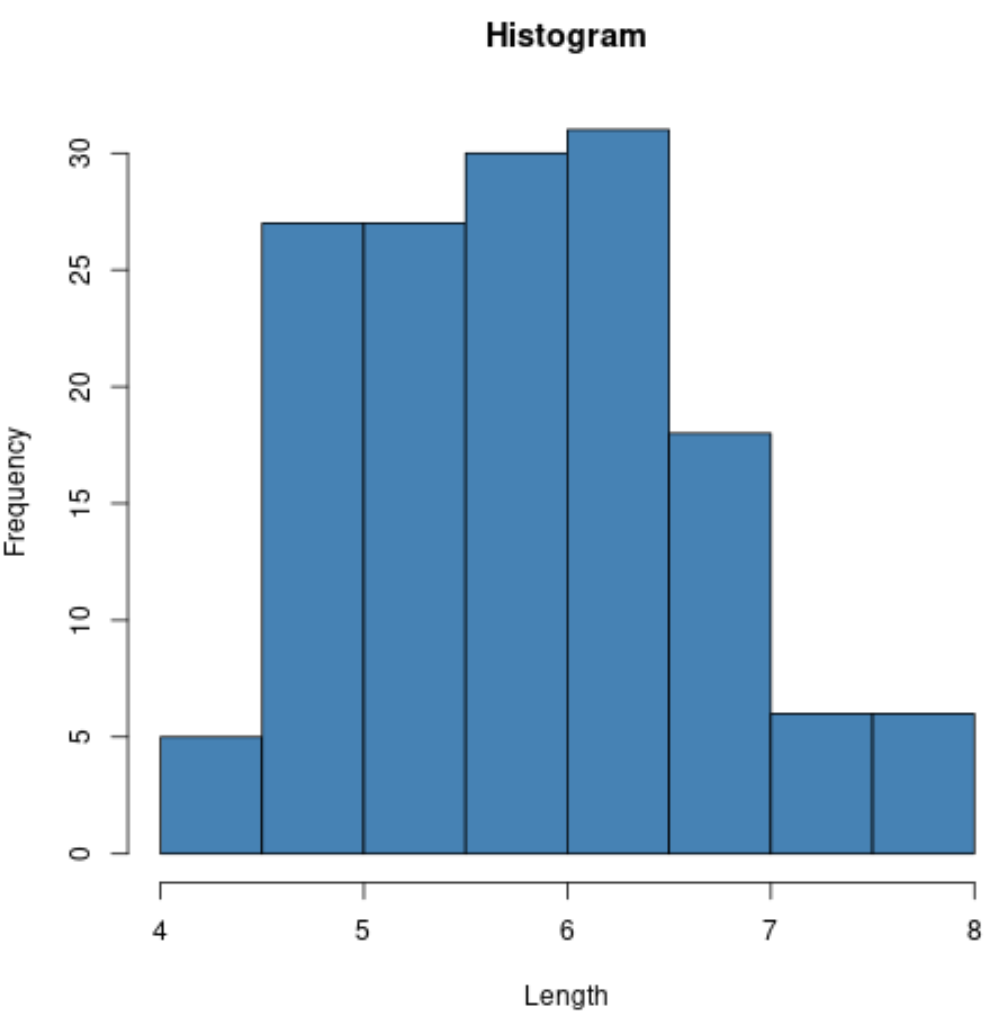
Beispielsweise können wir mit der Funktion hist() ein Histogramm der Werte einer bestimmten Variablen erstellen:
#create histogram of values for sepal length
hist(iris$Sepal.Length,
col=' steelblue ',
main=' Histogram ',
xlab=' Length ',
ylab=' Frequency ')
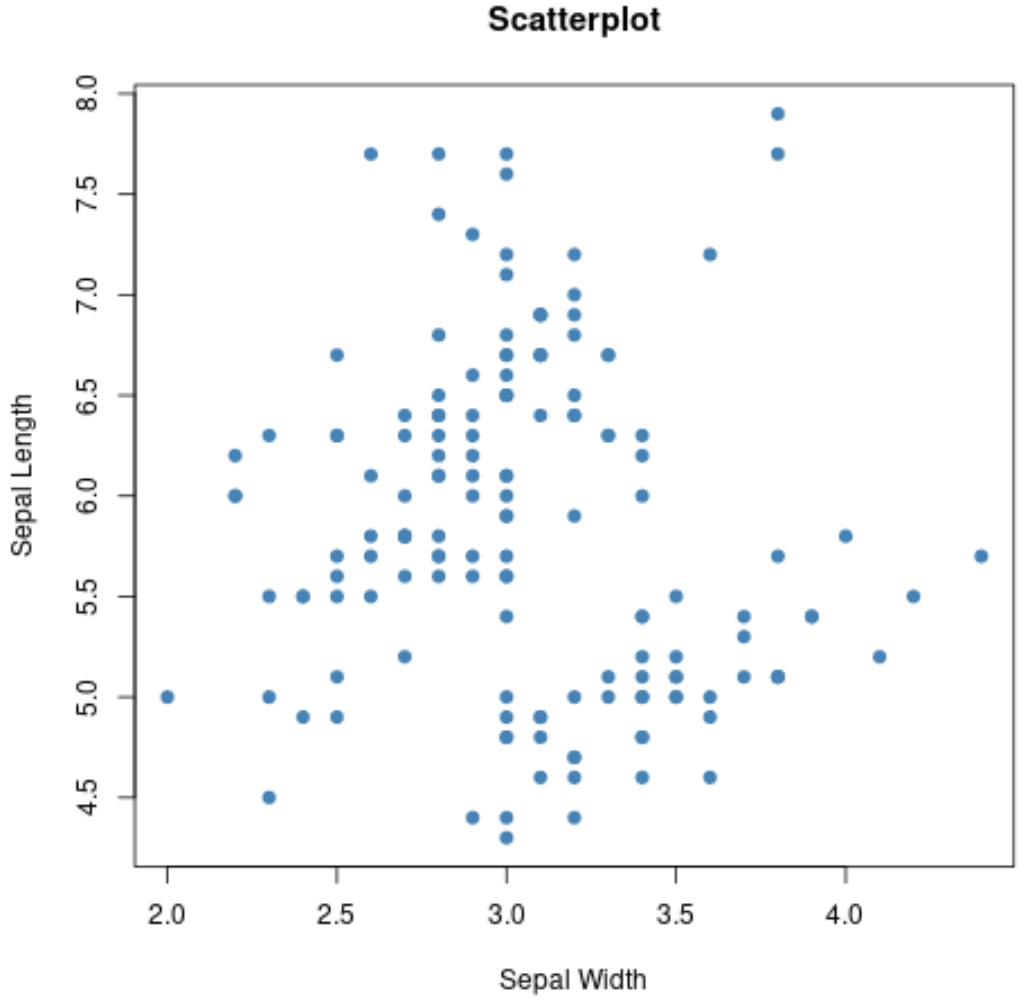
Wir können auch die Funktion plot() verwenden, um ein Streudiagramm einer beliebigen paarweisen Kombination von Variablen zu erstellen:
#create scatterplot of sepal width vs. sepal length
plot(iris$Sepal.Width, iris$Sepal.Length,
col=' steelblue ',
main=' Scatterplot ',
xlab=' Sepal Width ',
ylab=' Sepal Length ',
pch= 19 )
Wir können auch die Funktion boxplot() verwenden, um einen Boxplot pro Gruppe zu erstellen:
#create scatterplot of sepal width vs. sepal length
boxplot(Sepal.Length~Species,
data=iris,
main=' Sepal Length by Species ',
xlab=' Species ',
ylab=' Sepal Length ',
col=' steelblue ',
border=' black ')
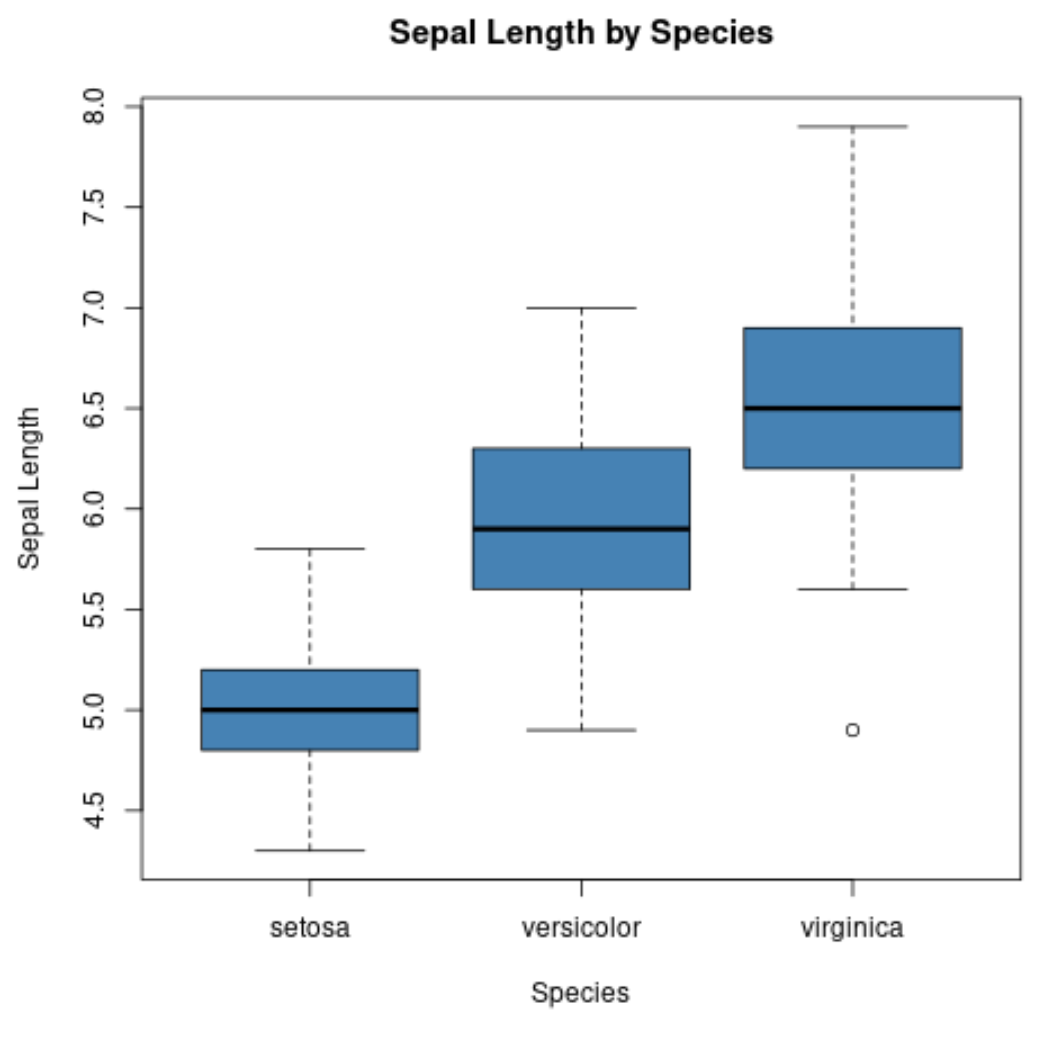
Die x-Achse zeigt die drei Arten und die y-Achse zeigt die Verteilung der Kelchblattlängenwerte für jede Art.
Bei dieser Art von Darstellung können wir schnell erkennen, dass die Länge der Kelchblätter bei der Virginia-Art tendenziell am größten und bei der Setosa-Art am kleinsten ist.
Zusätzliche Ressourcen
Die folgenden Tutorials erklären ausführlicher, wie man Datensätze in R zusammenfasst:
Der einfachste Weg, Übersichtstabellen in R zu erstellen
So berechnen Sie die Zusammenfassung von fünf Zahlen in R
Über den Autor
Dr. Benjamin Anderson
Hallo, ich bin Benjamin, ein pensionierter Statistikprofessor, der sich zum engagierten Statorials-Lehrer entwickelt hat. Mit umfassender Erfahrung und Fachwissen auf dem Gebiet der Statistik bin ich bestrebt, mein Wissen zu teilen, um Studenten durch Statorials zu befähigen. Mehr wissen