Die fünf annahmen der multiplen linearen regression
Die multiple lineare Regression ist eine statistische Methode, mit der wir die Beziehung zwischen mehreren Prädiktorvariablen und einer Antwortvariablen verstehen können.
Bevor wir jedoch eine multiple lineare Regression durchführen, müssen wir zunächst sicherstellen, dass fünf Annahmen erfüllt sind:
1. Lineare Beziehung: Es besteht eine lineare Beziehung zwischen jeder Prädiktorvariablen und der Antwortvariablen.
2. Keine Multikollinearität: Keine der Prädiktorvariablen korreliert stark miteinander.
3. Unabhängigkeit: Die Beobachtungen sind unabhängig.
4. Homoskedastizität: Die Residuen haben an jedem Punkt des linearen Modells eine konstante Varianz.
5. Multivariate Normalität: Die Modellresiduen sind normalverteilt.
Wenn eine oder mehrere dieser Annahmen nicht erfüllt sind, sind die Ergebnisse der multiplen linearen Regression möglicherweise nicht zuverlässig.
In diesem Artikel geben wir eine Erklärung für jede Annahme, wie Sie feststellen können, ob die Annahme erfüllt ist, und was zu tun ist, wenn die Annahme nicht erfüllt ist.
Hypothese 1: Lineare Beziehung
Bei der multiplen linearen Regression wird davon ausgegangen, dass zwischen jeder Prädiktorvariablen und der Antwortvariablen eine lineare Beziehung besteht.
So ermitteln Sie, ob diese Annahme erfüllt ist
Der einfachste Weg, um festzustellen, ob diese Annahme erfüllt ist, besteht darin, ein Streudiagramm jeder Prädiktorvariablen und der Antwortvariablen zu erstellen.
Dadurch können Sie visuell erkennen, ob zwischen den beiden Variablen ein linearer Zusammenhang besteht.
Wenn die Punkte im Streudiagramm ungefähr auf einer geraden diagonalen Linie liegen, besteht wahrscheinlich eine lineare Beziehung zwischen den Variablen.
Beispielsweise scheinen die Punkte in der folgenden Grafik auf einer geraden Linie zu liegen, was darauf hindeutet, dass zwischen dieser bestimmten Prädiktorvariablen (x) und der Antwortvariablen (y) eine lineare Beziehung besteht:
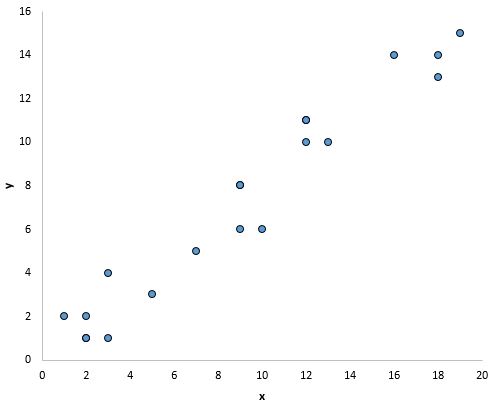
Was tun, wenn diese Annahme nicht respektiert wird?
Wenn zwischen einer oder mehreren Prädiktorvariablen und der Antwortvariablen kein linearer Zusammenhang besteht, haben wir mehrere Möglichkeiten:
1. Wenden Sie eine nichtlineare Transformation auf die Prädiktorvariable an, indem Sie beispielsweise den Logarithmus oder die Quadratwurzel ziehen. Dadurch kann die Beziehung oft linearer werden.
2. Fügen Sie dem Modell eine weitere Prädiktorvariable hinzu. Wenn beispielsweise das Diagramm von x vs. y eine parabolische Form hat, kann es sinnvoll sein, X 2 als zusätzliche Prädiktorvariable in das Modell aufzunehmen.
3. Entfernen Sie die Prädiktorvariable aus dem Modell. Im extremsten Fall, wenn keine lineare Beziehung zwischen einer bestimmten Prädiktorvariablen und der Antwortvariablen besteht, ist es möglicherweise nicht sinnvoll, die Prädiktorvariable in das Modell einzubeziehen.
Hypothese 2: keine Multikollinearität
Bei der multiplen linearen Regression wird davon ausgegangen, dass keine der Prädiktorvariablen stark miteinander korreliert ist.
Wenn eine oder mehrere Prädiktorvariablen stark korrelieren, leidet das Regressionsmodell unter Multikollinearität , wodurch die Koeffizientenschätzungen des Modells unzuverlässig werden.
So ermitteln Sie, ob diese Annahme erfüllt ist
Der einfachste Weg, um festzustellen, ob diese Annahme erfüllt ist, besteht darin, den VIF-Wert für jede Prädiktorvariable zu berechnen.
VIF-Werte beginnen bei 1 und haben keine Obergrenze. Im Allgemeinen weisen VIF-Werte über 5* auf eine mögliche Multikollinearität hin.
Die folgenden Tutorials zeigen, wie man den VIF in verschiedenen Statistikprogrammen berechnet:
*Je nach Fachgebiet verwenden Forscher manchmal stattdessen einen VIF-Wert von 10.
Was tun, wenn diese Annahme nicht respektiert wird?
Wenn eine oder mehrere Prädiktorvariablen einen VIF-Wert größer als 5 haben, lässt sich dieses Problem am einfachsten beheben, indem man einfach die Prädiktorvariablen mit den hohen VIF-Werten entfernt.
Wenn Sie alternativ jede Prädiktorvariable im Modell behalten möchten, können Sie eine andere statistische Methode verwenden, z. B. die Ridge-Regression , die Lasso-Regression oder die partielle Regression der kleinsten Quadrate , die für die Verarbeitung stark korrelierter Prädiktorvariablen entwickelt wurde.
Hypothese 3: Unabhängigkeit
Bei der multiplen linearen Regression wird davon ausgegangen, dass jede Beobachtung im Datensatz unabhängig ist.
So ermitteln Sie, ob diese Annahme erfüllt ist
Der einfachste Weg, um festzustellen, ob diese Annahme erfüllt ist, ist die Durchführung eines Durbin-Watson-Tests , einem formalen statistischen Test, der uns sagt, ob die Residuen (und damit die Beobachtungen) eine Autokorrelation aufweisen oder nicht.
Was tun, wenn diese Annahme nicht respektiert wird?
Je nachdem, wie diese Annahme verletzt wird, haben Sie mehrere Möglichkeiten:
- Für eine positive serielle Korrelation sollten Sie erwägen, dem Modell Verzögerungen der abhängigen und/oder unabhängigen Variablen hinzuzufügen.
- Stellen Sie bei negativer serieller Korrelation sicher, dass keine Ihrer Variablen übermäßig verzögert ist.
- Für die saisonale Korrelation sollten Sie erwägen, dem Modell saisonale Dummies hinzuzufügen.
Hypothese 4: Homoskedastizität
Bei der multiplen linearen Regression wird davon ausgegangen, dass die Residuen an jedem Punkt im linearen Modell eine konstante Varianz aufweisen. Wenn dies nicht der Fall ist, leiden die Residuen unter Heteroskedastizität .
Wenn in einer Regressionsanalyse Heteroskedastizität vorliegt, werden die Ergebnisse des Regressionsmodells unzuverlässig.
Insbesondere erhöht Heteroskedastizität die Varianz der Regressionskoeffizientenschätzungen, das Regressionsmodell berücksichtigt dies jedoch nicht. Dies macht es viel wahrscheinlicher, dass ein Regressionsmodell behauptet, ein Term im Modell sei statistisch signifikant, obwohl dies in Wirklichkeit nicht der Fall ist.
So ermitteln Sie, ob diese Annahme erfüllt ist
Der einfachste Weg, um festzustellen, ob diese Annahme erfüllt ist, besteht darin, ein Diagramm der standardisierten Residuen gegenüber den vorhergesagten Werten zu erstellen.
Sobald Sie ein Regressionsmodell an einen Datensatz angepasst haben, können Sie ein Streudiagramm erstellen, das die vorhergesagten Werte der Antwortvariablen auf der x-Achse und die standardisierten Residuen des Modells auf der x-Achse anzeigt. j.
Wenn die Punkte im Streudiagramm einen Trend aufweisen, liegt Heteroskedastizität vor.
Das folgende Diagramm zeigt ein Beispiel für ein Regressionsmodell, bei dem Heteroskedastizität kein Problem darstellt:
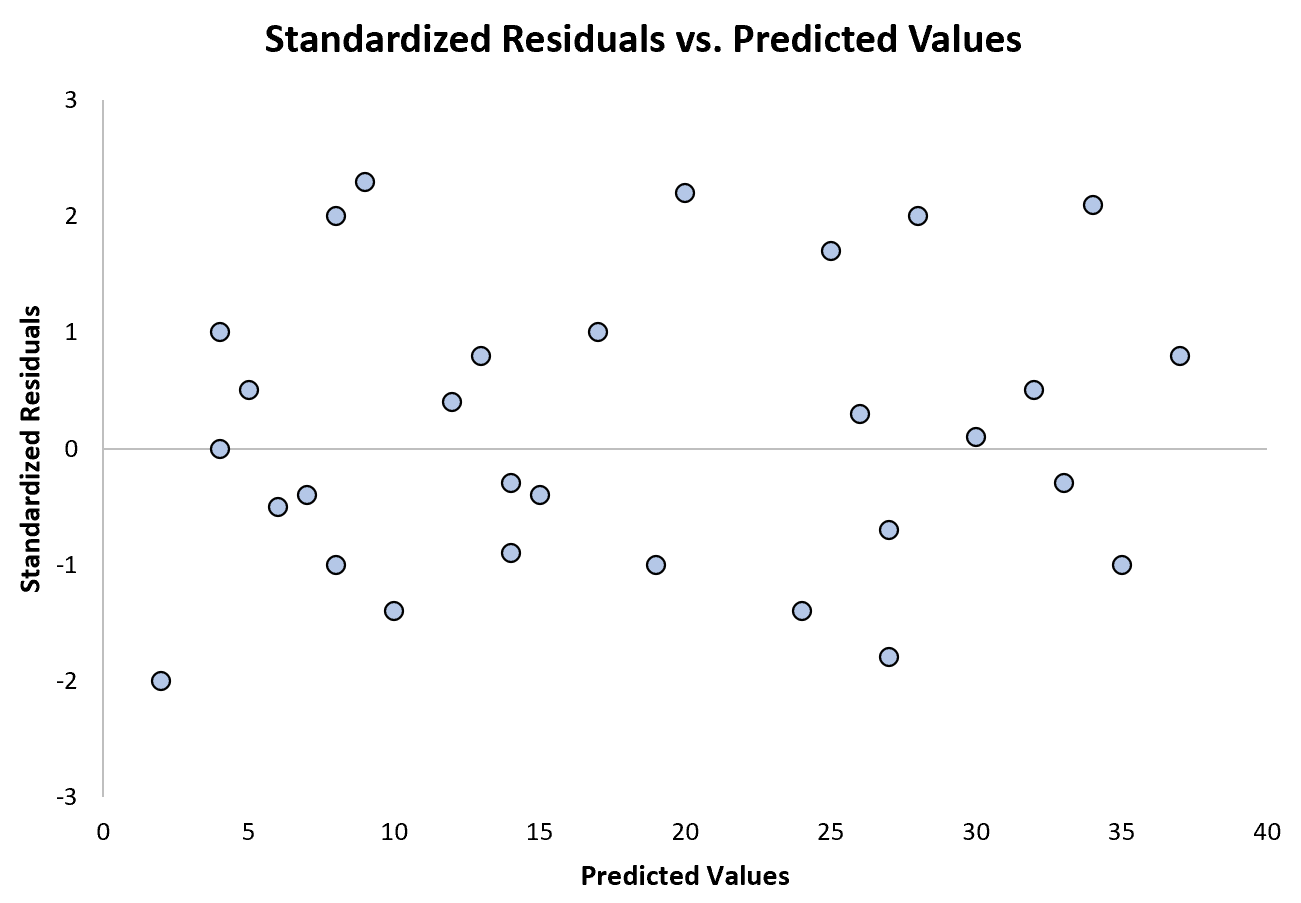
Beachten Sie, dass die standardisierten Residuen ohne klares Muster um Null herum verstreut sind.
Das folgende Diagramm zeigt ein Beispiel für ein Regressionsmodell, bei dem Heteroskedastizität ein Problem darstellt :
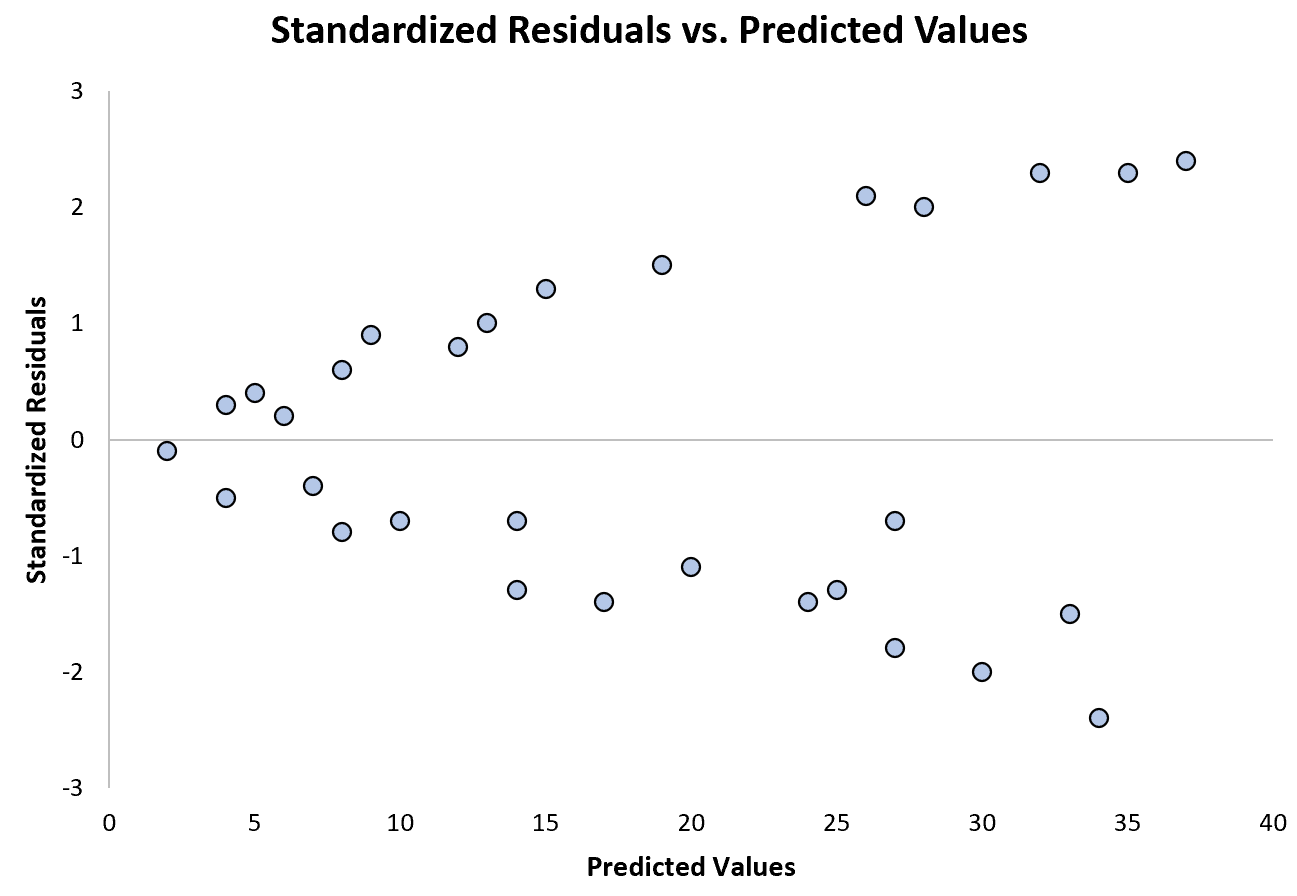
Beachten Sie, wie sich die standardisierten Residuen mit zunehmenden vorhergesagten Werten immer weiter ausbreiten. Diese „Kegelform“ ist ein klassisches Zeichen der Heteroskedastizität:
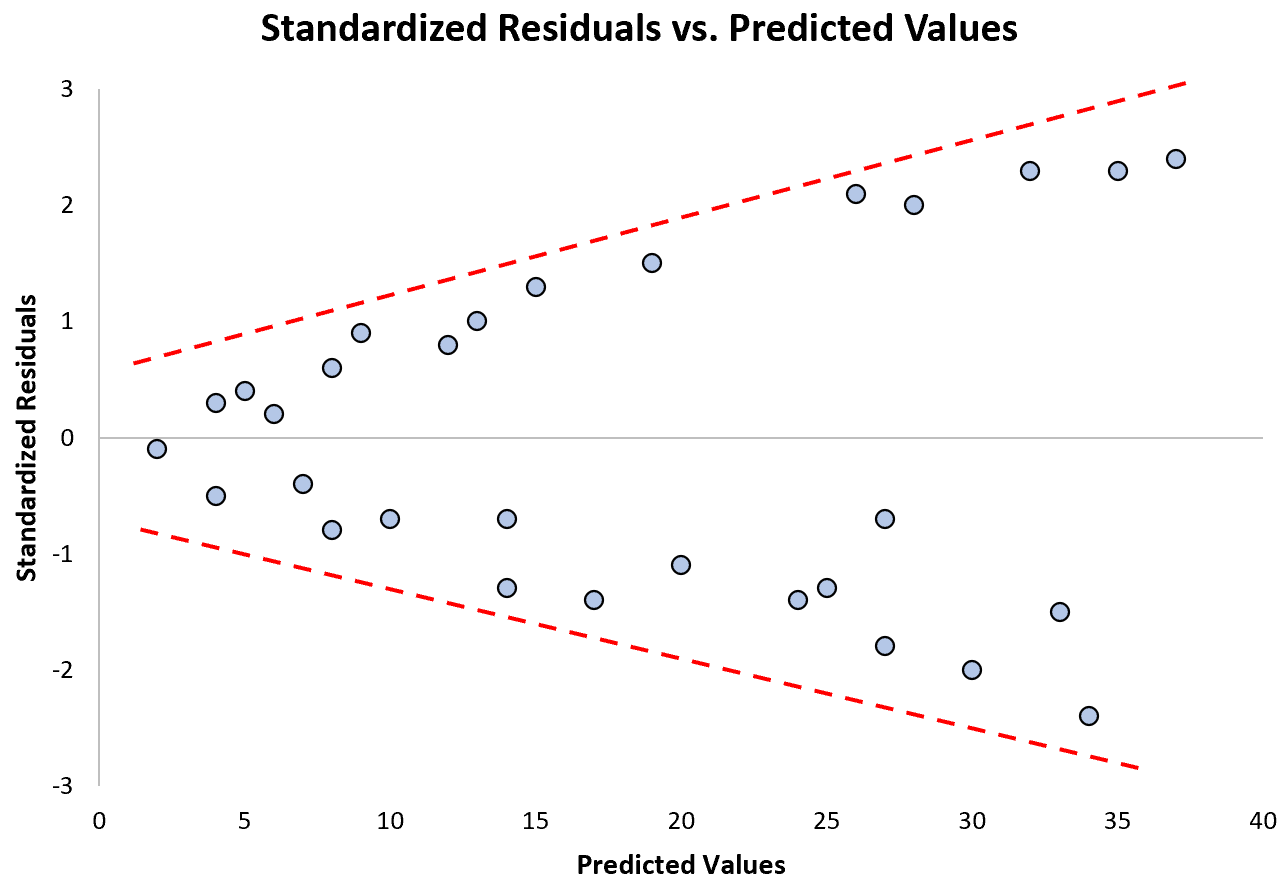
Was tun, wenn diese Annahme nicht respektiert wird?
Es gibt drei gängige Methoden zur Korrektur von Heteroskedastizität:
1. Transformieren Sie die Antwortvariable. Der gebräuchlichste Weg, mit Heteroskedastizität umzugehen, besteht darin, die Antwortvariable zu transformieren, indem der Logarithmus, die Quadratwurzel oder die Kubikwurzel aller Werte der Antwortvariablen gezogen wird. Dies führt häufig zum Verschwinden der Heteroskedastizität.
2. Definieren Sie die Antwortvariable neu. Eine Möglichkeit, die Antwortvariable neu zu definieren, besteht darin, eine Rate anstelle des Rohwerts zu verwenden. Anstatt beispielsweise die Bevölkerungsgröße zu verwenden, um die Anzahl der Floristen in einer Stadt vorherzusagen, können wir die Bevölkerungsgröße verwenden, um die Anzahl der Floristen pro Kopf vorherzusagen.
In den meisten Fällen verringert sich dadurch die Variabilität, die natürlicherweise in größeren Populationen auftritt, da wir die Anzahl der Floristen pro Person messen und nicht die Anzahl der Floristen selbst.
3. Verwenden Sie eine gewichtete Regression. Eine andere Möglichkeit zur Korrektur der Heteroskedastizität besteht in der Verwendung einer gewichteten Regression, die jedem Datenpunkt basierend auf der Varianz seines angepassten Werts eine Gewichtung zuweist.
Im Wesentlichen werden dadurch Datenpunkte mit höheren Varianzen niedrig gewichtet, wodurch ihre Restquadrate reduziert werden. Wenn die entsprechenden Gewichte verwendet werden, kann das Problem der Heteroskedastizität beseitigt werden.
Verwandte Themen : So führen Sie eine gewichtete Regression in R durch
Annahme 4: Multivariate Normalität
Bei der multiplen linearen Regression wird davon ausgegangen, dass die Modellresiduen normalverteilt sind.
So ermitteln Sie, ob diese Annahme erfüllt ist
Es gibt zwei gängige Methoden, um zu überprüfen, ob diese Annahme erfüllt ist:
1. Überprüfen Sie die Hypothese visuell mithilfe von QQ-Plots .
Ein QQ-Diagramm, kurz für Quantil-Quantil-Diagramm, ist eine Art Diagramm, mit dem wir bestimmen können, ob die Residuen eines Modells einer Normalverteilung folgen oder nicht. Wenn die Punkte auf dem Diagramm ungefähr eine gerade diagonale Linie bilden, ist die Normalitätsannahme erfüllt.
Das folgende QQ-Diagramm zeigt ein Beispiel für Residuen, die ungefähr einer Normalverteilung folgen:
Das folgende QQ-Diagramm zeigt jedoch ein Beispiel für einen Fall, in dem die Residuen deutlich von einer geraden diagonalen Linie abweichen, was darauf hindeutet, dass sie nicht der Normalverteilung folgen:
2. Überprüfen Sie die Hypothese mithilfe eines formalen statistischen Tests wie Shapiro-Wilk, Kolmogorov-Smironov, Jarque-Barre oder D’Agostino-Pearson.
Bedenken Sie, dass diese Tests empfindlich auf große Stichprobengrößen reagieren – das heißt, sie kommen häufig zu dem Schluss, dass die Residuen nicht normal sind, wenn die Stichprobengröße extrem groß ist. Aus diesem Grund ist es oft einfacher, grafische Methoden wie einen QQ-Plot zu verwenden, um diese Hypothese zu überprüfen.
Was tun, wenn diese Annahme nicht respektiert wird?
Wenn die Normalitätsannahme nicht erfüllt ist, haben Sie mehrere Möglichkeiten:
1. Überprüfen Sie zunächst, ob in den Daten keine extremen Ausreißer vorhanden sind, die zu einer Verletzung der Normalitätsannahme führen.
2. Anschließend können Sie eine nichtlineare Transformation auf die Antwortvariable anwenden, indem Sie beispielsweise die Quadratwurzel, den Logarithmus oder die Kubikwurzel aller Werte der Antwortvariablen ziehen. Dies führt häufig zu einer normaleren Verteilung der Modellresiduen.
Zusätzliche Ressourcen
Die folgenden Tutorials bieten zusätzliche Informationen zur multiplen linearen Regression und ihren Annahmen:
Einführung in die multiple lineare Regression
Ein Leitfaden zur Heteroskedastizität in der Regressionsanalyse
Ein Leitfaden zu Multikollinearität und VIF in der Regression
Die folgenden Tutorials bieten Schritt-für-Schritt-Beispiele zur Durchführung einer multiplen linearen Regression mit unterschiedlicher Statistiksoftware:
So führen Sie eine multiple lineare Regression in Excel durch
So führen Sie eine multiple lineare Regression in R durch
So führen Sie eine multiple lineare Regression in SPSS durch
So führen Sie eine multiple lineare Regression in Stata durch
Über den Autor
Dr. Benjamin Anderson
Hallo, ich bin Benjamin, ein pensionierter Statistikprofessor, der sich zum engagierten Statorials-Lehrer entwickelt hat. Mit umfassender Erfahrung und Fachwissen auf dem Gebiet der Statistik bin ich bestrebt, mein Wissen zu teilen, um Studenten durch Statorials zu befähigen. Mehr wissen