Nicht gruppierte häufigkeitsverteilung: definition und beispiel
Angenommen, wir führen eine Umfrage durch, bei der wir 15 Haushalte fragen, wie viele Tiere sie in ihrem Haus haben. Die Ergebnisse sind wie folgt:
1, 1, 1, 1, 2, 2, 2, 3, 3, 4, 5, 5, 6, 7, 8
Eine Möglichkeit, diese Ergebnisse zusammenzufassen, besteht darin, eine Häufigkeitsverteilung zu erstellen, die uns sagt, wie oft verschiedene Werte in einem Datensatz vorkommen.
Wir verwenden häufig geclusterte Häufigkeitsverteilungen , bei denen wir Wertegruppen erstellen und dann die Anzahl der Beobachtungen in einem Datensatz zusammenfassen, die in diese Gruppen fallen.
Hier ist ein Beispiel einer gruppierten Häufigkeitsverteilung für unsere Umfragedaten:
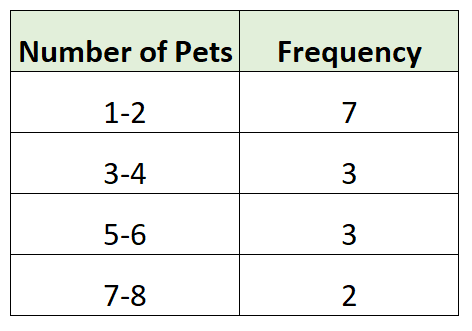
Wir haben zunächst Gruppen der Größe 2 erstellt und dann die Anzahl der Einzelbeobachtungen aus dem Datensatz gezählt, die in jede Gruppe fallen. Zum Beispiel:
- 7 Familien hatten 1 oder 2 Tiere
- 3 Familien hatten 3 oder 4 Tiere
- 3 Familien hatten 5 oder 6 Tiere
- 2 Familien hatten 7 oder 8 Tiere
Eine andere Art von Häufigkeitsverteilung, die wir erstellen könnten, ist eine nicht gruppierte Häufigkeitsverteilung , die die Häufigkeit jedes einzelnen Datenwerts anstelle von Gruppen von Datenwerten anzeigt.
Hier ist ein Beispiel einer nicht gruppierten Häufigkeitsverteilung für unsere Umfragedaten:
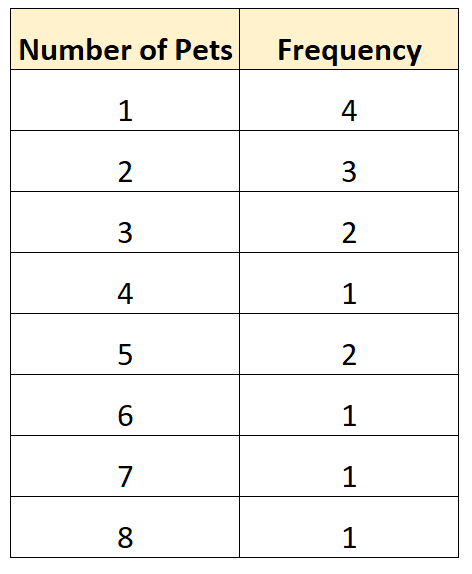
Durch diese Art der Häufigkeitsverteilung können wir direkt erkennen, wie oft unterschiedliche Werte in unserem Datensatz vorkamen. Zum Beispiel:
- 4 Familien hatten 1 Tier
- 3 Familien hatten 2 Tiere
- 2 Familien hatten 3 Tiere
- 1 Familie hatte 4 Tiere
Und so weiter.
Wann sollten nicht gruppierte Häufigkeitsverteilungen verwendet werden?
Nicht gruppierte Häufigkeitsverteilungen können nützlich sein, wenn Sie sehen möchten, wie oft jeder einzelne Wert in einem Datensatz vorkommt.
Beachten Sie, dass nicht gruppierte Häufigkeitsverteilungen am besten bei kleinen Datensätzen funktionieren, in denen es nur wenige eindeutige Werte gibt.
In unseren vorherigen Umfragedaten gab es beispielsweise nur 8 eindeutige Werte, daher war es sinnvoll, eine nicht gruppierte Häufigkeitsverteilung zu erstellen.
Wenn wir jedoch einen Datensatz aus Tausenden hätten, der Hunderte oder einzelne Werte enthält, wäre eine nicht gruppierte Häufigkeitsverteilung unglaublich zeitaufwändig und es wäre schwierig, daraus Informationen zu gewinnen.
Bei größeren Datensätzen ist es sinnvoll, gruppierte Häufigkeitsverteilungen zu erstellen.
So visualisieren Sie nicht gruppierte Häufigkeitsverteilungen
Die einfachste Möglichkeit, die Werte in einer nicht gruppierten Häufigkeitsverteilung zu visualisieren, besteht darin, ein Häufigkeitspolygon zu erstellen, das die Häufigkeiten jedes einzelnen Werts in einem einfachen Diagramm anzeigt.
So würde ein Häufigkeitspolygon für unsere Beispieldaten aussehen:
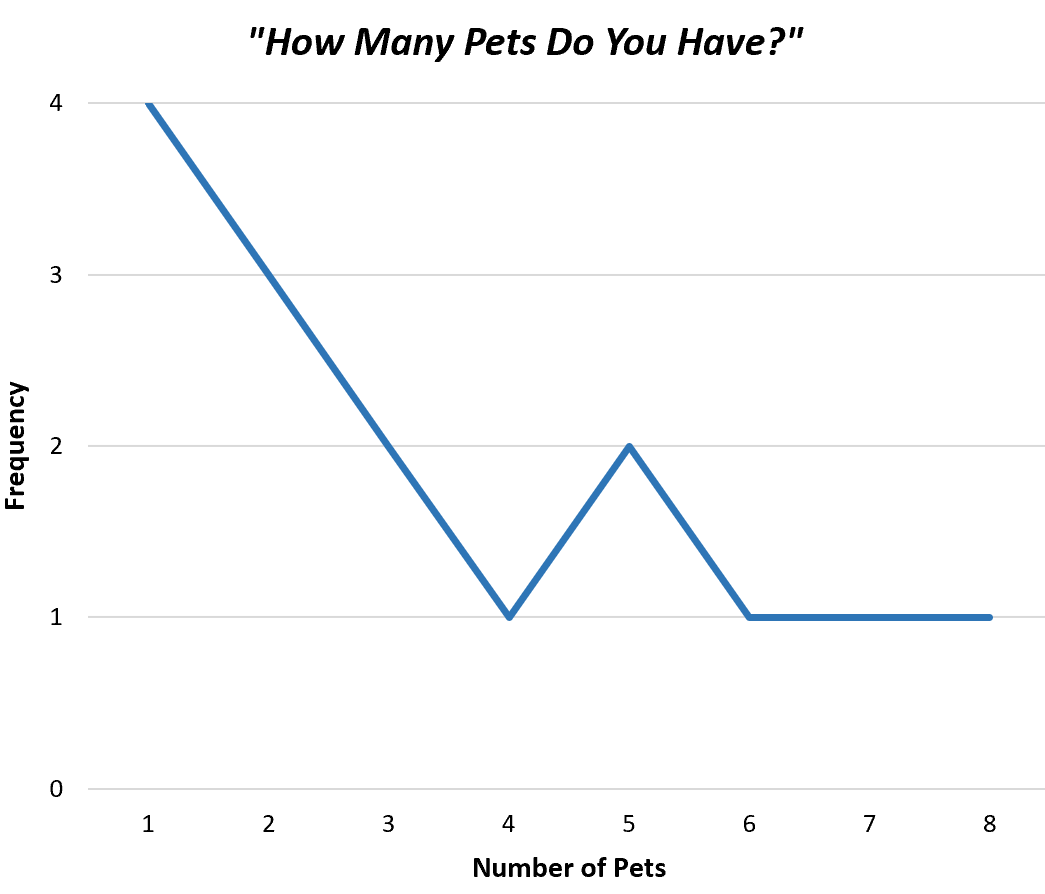
Dies hilft uns, schnell zu verstehen, wie oft jeder Wert im Datensatz vorkommt.
Alternativ könnten wir ein Balkendiagramm erstellen, um genau dieselben Daten in Balken statt in einer einzelnen Linie anzuzeigen:
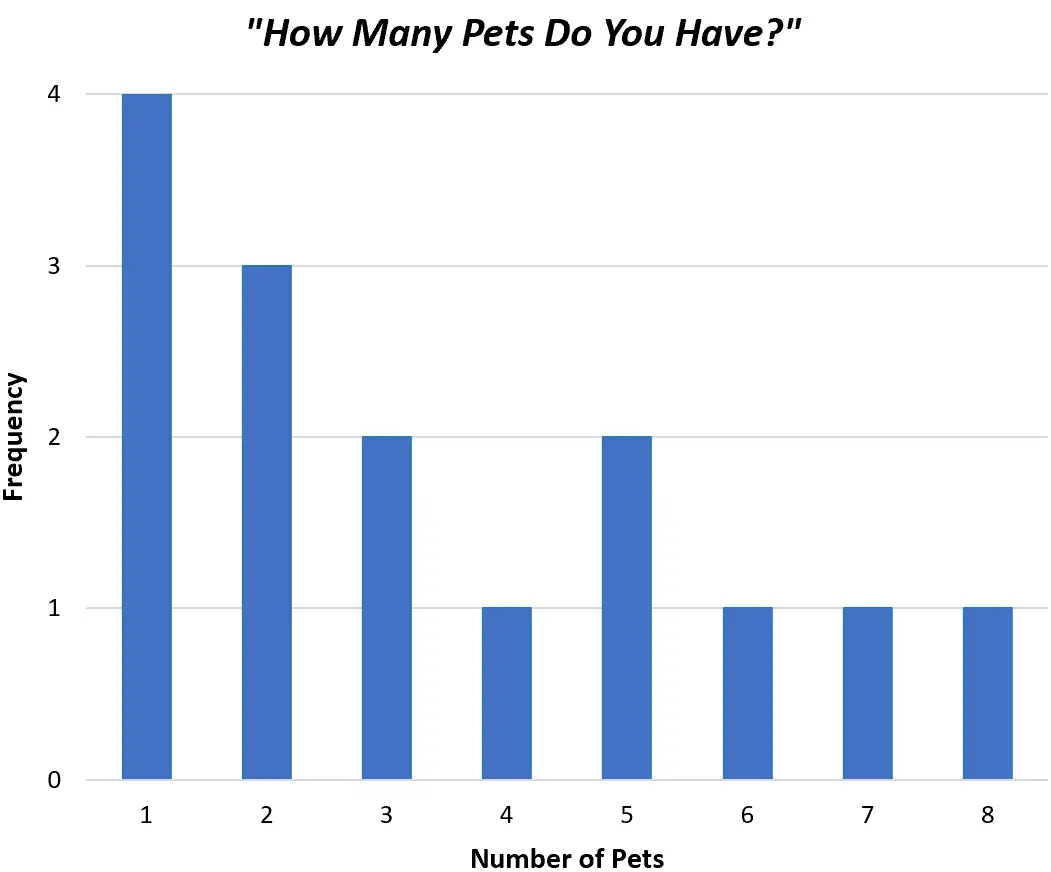
Beide Diagramme ermöglichen uns ein schnelles Verständnis der Werteverteilung in unserem Datensatz.
Über den Autor
Dr. Benjamin Anderson
Hallo, ich bin Benjamin, ein pensionierter Statistikprofessor, der sich zum engagierten Statorials-Lehrer entwickelt hat. Mit umfassender Erfahrung und Fachwissen auf dem Gebiet der Statistik bin ich bestrebt, mein Wissen zu teilen, um Studenten durch Statorials zu befähigen. Mehr wissen