Was ist eine offene distribution?
In der Statistik ist eine offene Verteilung eine Häufigkeitsverteilung, in der eine oder mehrere Klassen (oder „Bins“) offen sind.
Die folgende Häufigkeitsverteilung stellt beispielsweise eine offene Verteilung dar, bei der die kleinste Klasse offen ist:
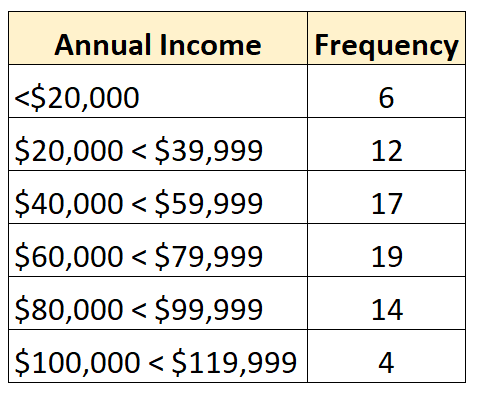
Und die folgende Häufigkeitsverteilung zeigt eine offene Verteilung, bei der die größte Klasse offen ist:
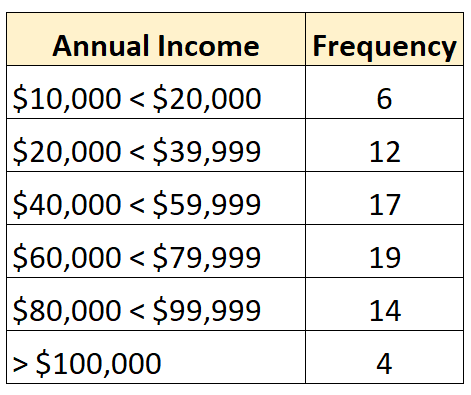
Umgekehrt handelt es sich bei einer geschlossenen Verteilung um eine Verteilung, bei der jede Klasse der Häufigkeitsverteilung eine Ober- und Untergrenze hat, wie zum Beispiel die folgende:
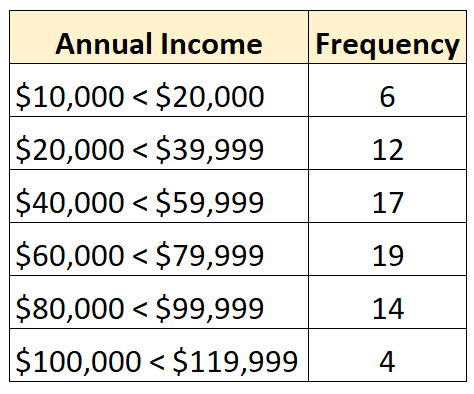
Was verursacht offene Verteilungen?
Offene Verteilungen sind häufig das Ergebnis der Entscheidung von Forschern, Daten so zu sammeln, dass eine der Klassen am Ende offen ist.
Angenommen, ein Forscher befragt Einwohner einer bestimmten Stadt und fragt sie nach ihrem jährlichen Haushaltseinkommen.
Der Forscher kann sich dafür entscheiden, die weitestmögliche Antwort „> 100.000 US-Dollar“ zu geben, da er weiß, dass Einwohner mit hohem Einkommen möglicherweise nicht gerne mitteilen, wie viel sie verdienen, wenn es deutlich über 100.000 US-Dollar liegt.
Umgekehrt könnte sich der Forscher für eine möglichst kurze Antwort entscheiden, weil er oder sie weiß, dass Bewohner, die sehr wenig verdienen, auch nicht gerne ihr Wenigverdienst teilen.
Kurz gesagt, Forscher integrieren häufig offene Kurse in ihre Umfragen, weil sie die Anzahl der Personen maximieren möchten, die sich bei der Beantwortung von Umfragefragen wohl fühlen.
Das Problem mit offenen Distributionen
Das Problem bei offenen Distributionen besteht darin, dass die echten Daten zensiert werden. Mit anderen Worten: Wir können die Anzahl der Menschen kennen, die in einer bestimmten Stadt mehr als 100.000 US-Dollar verdienen, aber wir kennen nicht ihr genaues Jahreseinkommen.
Es ist möglich, dass einige Leute 150.000 $, 250.000 $, 500.000 $ oder sogar mehr verdienen, aber wir haben keine Ahnung, da nicht jede dieser Personen angeben kann, dass sie in der „Untersuchung“ „> 100.000 $“ verdient.
Da die Daten in den offenen Verteilungen zensiert sind, können wir auch nicht den genauen Mittelwert und die Standardabweichung der Werte im Datensatz berechnen, da wir nicht auf alle Werte in den Rohdaten zugreifen können.
So analysieren Sie eine offene Distribution
Da wir den genauen Mittelwert einer offenen Verteilung nicht berechnen können, verwenden wir häufig den Median als Maß für die „Mitte“ des Datensatzes.
Denken Sie daran, dass der Median den Mittelwert des Datensatzes darstellt.
Wenn wir mit offenen Verteilungen arbeiten, können wir die folgende Formel verwenden, um die beste Schätzung des Medians zu ermitteln:
Beste Schätzung des Medians: L + ((n/2 – F) / f) * w
Gold:
- L: Die untere Grenze der mittleren Gruppe
- n: Die Gesamtzahl der Beobachtungen
- F: Die kumulative Häufigkeit bis zur Mittelgruppe
- f: Die Häufigkeit der Mittelgruppe
- w: Die Breite der mittleren Gruppe
Angenommen, wir haben die folgende offene Distribution:
Der Datensatz enthält insgesamt 72 Werte. Wir wissen also, dass der Medianwert zwischen dem 36. und 37. größten Wert im Datensatz liegen wird. Jeder dieser Werte fällt in die Klasse „60.000 – 79.999 US-Dollar“, daher wissen wir, dass das Durchschnittseinkommen in diesem Bereich liegt.
Unsere beste Schätzung des Medians wäre:
Median: 60.000 + ((72/2 – 25) / 19) * 19.999 = 71.578 $
Dieser Wert stellt unsere beste Schätzung des mittleren Jahreseinkommens der Personen in diesem Datensatz dar.
Über den Autor
Dr. Benjamin Anderson
Hallo, ich bin Benjamin, ein pensionierter Statistikprofessor, der sich zum engagierten Statorials-Lehrer entwickelt hat. Mit umfassender Erfahrung und Fachwissen auf dem Gebiet der Statistik bin ich bestrebt, mein Wissen zu teilen, um Studenten durch Statorials zu befähigen. Mehr wissen