Pandas: csv mit unterschiedlicher anzahl von spalten pro zeile importieren
Sie können die folgende grundlegende Syntax verwenden, um eine CSV-Datei in Pandas zu importieren, wenn eine unterschiedliche Anzahl von Spalten pro Zeile vorhanden ist:
df = pd. read_csv (' uneven_data.csv ', header= None , names=range( 4 ))
Der Wert innerhalb der Funktion range() sollte die Anzahl der Spalten in der Zeile mit der maximalen Anzahl von Spalten sein.
Das folgende Beispiel zeigt, wie diese Syntax in der Praxis verwendet wird.
Beispiel: CSV mit unterschiedlicher Anzahl von Spalten pro Zeile in Pandas importieren
Nehmen wir an, wir haben die folgende CSV-Datei mit dem Namen ungleiche_data.csv :
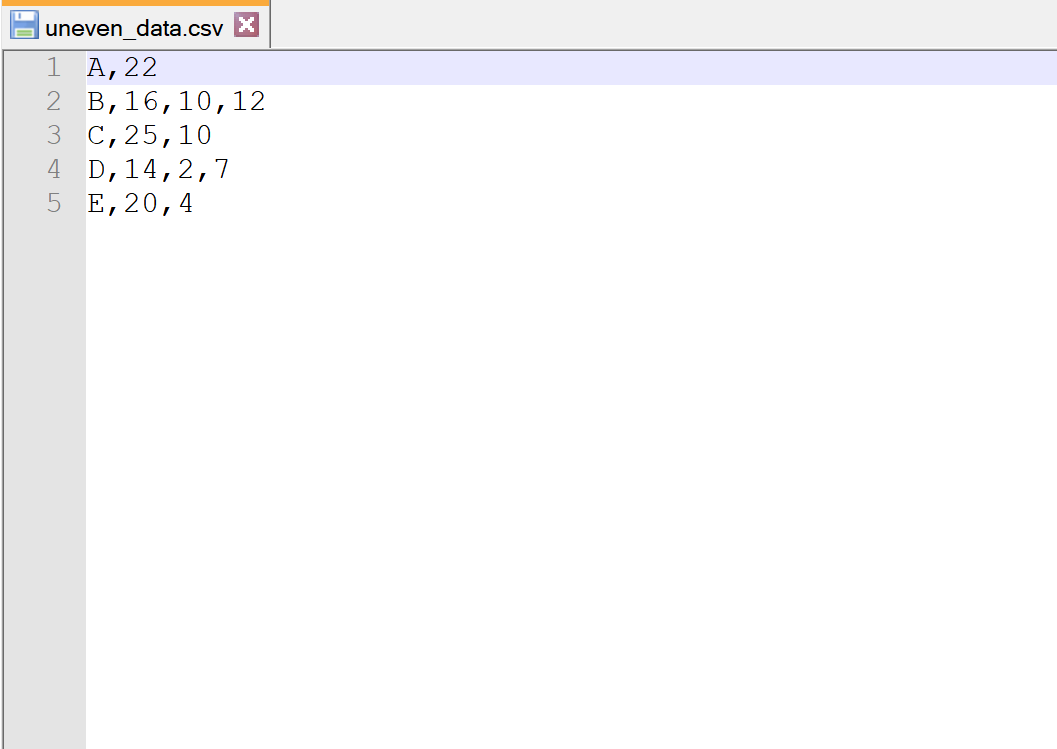
Beachten Sie, dass nicht jede Zeile die gleiche Anzahl an Spalten hat.
Wenn wir versuchen, diese CSV-Datei mit der Funktion read_csv() in einen Pandas-DataFrame zu importieren, erhalten wir eine Fehlermeldung:
import pandas as pd #attempt to import CSV file with differing number of columns per row df = pd. read_csv (' uneven_data.csv ', header= None ) ParserError: Error tokenizing data. C error: Expected 2 fields in line 2, saw 4
Wir erhalten einen ParserError , der uns mitteilt, dass Pandas 2 Felder erwartet hat (da dies die Anzahl der Spalten in der ersten Zeile war), aber 4 gesehen hat.
Dieser Fehler sagt uns, dass die maximale Anzahl von Spalten in einer bestimmten Zeile 4 beträgt.
Wir können also die CSV-Datei importieren und dem Argument „Names“ den Wert „range(4)“ hinzufügen:
import pandas as pd #import CSV file with differing number of columns per row df = pd. read_csv (' uneven_data.csv ', header= None , names=range( 4 ))) #view DataFrame print (df) 0 1 2 3 0 to 22 NaN NaN 1 B 16 10.0 12.0 2 C 25 10.0 NaN 3 D 14 2.0 7.0 4 E 20 4.0 NaN
Beachten Sie, dass wir die CSV-Datei ohne Fehler erfolgreich in einen Pandas-DataFrame importieren können, da wir Pandas ausdrücklich angewiesen haben, 4 Spalten zu erwarten.
Standardmäßig füllt Pandas alle fehlenden Werte in jeder Zeile mit NaN.
Wenn Sie möchten, dass fehlende Werte als Null angezeigt werden, können Sie die Funktion fillna() wie folgt verwenden:
#fill NaN values with zeros df_new = df. fillna ( 0 ) #view new DataFrame print (df_new) 0 1 2 3 0 to 22 0.0 0.0 1 B 16 10.0 12.0 2 C 25 10.0 0.0 3 D 14 2.0 7.0 4 E 20 4.0 0.0
Jeder NaN-Wert im DataFrame wurde jetzt durch eine Null ersetzt.
Hinweis : Die vollständige Dokumentation der Funktion pandas read_csv() finden Sie hier .
Zusätzliche Ressourcen
Die folgenden Tutorials erklären, wie Sie andere häufige Aufgaben in Python ausführen:
Pandas: So überspringen Sie Zeilen beim Lesen einer CSV-Datei
Pandas: So fügen Sie Daten zu einer vorhandenen CSV-Datei hinzu
Pandas: So geben Sie Typen beim Importieren einer CSV-Datei an
Pandas: Spaltennamen beim Importieren einer CSV-Datei festlegen
Über den Autor
Dr. Benjamin Anderson
Hallo, ich bin Benjamin, ein pensionierter Statistikprofessor, der sich zum engagierten Statorials-Lehrer entwickelt hat. Mit umfassender Erfahrung und Fachwissen auf dem Gebiet der Statistik bin ich bestrebt, mein Wissen zu teilen, um Studenten durch Statorials zu befähigen. Mehr wissen