So führen sie eine quadratische regression in python durch
Die quadratische Regression ist ein Regressionstyp, mit dem wir die Beziehung zwischen einer Prädiktorvariablen und einer Antwortvariablen quantifizieren können, wenn die wahren Beziehungen quadratisch sind, was in einem Diagramm wie ein „U“ oder ein umgekehrtes „U“ aussehen kann.
Das heißt, wenn die Prädiktorvariable zunimmt, nimmt tendenziell auch die Antwortvariable zu, aber ab einem bestimmten Punkt beginnt die Antwortvariable abzunehmen, wenn die Prädiktorvariable weiter zunimmt.
In diesem Tutorial wird erklärt, wie man eine quadratische Regression in Python durchführt.
Beispiel: Quadratische Regression in Python
Angenommen, wir haben Daten über die Anzahl der pro Woche geleisteten Arbeitsstunden und den gemeldeten Grad der Zufriedenheit (auf einer Skala von 0 bis 100) für 16 verschiedene Personen:
import numpy as np import scipy.stats as stats #define variables hours = [6, 9, 12, 12, 15, 21, 24, 24, 27, 30, 36, 39, 45, 48, 57, 60] happ = [12, 18, 30, 42, 48, 78, 90, 96, 96, 90, 84, 78, 66, 54, 36, 24]
Wenn wir ein einfaches Streudiagramm dieser Daten erstellen, können wir sehen, dass die Beziehung zwischen den beiden Variablen „U“-förmig ist:
import matplotlib.pyplot as plt
#create scatterplot
plt.scatter(hours, happ)
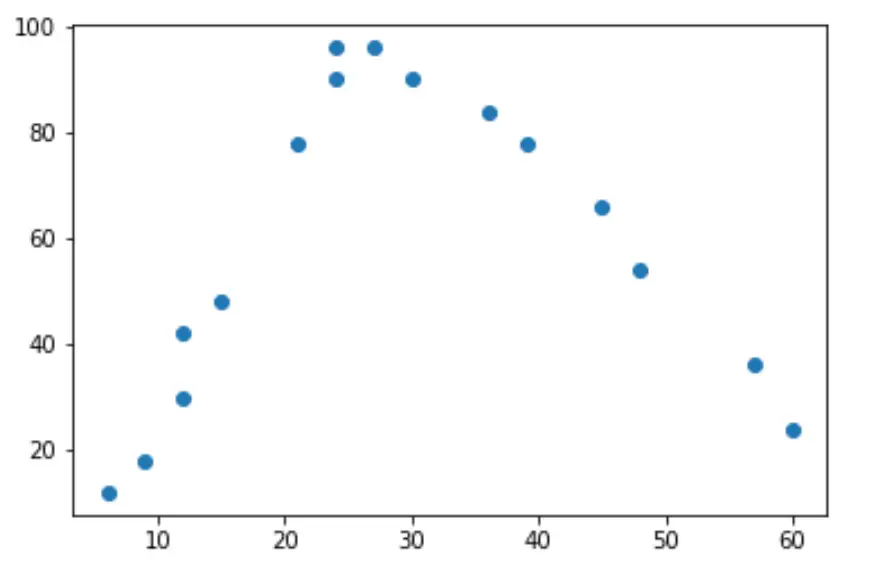
Wenn die geleisteten Arbeitsstunden zunehmen, nimmt auch die Zufriedenheit zu, aber sobald die geleistete Arbeitszeit etwa 35 Stunden pro Woche überschreitet, beginnt die Zufriedenheit zu sinken.
Aufgrund dieser „U“-Form bedeutet dies, dass die quadratische Regression wahrscheinlich ein guter Kandidat für die Quantifizierung der Beziehung zwischen den beiden Variablen ist.
Um tatsächlich eine quadratische Regression durchzuführen, können wir mithilfe der Funktion numpy.polyfit() ein polynomiales Regressionsmodell mit einem Grad von 2 anpassen :
import numpy as np #polynomial fit with degree = 2 model = np.poly1d(np.polyfit(hours, happ, 2)) #add fitted polynomial line to scatterplot polyline = np.linspace(1, 60, 50) plt.scatter(hours, happ) plt.plot(polyline, model(polyline)) plt.show()
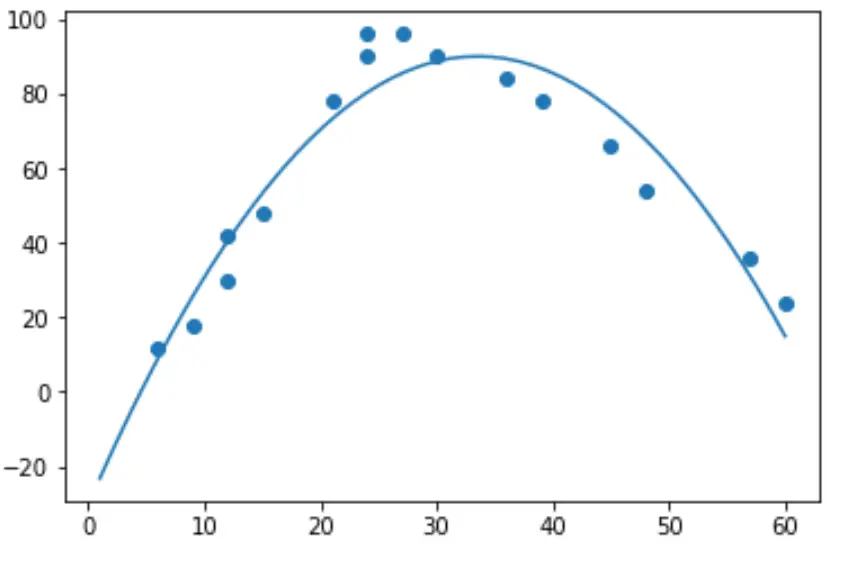
Wir können die angepasste polynomiale Regressionsgleichung erhalten, indem wir die Modellkoeffizienten drucken:
print (model)
-0.107x 2 + 7.173x - 30.25
Die angepasste quadratische Regressionsgleichung lautet:
Glück = -0,107 (Stunden) 2 + 7,173 (Stunden) – 30,25
Mit dieser Gleichung können wir das erwartete Glücksniveau einer Person basierend auf den geleisteten Arbeitsstunden berechnen. Das erwartete Glücksniveau einer Person, die 30 Stunden pro Woche arbeitet, beträgt beispielsweise:
Glück = -0,107(30) 2 + 7,173(30) – 30,25 = 88,64 .
Wir können auch eine kurze Funktion schreiben, um das R-Quadrat des Modells zu erhalten, das den Anteil der Varianz in der Antwortvariablen darstellt, der durch die Prädiktorvariablen erklärt werden kann.
#define function to calculate r-squared def polyfit(x, y, degree): results = {} coeffs = np.polyfit(x, y, degree) p = np.poly1d(coeffs) #calculate r-squared yhat = p(x) ybar = np.sum(y)/len(y) ssreg = np.sum((yhat-ybar)**2) sstot = np.sum((y - ybar)**2) results['r_squared'] = ssreg / sstot return results #find r-squared of polynomial model with degree = 3 polyfit(hours, happ, 2) {'r_squared': 0.9092114182131691}
In diesem Beispiel beträgt das R-Quadrat des Modells 0,9092 .
Dies bedeutet, dass 90,92 % der Schwankungen im gemeldeten Glücksniveau durch die Prädiktorvariablen erklärt werden können.
Zusätzliche Ressourcen
So führen Sie eine Polynomregression in Python durch
So führen Sie eine quadratische Regression in R durch
So führen Sie eine quadratische Regression in Excel durch
Über den Autor
Dr. Benjamin Anderson
Hallo, ich bin Benjamin, ein pensionierter Statistikprofessor, der sich zum engagierten Statorials-Lehrer entwickelt hat. Mit umfassender Erfahrung und Fachwissen auf dem Gebiet der Statistik bin ich bestrebt, mein Wissen zu teilen, um Studenten durch Statorials zu befähigen. Mehr wissen