So legen sie die datenrahmenspalte als index in r fest (mit beispiel)
Datenrahmen in R haben keine „Index“-Spalte, wie dies bei Datenrahmen in Pandas der Fall sein könnte.
Allerdings haben Datenrahmen in R Zeilennamen , die wie eine Indexspalte fungieren.
Sie können eine der folgenden Methoden verwenden, um eine vorhandene Datenrahmenspalte als Zeilennamen für einen Datenrahmen in R festzulegen:
Methode 1: Zeilennamen mithilfe der Basis R festlegen
#set specific column as row names rownames(df) <- df$my_column #remove original column from data frame df$my_column <- NULL
Methode 2: Zeilennamen mit dem Tidyverse-Paket festlegen
library (tidyverse) #set specific column as row names df <- df %>% column_to_rownames(., var = ' my_column ')
Methode 3: Zeilennamen beim Importieren von Daten festlegen
#import CSV file and specify column to use as row names df <- read. csv (' my_data.csv ', row.names =' my_column ')
Die folgenden Beispiele zeigen, wie die einzelnen Methoden in der Praxis angewendet werden.
Beispiel 1: Definieren Sie Zeilennamen mit Base R
Angenommen, wir haben den folgenden Datenrahmen in R:
#create data frame
df <- data. frame (ID=c(101, 102, 103, 104, 105),
points=c(99, 90, 86, 88, 95),
assists=c(33, 28, 31, 39, 34),
rebounds=c(30, 28, 24, 24, 28))
#view data frame
df
ID points assists rebounds
1 101 99 33 30
2 102 90 28 28
3 103 86 31 24
4 104 88 39 24
5 105 95 34 28
Wir können den folgenden Code verwenden, um die ID-Spalte als Zeilennamen festzulegen:
#set ID column as row names
rownames(df) <- df$ID
#remove original ID column from data frame
df$ID <- NULL
#view updated data frame
df
points assists rebounds
101 99 33 30
102 90 28 28
103 86 31 24
104 88 39 24
105 95 34 28
Die Werte in der ID-Spalte sind nun die Zeilennamen des Datenrahmens.
Beispiel 2: Zeilennamen mit dem Tidyverse-Paket festlegen
Der folgende Code zeigt, wie die Funktion „column_to_rownames()“ des Spiceverse- Pakets verwendet wird, um die Zeilennamen auf die ID-Spalte im Datenrahmen festzulegen:
library (tidyverse)
#create data frame
df <- data. frame (ID=c(101, 102, 103, 104, 105),
points=c(99, 90, 86, 88, 95),
assists=c(33, 28, 31, 39, 34),
rebounds=c(30, 28, 24, 24, 28))
#set ID column as row names
df <- df %>% column_to_rownames(., var = ' ID ')
#view updated data frame
df
points assists rebounds
101 99 33 30
102 90 28 28
103 86 31 24
104 88 39 24
105 95 34 28
Beachten Sie, dass dieses Ergebnis mit dem des vorherigen Beispiels übereinstimmt.
Beispiel 3: Beim Importieren von Daten Zeilennamen festlegen
Nehmen wir an, wir haben die folgende CSV-Datei mit dem Namen my_data.csv :
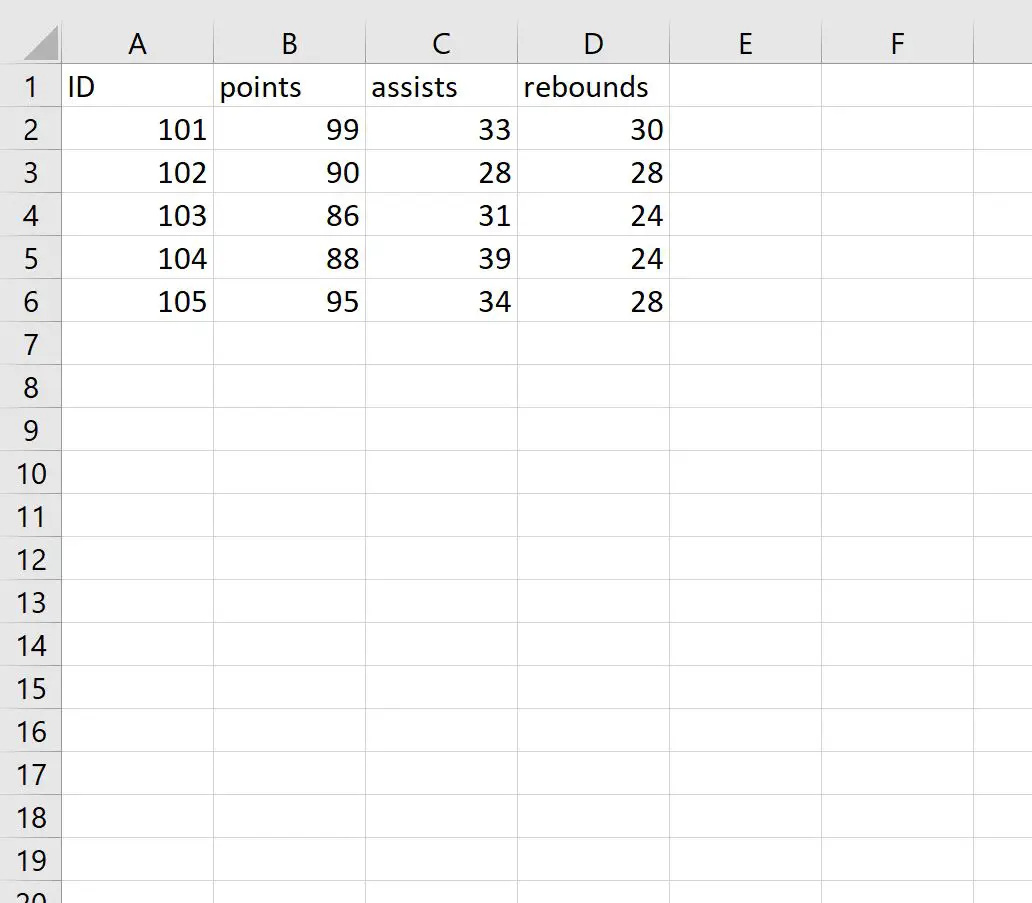
Wir können den folgenden Code verwenden, um die CSV-Datei zu importieren und die Zeilennamen beim Import so festzulegen, dass sie mit der ID-Spalte übereinstimmen:
#import CSV file and specify ID column to use as row names df <- read. csv (' my_data.csv ', row.names =' ID ') #view data frame df points assists rebounds 101 99 33 30 102 90 28 28 103 86 31 24 104 88 39 24 105 95 34 28
Beachten Sie, dass die Werte in der ID-Spalte als Zeilennamen im Datenrahmen verwendet werden.
Zusätzliche Ressourcen
In den folgenden Tutorials wird erläutert, wie Sie andere häufige Aufgaben in R ausführen:
So entfernen Sie Zeilen basierend auf der Bedingung aus dem Datenrahmen in R
So ersetzen Sie Werte im Datenrahmen in R
So entfernen Sie Spalten aus dem Datenrahmen in R
Über den Autor
Dr. Benjamin Anderson
Hallo, ich bin Benjamin, ein pensionierter Statistikprofessor, der sich zum engagierten Statorials-Lehrer entwickelt hat. Mit umfassender Erfahrung und Fachwissen auf dem Gebiet der Statistik bin ich bestrebt, mein Wissen zu teilen, um Studenten durch Statorials zu befähigen. Mehr wissen