Eine vollständige anleitung zum diamantdatensatz in r
Der Diamantdatensatz ist ein Datensatz, der in das ggplot2- Paket in R integriert ist.
Es enthält Messungen zu 10 verschiedenen Variablen (wie Preis, Farbe, Reinheit usw.) für 53.940 verschiedene Diamanten.
In diesem Tutorial wird erläutert, wie Sie den Diamantdatensatz in R untersuchen, zusammenfassen und visualisieren.
Diamantdatensatz laden
Da der Diamantdatensatz ein integrierter Datensatz in ggplot2 ist, müssen wir zunächst das ggplot2-Paket installieren (falls noch nicht geschehen) und laden:
#install ggplot2 if not already installed
install. packages (' ggplot2 ')
#load ggplot2
library (ggplot2)
Sobald wir ggplot2 geladen haben, können wir die Funktion data() verwenden, um den Diamantdatensatz zu laden:
data(diamonds)
Mit der Funktion head() können wir uns die ersten sechs Zeilen des Datensatzes ansehen:
#view first six rows of diamonds dataset
head(diamonds)
carat cut color clarity depth table price xyz
1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
3 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31
4 0.290 Premium I VS2 62.4 58 334 4.2 4.23 2.63
5 0.31 Good J SI2 63.3 58 335 4.34 4.35 2.75
6 0.24 Very Good J VVS2 62.8 57 336 3.94 3.96 2.48
Fassen Sie den Diamantdatensatz zusammen
Mit der Funktion summary() können wir jede Variable im Datensatz schnell zusammenfassen:
#summarize diamonds dataset
summary(diamonds)
carat cut color clarity depth
Min. :0.2000 Fair: 1610 D: 6775 SI1:13065 Min. :43.00
1st Qu.:0.4000 Good: 4906 E: 9797 VS2:12258 1st Qu.:61.00
Median: 0.7000 Very Good: 12082 F: 9542 SI2: 9194 Median: 61.80
Mean: 0.7979 Premium: 13791 G: 11292 VS1: 8171 Mean: 61.75
3rd Qu.:1.0400 Ideal:21551 H:8304 VVS2:5066 3rd Qu.:62.50
Max. :5.0100 I: 5422 VVS1: 3655 Max. :79.00
D: 2808 (Other): 2531
table price xyz Min. :43.00 Min. : 326 Min. : 0.000 Min. : 0.000 Min. : 0.000
1st Qu.: 56.00 1st Qu.: 950 1st Qu.: 4.710 1st Qu.: 4.720 1st Qu.: 2.910
Median: 57.00 Median: 2401 Median: 5.700 Median: 5.710 Median: 3.530
Mean: 57.46 Mean: 3933 Mean: 5.731 Mean: 5.735 Mean: 3.539
3rd Qu.: 59.00 3rd Qu.: 5324 3rd Qu.: 6.540 3rd Qu.: 6.540 3rd Qu.: 4.040
Max. :95.00 Max. :18823 Max. :10,740 Max. :58,900 Max. :31,800
Für jede der numerischen Variablen können wir die folgenden Informationen sehen:
- Min : Der Mindestwert.
- 1. Qu : Der Wert des ersten Quartils (25. Perzentil).
- Median : Der Medianwert.
- Durchschnitt : Der Durchschnittswert.
- 3. Qu : Der Wert des dritten Quartils (75. Perzentil).
- Max : Der Maximalwert.
Für die kategorialen Variablen im Datensatz (Schnitt, Farbe und Klarheit) sehen wir eine Häufigkeitszählung jedes Werts.
Zum Beispiel für die Cut- Variable:
- Mittelmäßig : Dieser Wert kommt 1.610 Mal vor.
- Gut : Dieser Wert kommt 4.906 Mal vor.
- Sehr gut : Dieser Wert kommt 12.082 Mal vor.
- Premium : Dieser Wert kommt 13.791 Mal vor.
- Ideal : Dieser Wert kommt 21.551 Mal vor.
Mit der Funktion dim() können wir die Dimensionen des Datensatzes in Bezug auf die Anzahl der Zeilen und Spalten ermitteln:
#display rows and columns
dim(diamonds)
[1] 53940 10
Wir können sehen, dass der Datensatz 53.940 Zeilen und 10 Spalten enthält.
Wir können auch die Funktion „names()“ verwenden, um die Spaltennamen des Datenrahmens anzuzeigen:
#display column names
names(diamonds)
[1] "carat" "cut" "color" "clarity" "depth" "table" "price" "x"
[9] “y” “z”
Visualisieren Sie den Diamanten-Datensatz
Wir können auch Diagramme erstellen, um die Werte des Datensatzes zu visualisieren.
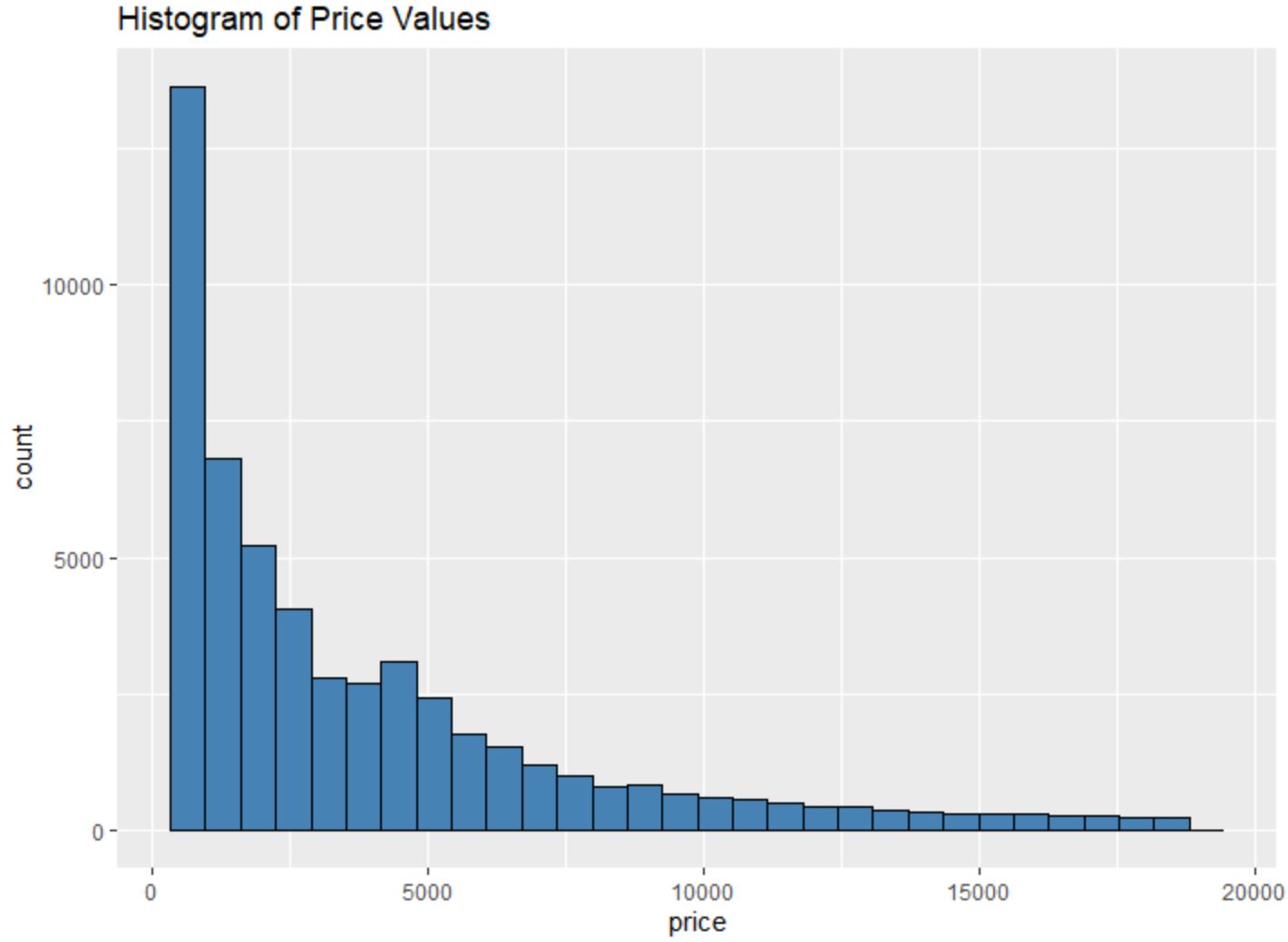
Beispielsweise können wir die Funktion geom_histogram() verwenden, um ein Histogramm der Werte einer bestimmten Variablen zu erstellen:
#create histogram of values for price
ggplot(data=diamonds, aes (x=price)) +
geom_histogram(fill=" steelblue ", color=" black ") +
ggtitle(" Histogram of Price Values ")
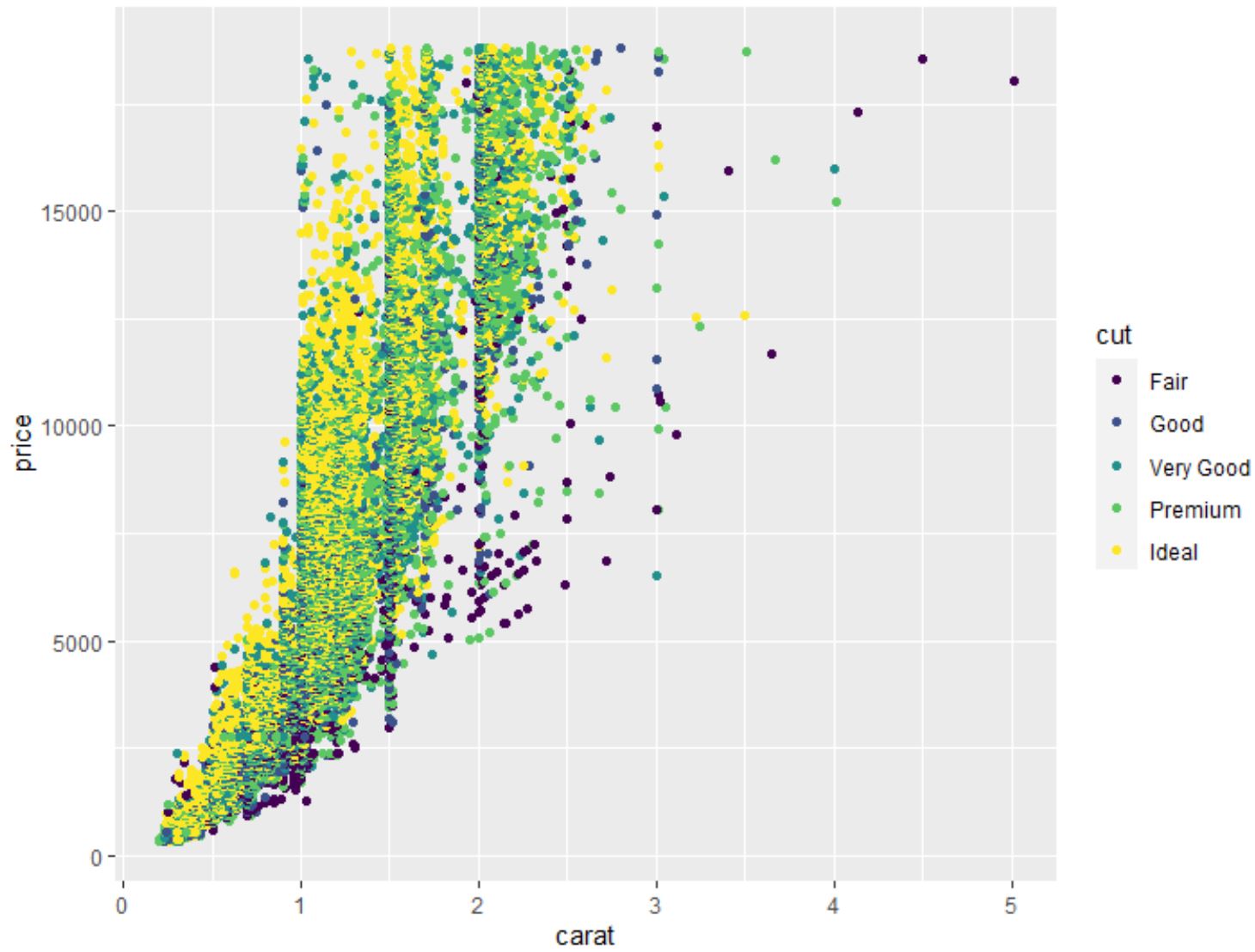
Wir können auch die Funktion geom_point() verwenden, um eine Punktwolke aus einer beliebigen paarweisen Kombination von Variablen zu erstellen:
#create scatterplot of carat vs. price, using cut as color variable
ggplot(data=diamonds, aes (x=carat, y=price, color=cut)) +
geom_point()
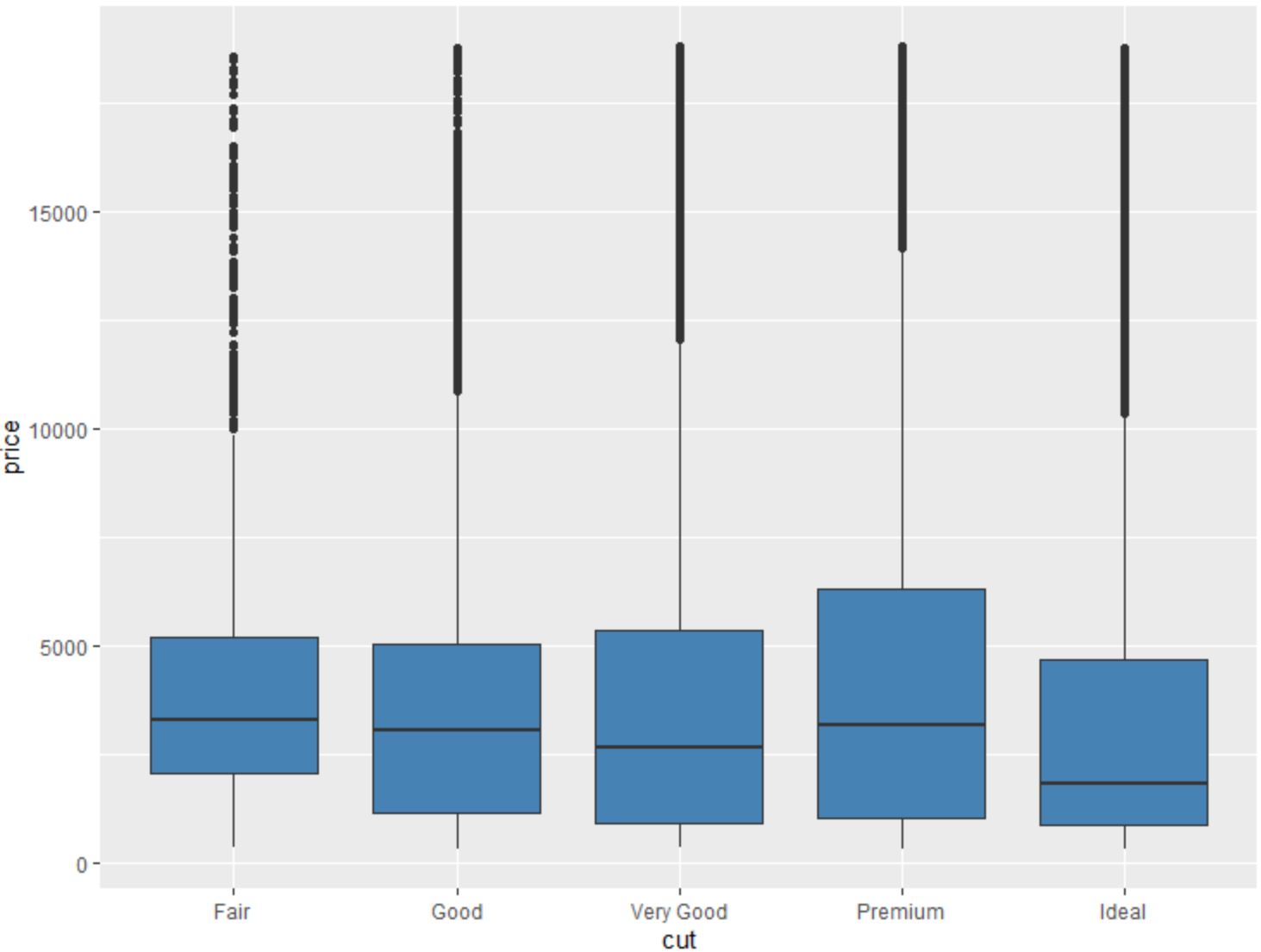
Wir können auch die Funktion geom_boxplot() verwenden, um einen Boxplot einer Variablen gruppiert nach einer anderen Variablen zu erstellen:
#create scatterplot of price, grouped by cut
ggplot(data=diamonds, aes (x=cut, y=price)) +
geom_boxplot(fill=" steelblue ")
Mit diesen ggplot2-Funktionen können wir viel über die Variablen im Diamantdatensatz lernen.
Zusätzliche Ressourcen
In den folgenden Tutorials wird erläutert, wie Sie andere Datensätze in R erkunden:
Eine vollständige Anleitung zum Iris-Datensatz in R
Eine vollständige Anleitung zum mtcars-Datensatz in R
Über den Autor
Dr. Benjamin Anderson
Hallo, ich bin Benjamin, ein pensionierter Statistikprofessor, der sich zum engagierten Statorials-Lehrer entwickelt hat. Mit umfassender Erfahrung und Fachwissen auf dem Gebiet der Statistik bin ich bestrebt, mein Wissen zu teilen, um Studenten durch Statorials zu befähigen. Mehr wissen