Randomisierung in der statistik: definition und beispiel
Unter Randomisierung versteht man in der Statistik die zufällige Zuteilung von Studienteilnehmern zu verschiedenen Behandlungsgruppen.
Angenommen, Forscher rekrutieren 100 Probanden für die Teilnahme an einer Studie, in der sie herausfinden möchten, ob zwei verschiedene Pillen unterschiedliche Auswirkungen auf den Blutdruck haben.
Sie können sich dafür entscheiden, einen Zufallszahlengenerator zu verwenden, um jedem Probanden zufällig die Einnahme von Pille Nr. 1 oder Pille Nr. 2 zuzuweisen.
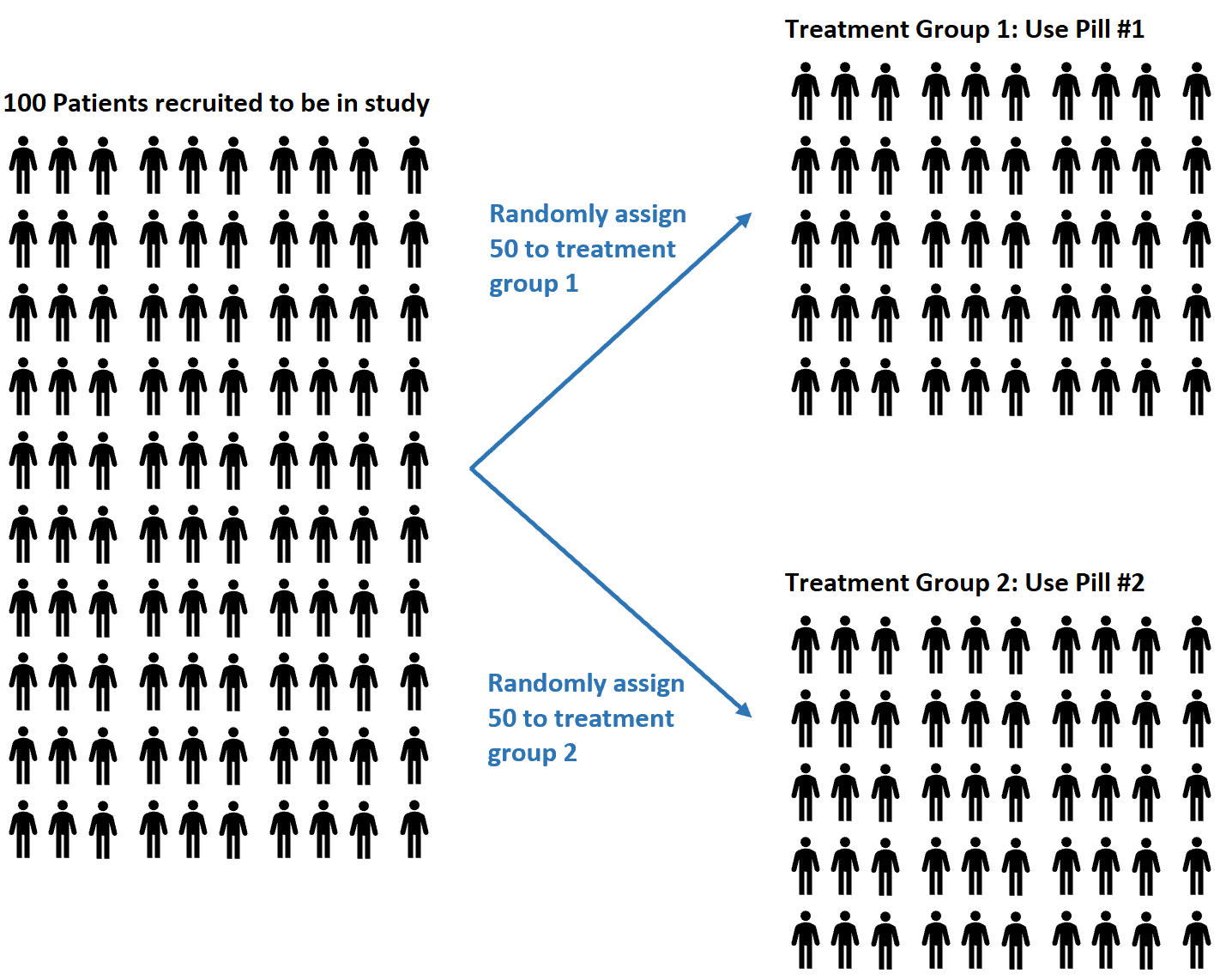
Vorteile der Randomisierung
Der Zweck der Randomisierung besteht darin , versteckte Variablen zu kontrollieren – Variablen, die nicht direkt in eine Analyse einbezogen werden, sich aber dennoch in irgendeiner Weise auf die Analyse auswirken.
Wenn Forscher beispielsweise die Auswirkungen zweier verschiedener Pillen auf den Blutdruck untersuchen, könnten die folgenden versteckten Variablen die Analyse beeinflussen:
- Smoking-Kleidung
- Diät
- Übung
Durch die zufällige Zuweisung von Probanden zu Behandlungsgruppen maximieren wir die Chance, dass versteckte Variablen beide Behandlungsgruppen gleichermaßen beeinflussen.
Dies bedeutet, dass jeder Blutdruckunterschied eher auf die Art der Pille als auf die Wirkung einer versteckten Variablen zurückzuführen ist.
Randomisierung blockieren
Eine Erweiterung der Randomisierung ist die sogenannte Block-Randomisierung . Dabei werden die Probanden zunächst in Blöcke aufgeteilt und dann mithilfe der Randomisierung den Probanden innerhalb der Blöcke verschiedene Behandlungen zugewiesen.
Wenn Forscher beispielsweise wissen möchten, ob sich zwei verschiedene Pillen unterschiedlich auf den Blutdruck auswirken, können sie zunächst alle Probanden nach Geschlecht in zwei Blöcke einteilen: männlich oder weiblich.
Dann können sie in jedem Block mithilfe der Randomisierung den Probanden nach dem Zufallsprinzip entweder Pille Nr. 1 oder Pille Nr. 2 zuweisen.
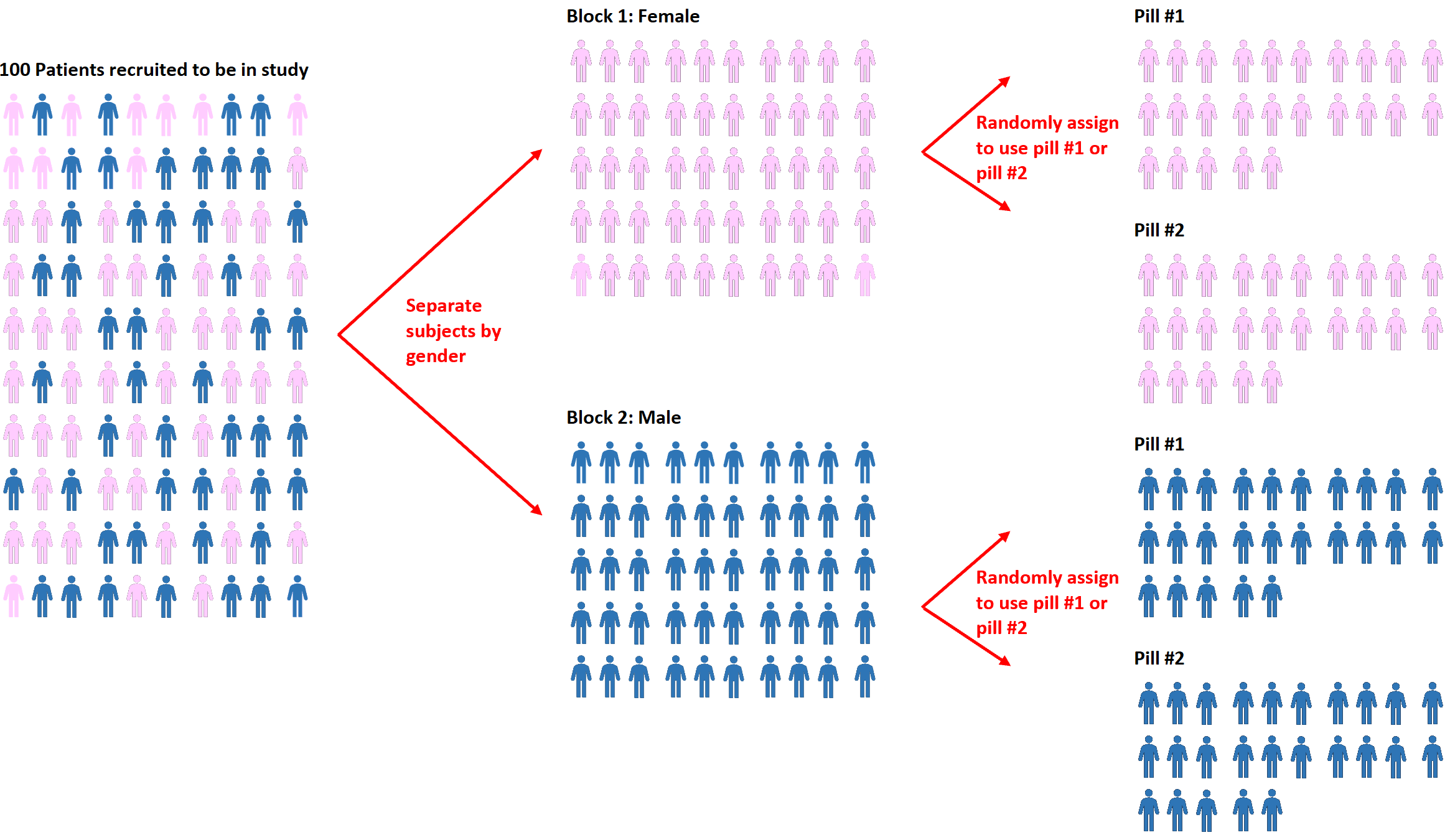
Der Vorteil dieses Ansatzes besteht darin, dass Forscher jede Auswirkung des Geschlechts auf den Blutdruck direkt kontrollieren können, da wir wissen, dass Männer und Frauen wahrscheinlich unterschiedlich auf jede Pille reagieren.
Durch die Verwendung des Geschlechts als Block können wir diese Variable als potenzielle Variationsquelle eliminieren. Wenn es Unterschiede im Blutdruck zwischen den beiden Pillen gibt, können wir davon ausgehen, dass das Geschlecht nicht die zugrunde liegende Ursache dieser Unterschiede ist.
Zusätzliche Ressourcen
Blockierung in Statistiken: Definition und Beispiel
Randomisierung permutierter Blöcke: Definition und Beispiel
Versteckte Variablen: Definition und Beispiele
Über den Autor
Dr. Benjamin Anderson
Hallo, ich bin Benjamin, ein pensionierter Statistikprofessor, der sich zum engagierten Statorials-Lehrer entwickelt hat. Mit umfassender Erfahrung und Fachwissen auf dem Gebiet der Statistik bin ich bestrebt, mein Wissen zu teilen, um Studenten durch Statorials zu befähigen. Mehr wissen