Verwendung von dummy-variablen in der regressionsanalyse
Die lineare Regression ist eine Methode, mit der wir die Beziehung zwischen einer oder mehreren Prädiktorvariablen und einer Antwortvariablen quantifizieren können.
Wir verwenden im Allgemeinen lineare Regression mit quantitativen Variablen . Manchmal auch „numerische“ Variablen genannt, handelt es sich dabei um Variablen, die eine messbare Größe darstellen. Beispiele beinhalten:
- Anzahl der Quadratmeter in einem Haus
- Bevölkerungsgröße einer Stadt
- Alter einer Person
Manchmal möchten wir jedoch kategoriale Variablen als Prädiktorvariablen verwenden. Dies sind Variablen, die Namen oder Bezeichnungen annehmen und in Kategorien fallen können. Beispiele beinhalten:
- Augenfarbe (z. B. „blau“, „grün“, „braun“)
- Geschlecht (z. B. „Mann“, „Frau“)
- Familienstand (z. B. „verheiratet“, „ledig“, „geschieden“)
Bei der Verwendung kategorialer Variablen macht es keinen Sinn, Werte wie 1, 2, 3 einfach Werten wie „blau“, „grün“ und „braun“ zuzuweisen, da dies keinen Sinn ergibt das Grün ist doppelt. so bunt wie Blau oder Braun, ist dreimal bunter als Blau.
Stattdessen besteht die Lösung darin, Dummy-Variablen zu verwenden. Dabei handelt es sich um Variablen, die wir speziell für die Regressionsanalyse erstellen und die einen von zwei Werten annehmen: Null oder Eins.
Dummy-Variablen: Numerische Variablen, die in der Regressionsanalyse zur Darstellung kategorialer Daten verwendet werden, die nur einen von zwei Werten annehmen können: Null oder Eins.
Die Anzahl der Dummy-Variablen, die wir erstellen müssen, ist gleich k -1, wobei k die Anzahl der verschiedenen Werte ist, die die kategoriale Variable annehmen kann.
Die folgenden Beispiele veranschaulichen, wie Dummy-Variablen für verschiedene Datensätze erstellt werden.
Beispiel 1: Erstellen Sie eine Dummy-Variable mit nur zwei Werten
Angenommen, wir haben den folgenden Datensatz und möchten Geschlecht und Alter verwenden, um das Einkommen vorherzusagen:
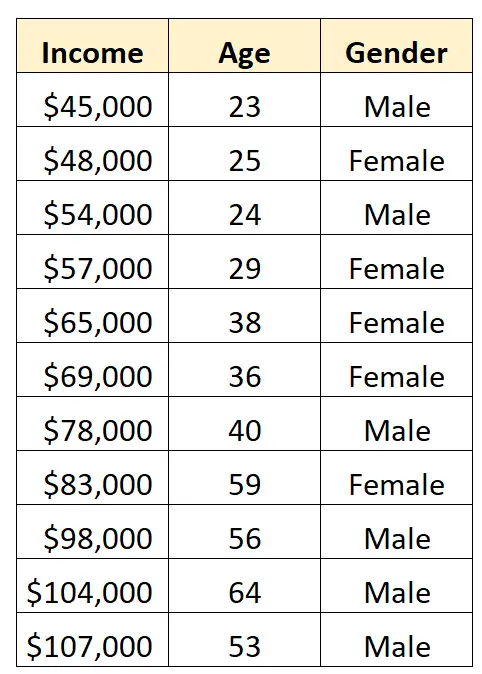
Um das Geschlecht als Prädiktorvariable in einem Regressionsmodell zu verwenden, müssen wir es in eine Dummy-Variable umwandeln.
Da es sich derzeit um eine kategoriale Variable handelt, die zwei verschiedene Werte („männlich“ oder „weiblich“) annehmen kann, erstellen wir einfach k -1 = 2-1 = 1 Dummy-Variable.
Um diese Dummy-Variable zu erstellen, können wir einen der Werte („Male“ oder „Female“) auswählen, um 0 darzustellen, und den anderen, um 1 darzustellen.
Im Allgemeinen stellen wir den häufigsten Wert normalerweise mit einer 0 dar, was in diesem Datensatz „männlich“ wäre.
So konvertieren Sie das Geschlecht in eine Dummy-Variable:
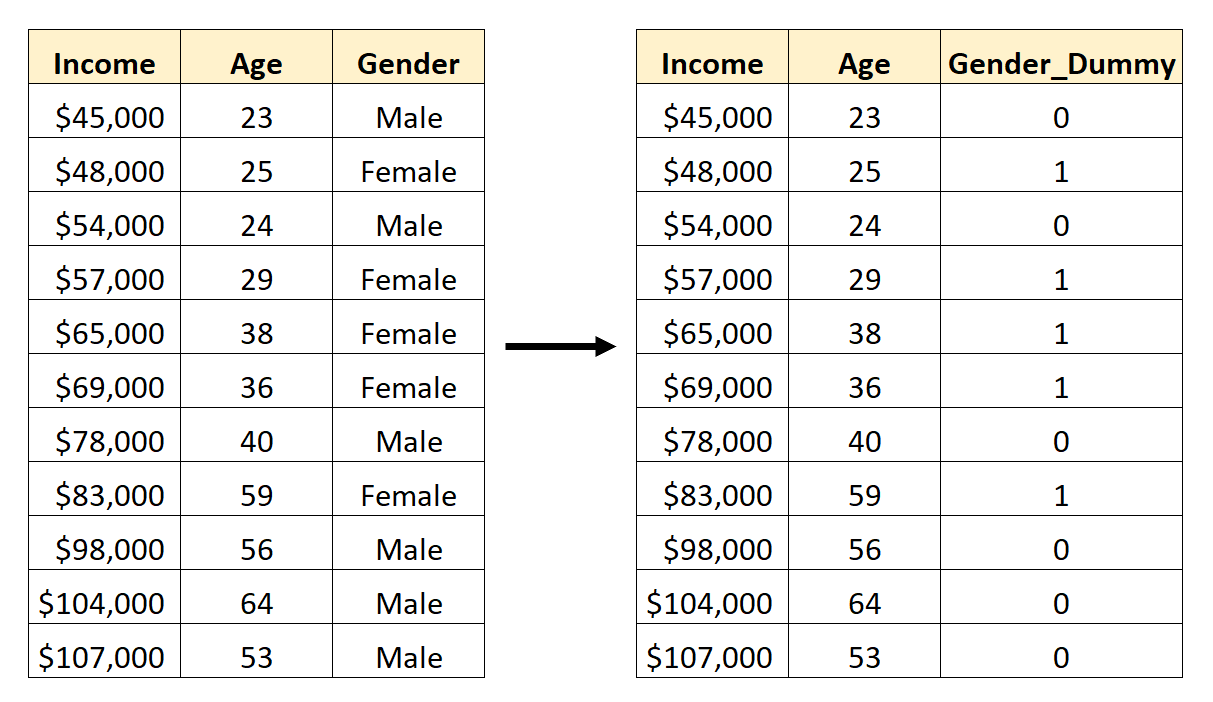
Wir könnten dann Age und Gender_Dummy als Prädiktorvariablen in einem Regressionsmodell verwenden.
Beispiel 2: Erstellen Sie eine Dummy-Variable mit mehreren Werten
Nehmen wir an, wir haben den folgenden Datensatz und möchten Familienstand und Alter verwenden, um das Einkommen vorherzusagen:

Um den Familienstand als Prädiktorvariable in einem Regressionsmodell zu verwenden, müssen wir ihn in eine Dummy-Variable umwandeln.
Da es sich derzeit um eine kategoriale Variable handelt, die drei verschiedene Werte annehmen kann („Single“, „Verheiratet“ oder „Geschieden“), müssen wir k -1 = 3-1 = 2 Dummy-Variablen erstellen.
Um diese Dummy-Variable zu erstellen, können wir „Single“ als Basiswert belassen, da diese am häufigsten vorkommt. So würden wir den Familienstand in Dummy-Variablen umwandeln:

Wir könnten dann Alter , Verheiratet und Geschieden als Prädiktorvariablen in einem Regressionsmodell verwenden.
So interpretieren Sie die Regressionsausgabe mit Dummy-Variablen
Angenommen, wir passen ein multiples lineares Regressionsmodell an, indem wir den Datensatz aus dem vorherigen Beispiel mit Age , Married und Divorced als Prädiktorvariablen und Income als Antwortvariable verwenden.
Hier ist das Ergebnis der Regression:
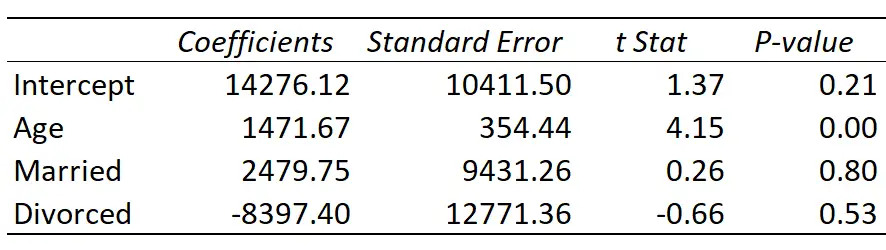
Die angepasste Regressionslinie ist definiert als:
Einkommen = 14.276,21 + 1.471,67*(Alter) + 2.479,75*(verheiratet) – 8.397,40*(Geschieden)
Mit dieser Gleichung können wir das geschätzte Einkommen einer Person basierend auf ihrem Alter und Familienstand ermitteln. Beispielsweise hätte eine verheiratete Person im Alter von 35 Jahren ein geschätztes Einkommen von 68.264 US-Dollar :
Einkommen = 14.276,21 + 1.471,67*(35) + 2.479,75*(1) – 8.397,40*(0) = 68.264 $
So interpretieren Sie die Regressionskoeffizienten in der Tabelle:
- Schnittpunkt: Der Schnittpunkt stellt das durchschnittliche Einkommen einer einzelnen Person im Alter von null Jahren dar. Offensichtlich kann es keine Nulljahre geben, daher macht es keinen Sinn, den Achsenabschnitt allein in diesem speziellen Regressionsmodell zu interpretieren.
- Alter: Jedes Jahr steigenden Alters ist mit einer durchschnittlichen Einkommenssteigerung von 1.471,67 $ verbunden. Da der p-Wert (0,00) kleiner als 0,05 ist, ist das Alter ein statistisch signifikanter Prädiktor für das Einkommen.
- Verheiratet: Eine verheiratete Person verdient im Durchschnitt 2.479,75 $ mehr als eine alleinstehende Person. Da der p-Wert (0,80) nicht kleiner als 0,05 ist, ist dieser Unterschied statistisch nicht signifikant.
- Geschieden: Eine geschiedene Person verdient im Durchschnitt 8.397,40 $ weniger als eine alleinstehende Person. Da der p-Wert (0,53) nicht kleiner als 0,05 ist, ist dieser Unterschied statistisch nicht signifikant.
Da beide Dummy-Variablen statistisch nicht signifikant waren, konnten wir den Familienstand als Prädiktor aus dem Modell entfernen, da er offenbar keinen prädiktiven Wert für das Einkommen bietet.
Zusätzliche Ressourcen
Qualitative und quantitative Variablen
Die Dummy-Variablenfalle
So lesen und interpretieren Sie eine Regressionstabelle
Eine Erklärung der P-Werte und der statistischen Signifikanz
Über den Autor
Dr. Benjamin Anderson
Hallo, ich bin Benjamin, ein pensionierter Statistikprofessor, der sich zum engagierten Statorials-Lehrer entwickelt hat. Mit umfassender Erfahrung und Fachwissen auf dem Gebiet der Statistik bin ich bestrebt, mein Wissen zu teilen, um Studenten durch Statorials zu befähigen. Mehr wissen