Verwendung robuster standardfehler bei der regression in stata
Die multiple lineare Regression ist eine Methode, mit der wir die Beziehung zwischen mehreren erklärenden Variablen und einer Antwortvariablen verstehen können.
Leider tritt bei der Regression häufig ein Problem auf, die sogenannte Heteroskedastizität , bei der es zu einer systematischen Änderung der Varianz der Residuen über einen Bereich gemessener Werte kommt.
Dies führt zu einer Erhöhung der Varianz der Regressionskoeffizientenschätzungen, das Regressionsmodell berücksichtigt dies jedoch nicht. Dies macht es viel wahrscheinlicher, dass ein Regressionsmodell behauptet, ein Term im Modell sei statistisch signifikant, obwohl dies in Wirklichkeit nicht der Fall ist.
Eine Möglichkeit, dieses Problem zu berücksichtigen, besteht darin, robuste Standardfehler zu verwenden, die gegenüber dem Problem der Heteroskedastizität „robuster“ sind und tendenziell ein genaueres Maß für den wahren Standardfehler eines Regressionskoeffizienten liefern.
In diesem Tutorial wird erläutert, wie Sie robuste Standardfehler in der Regressionsanalyse in Stata verwenden.
Beispiel: Robuste Standardfehler in Stata
Wir werden den automatisch integrierten Stata-Datensatz verwenden, um zu veranschaulichen, wie robuste Standardfehler in der Regression verwendet werden.
Schritt 1: Daten laden und anzeigen.
Verwenden Sie zunächst den folgenden Befehl, um die Daten zu laden:
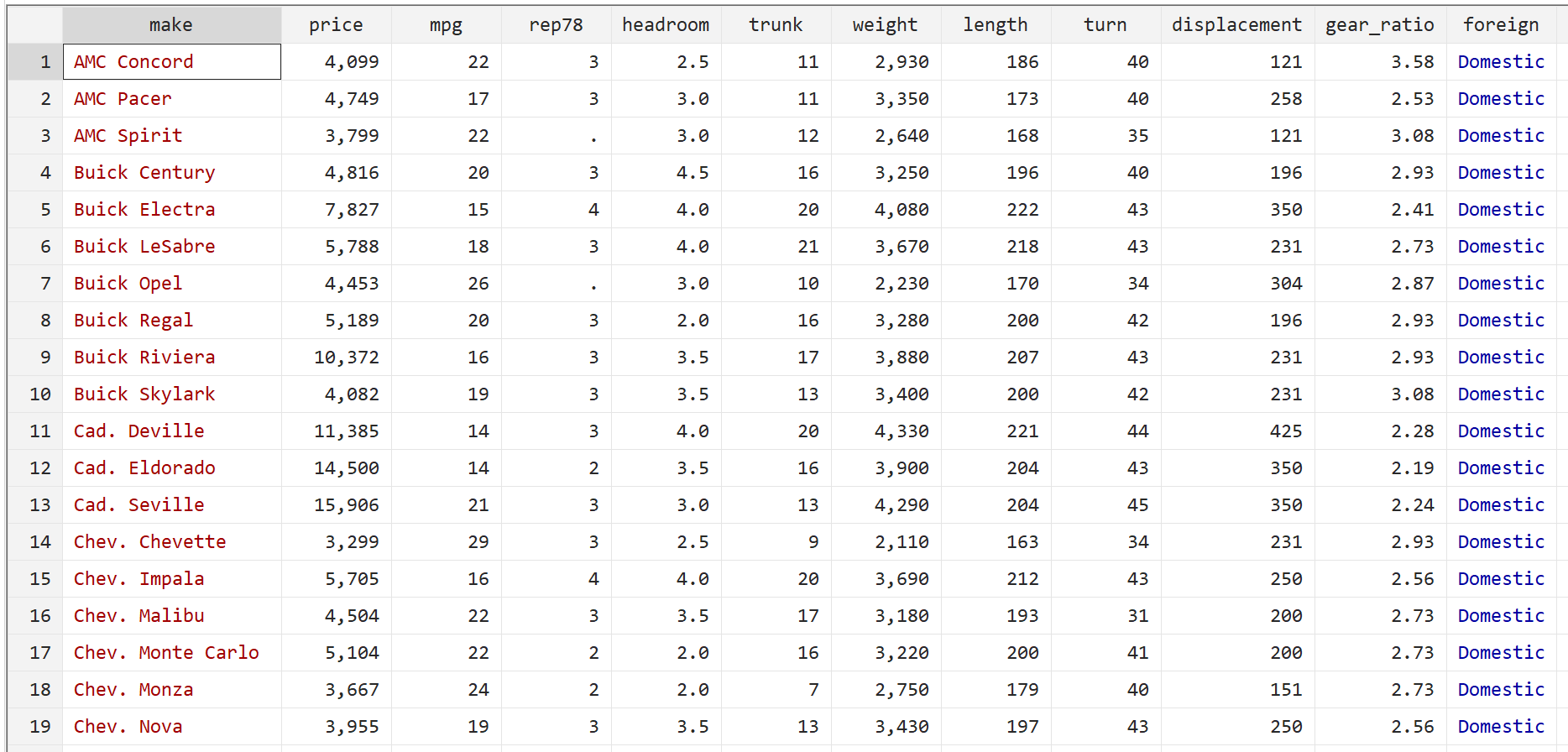
automatische Nutzung des Systems
Anschließend lassen Sie sich die Rohdaten mit folgendem Befehl anzeigen:
br
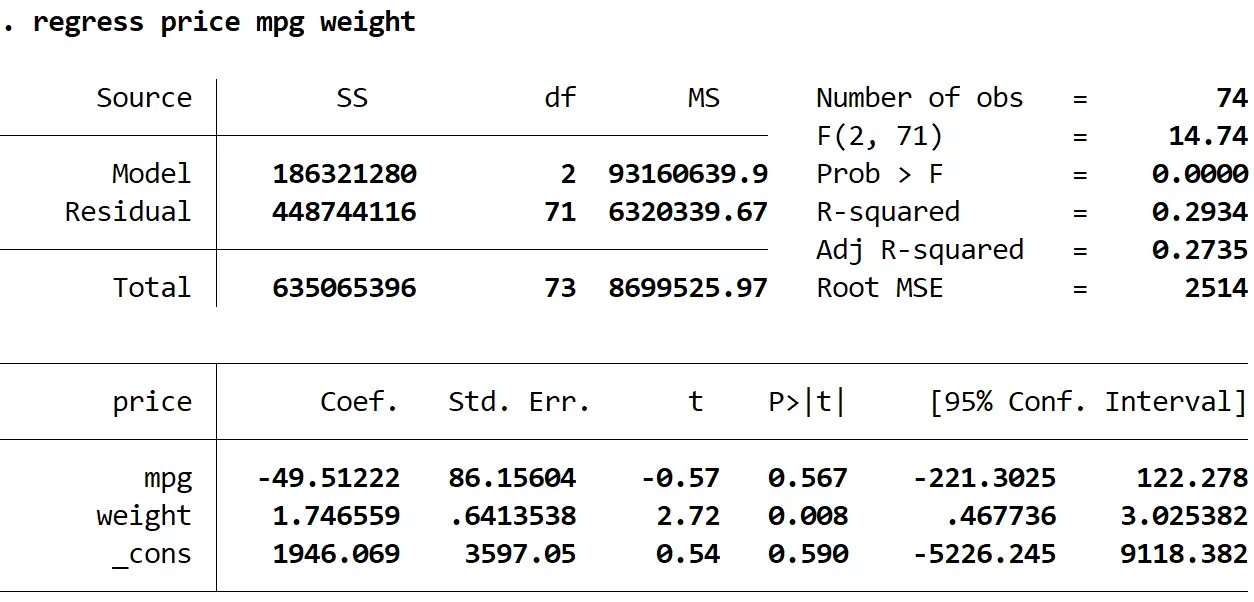
Schritt 2: Führen Sie eine multiple lineare Regression ohne robuste Standardfehler durch.
Als Nächstes geben wir den folgenden Befehl ein, um eine multiple lineare Regression durchzuführen, wobei der Preis als Antwortvariable und mpg und Gewicht als erklärende Variablen verwendet werden:
Regressionspreis mpg Gewicht
Schritt 3: Führen Sie eine multiple lineare Regression mit robusten Standardfehlern durch.
Wir werden jetzt genau die gleiche multiple lineare Regression durchführen, aber dieses Mal werden wir den Befehl vce(robust) verwenden, damit Stata weiß, wie man robuste Standardfehler verwendet:
Regressionspreis MPG-Gewicht, VCE (robust)
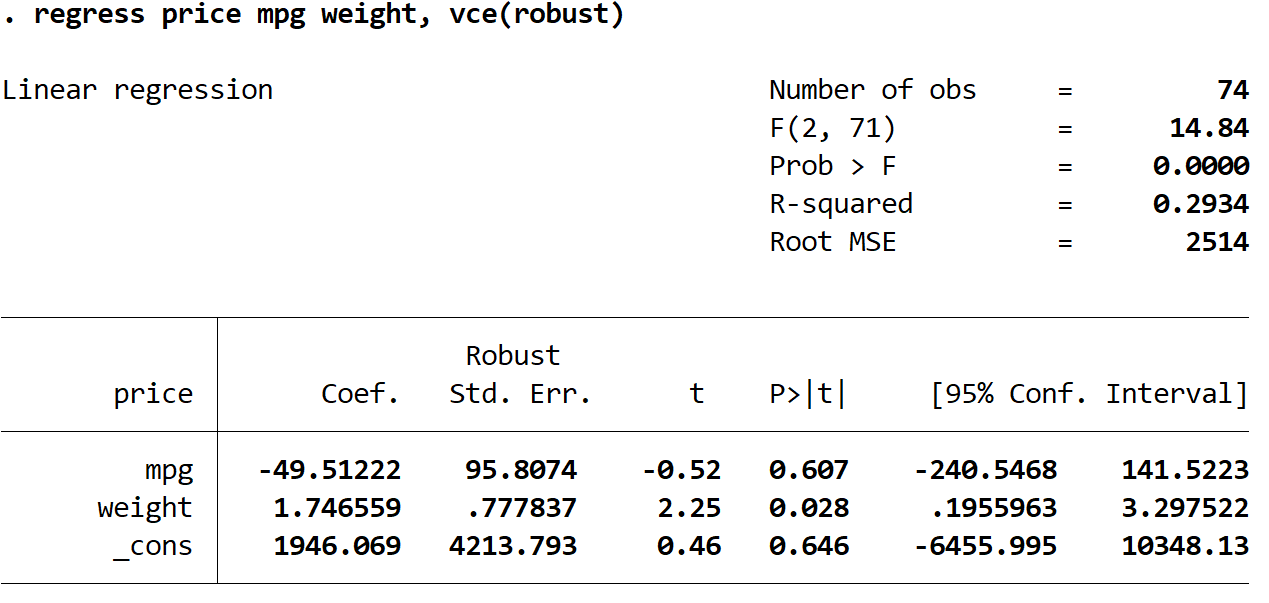
Hier gibt es einige interessante Dinge zu beachten:
1. Die Koeffizientenschätzungen blieben gleich . Wenn wir robuste Standardfehler verwenden, ändern sich die Koeffizientenschätzungen überhaupt nicht. Beachten Sie, dass die Koeffizientenschätzungen für mpg, Gewicht und Konstante für beide Regressionen wie folgt lauten:
- MPG: -49,51222
- Gewicht: 1,746559
- _gegen: 1946.069
2. Standardfehler haben sich geändert . Beachten Sie, dass bei Verwendung robuster Standardfehler die Standardfehler für jede der Koeffizientenschätzungen zunahmen.
Hinweis: In den meisten Fällen sind die robusten Standardfehler größer als die normalen Standardfehler, in seltenen Fällen ist es jedoch möglich, dass die robusten Standardfehler tatsächlich kleiner sind.
3. Die Teststatistik jedes Koeffizienten hat sich geändert. Beachten Sie, dass der absolute Wert jeder Teststatistik , t , abgenommen hat. Tatsächlich wird die Teststatistik als geschätzter Koeffizient dividiert durch den Standardfehler berechnet. Je größer also der Standardfehler ist, desto kleiner ist der Absolutwert der Teststatistik.
4. Die p-Werte haben sich geändert . Beachten Sie, dass auch die p-Werte für jede Variable gestiegen sind. Dies liegt daran, dass kleinere Teststatistiken mit größeren p-Werten verbunden sind.
Obwohl sich die p-Werte für unsere Koeffizienten geändert haben, ist die mpg- Variable bei α = 0,05 immer noch nicht statistisch signifikant und das Variablengewicht ist bei α = 0,05 immer noch statistisch signifikant.
Über den Autor
Dr. Benjamin Anderson
Hallo, ich bin Benjamin, ein pensionierter Statistikprofessor, der sich zum engagierten Statorials-Lehrer entwickelt hat. Mit umfassender Erfahrung und Fachwissen auf dem Gebiet der Statistik bin ich bestrebt, mein Wissen zu teilen, um Studenten durch Statorials zu befähigen. Mehr wissen