Was ist eine verwirrende variable? (definition & #038; beispiel)
In jedem Experiment gibt es zwei Hauptvariablen:
Die unabhängige Variable: die Variable, die ein Experimentator modifiziert oder kontrolliert, um die Auswirkungen auf die abhängige Variable beobachten zu können.
Die abhängige Variable: die in einem Experiment gemessene Variable, die von der unabhängigen Variablen „abhängig“ ist.

Forscher sind häufig daran interessiert zu verstehen, wie sich Änderungen der unabhängigen Variablen auf die abhängige Variable auswirken.
Es kommt jedoch manchmal vor, dass eine dritte Variable nicht berücksichtigt wird und die Beziehung zwischen den beiden untersuchten Variablen beeinflussen kann.
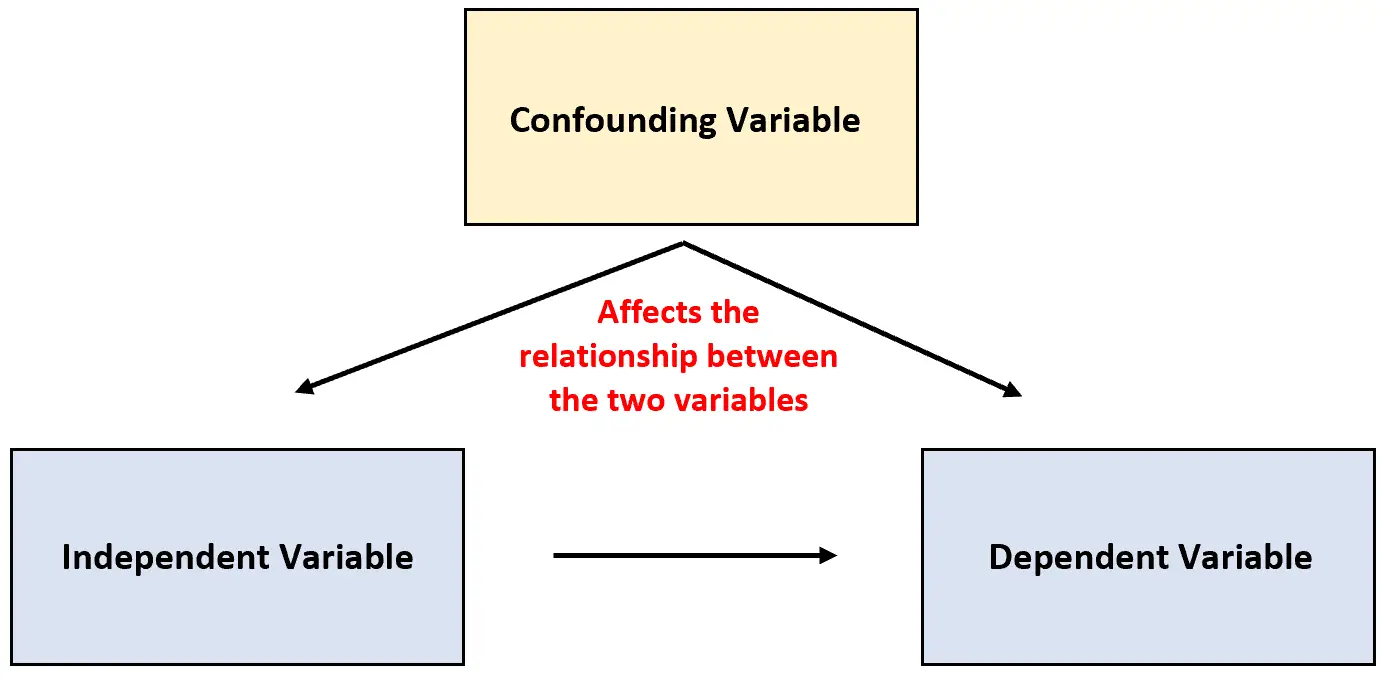
Diese Art von Variable wird als Störvariable bezeichnet und kann die Ergebnisse einer Studie verfälschen und den Anschein erwecken, als gäbe es eine Ursache-Wirkungs-Beziehung zwischen zwei Variablen, die in Wirklichkeit nicht existiert.
Störvariable: Eine Variable, die nicht in einem Experiment enthalten ist, aber die Beziehung zwischen den beiden Variablen in einem Experiment beeinflusst.
Diese Art von Variable kann die Ergebnisse eines Experiments verfälschen und zu unzuverlässigen Ergebnissen führen.
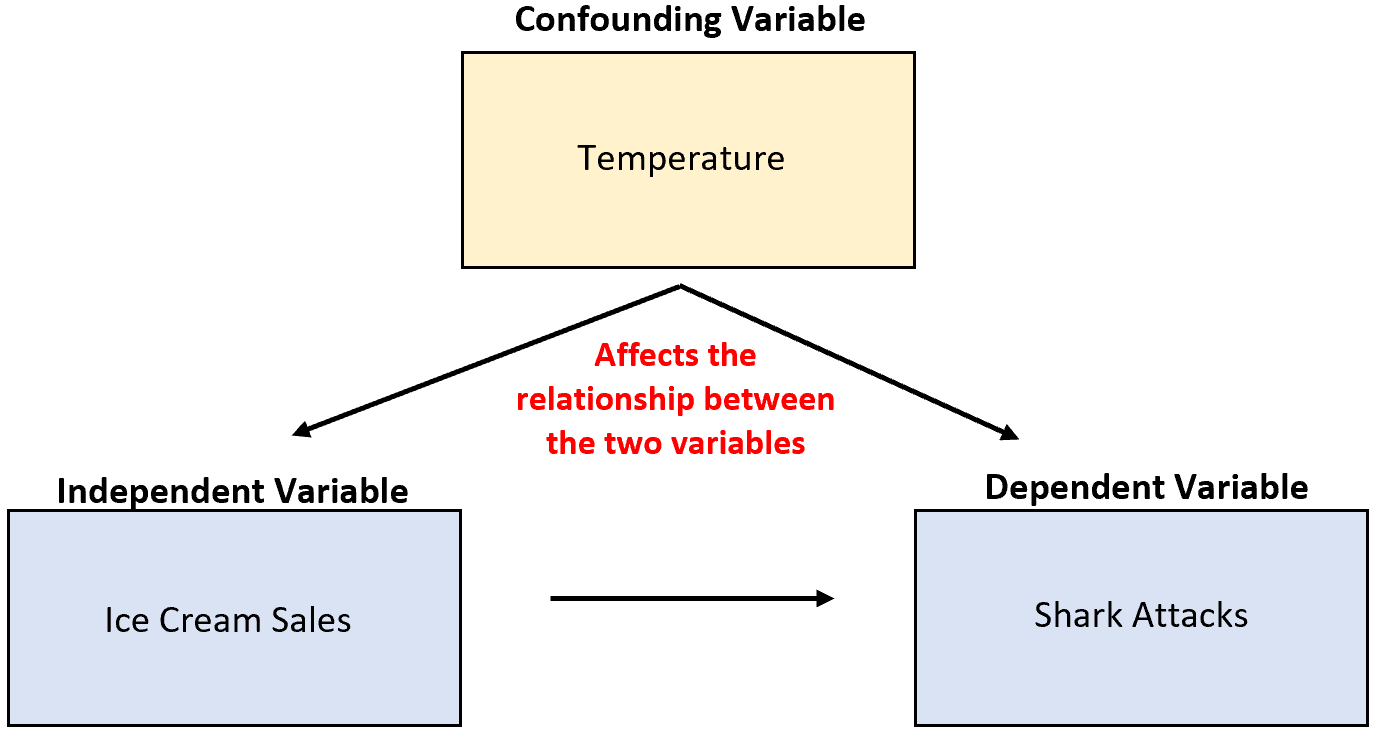
Angenommen, ein Forscher sammelt Daten über Eisverkäufe und Hai-Angriffe und stellt fest, dass die beiden Variablen stark korrelieren. Bedeutet das, dass gestiegene Eisverkäufe zu mehr Hai-Angriffen führen?
Es ist unwahrscheinlich. Die wahrscheinlichste Ursache ist die verwirrende Variable Temperatur . Wenn es draußen wärmer ist, kaufen mehr Menschen Eis und mehr Menschen gehen ans Meer.
Anforderungen an verwirrende Variablen
Damit eine Variable eine verwirrende Variable ist, muss sie die folgenden Anforderungen erfüllen:
1. Es muss mit der unabhängigen Variablen korreliert sein.
Im vorherigen Beispiel wurde die Temperatur mit der unabhängigen Variablen Eisverkäufe korreliert. Insbesondere sind wärmere Temperaturen mit höheren Eisverkäufen und kältere Temperaturen mit geringeren Verkäufen verbunden.
2. Es muss ein kausaler Zusammenhang mit der abhängigen Variablen bestehen.
Im vorherigen Beispiel hatte die Temperatur einen direkten kausalen Einfluss auf die Anzahl der Hai-Angriffe. Insbesondere wärmere Temperaturen treiben mehr Menschen ins Meer, was die Wahrscheinlichkeit von Hai-Angriffen direkt erhöht.
Warum sind verwirrende Variablen problematisch?
Störende Variablen sind aus zwei Gründen problematisch:
1. Störende Variablen können den Anschein erwecken, dass Ursache-Wirkungs-Beziehungen bestehen, obwohl dies nicht der Fall ist.
In unserem vorherigen Beispiel erweckte die verwirrende Temperaturvariable den Anschein, als gäbe es einen kausalen Zusammenhang zwischen Eisverkäufen und Haiangriffen.
Wir wissen jedoch, dass der Verkauf von Eis nicht zu Hai-Angriffen führt. Die verwirrende Variable Temperatur lässt es so erscheinen.
2. Störende Variablen können die wahre Ursache-Wirkungs-Beziehung zwischen Variablen verschleiern.
Angenommen, wir untersuchen die Fähigkeit von Bewegung, den Blutdruck zu senken. Eine mögliche Störvariable ist das Ausgangsgewicht, das mit körperlicher Betätigung korreliert und einen direkten kausalen Einfluss auf den Blutdruck hat.
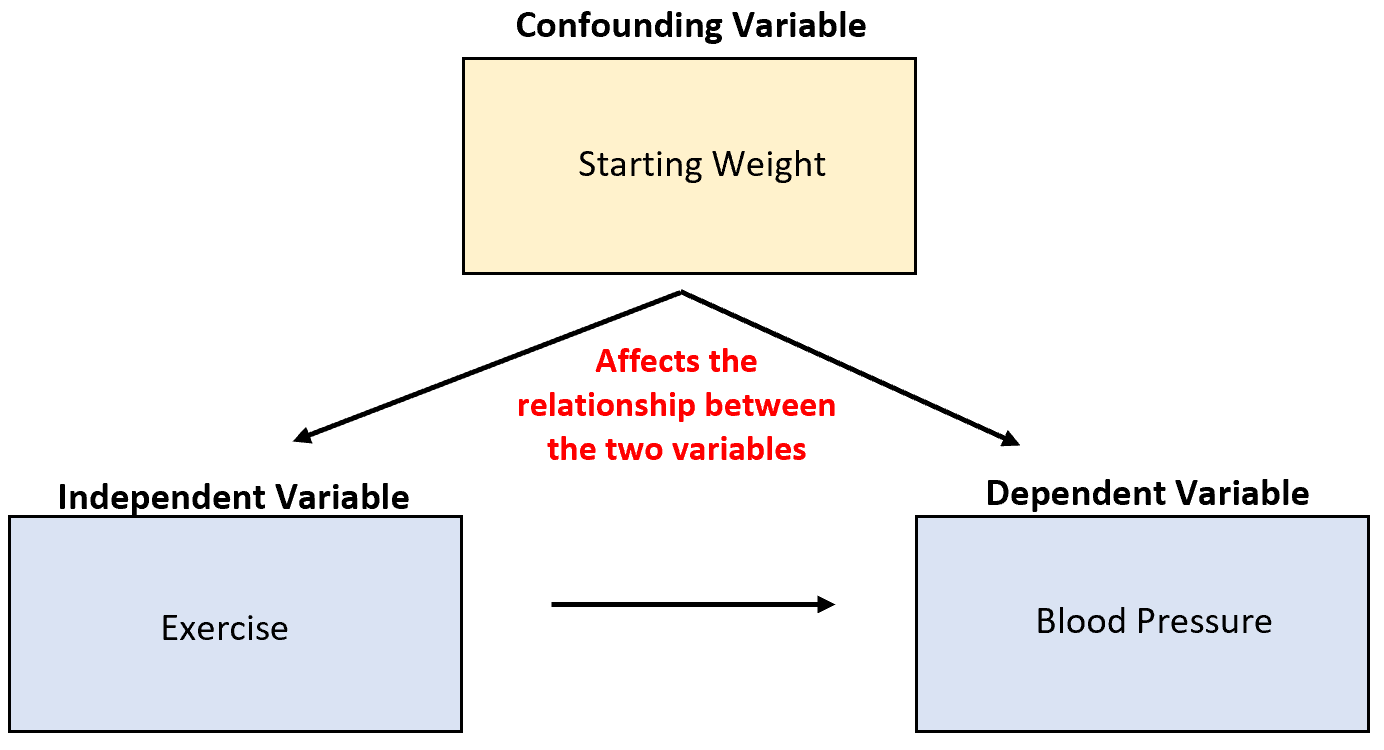
Obwohl erhöhte körperliche Aktivität zu einer Senkung des Blutdrucks führen kann, hat auch das Ausgangsgewicht einer Person einen großen Einfluss auf die Beziehung zwischen diesen beiden Variablen.
Störvariablen und interne Validität
Technisch gesehen beeinflussen Störvariablen die interne Validität einer Studie, die sich auf die Validität der Zuordnung von Änderungen in der abhängigen Variablen zu Änderungen in der unabhängigen Variablen bezieht.
Wenn Störvariablen vorhanden sind, können wir nicht immer mit Sicherheit sagen, dass die Änderungen, die wir in der abhängigen Variablen beobachten, eine direkte Folge von Änderungen in der unabhängigen Variablen sind.
So reduzieren Sie den Effekt verwirrender Variablen
Es gibt mehrere Möglichkeiten, die Auswirkungen verwirrender Variablen zu reduzieren, einschließlich der folgenden Methoden:
1. Zufällige Zuteilung
Zufällige Zuordnung bezieht sich auf den Prozess der zufälligen Zuweisung von Personen in einer Studie zu einer Behandlungsgruppe oder einer Kontrollgruppe.
Nehmen wir zum Beispiel an, wir möchten die Wirkung einer neuen Pille auf den Blutdruck untersuchen. Wenn wir 100 Personen für die Teilnahme an der Studie rekrutieren, könnten wir mithilfe eines Zufallszahlengenerators 50 Personen zufällig einer Kontrollgruppe (keine Pille) und 50 Personen einer Behandlungsgruppe (neue Pille) zuordnen.
Durch die zufällige Zuordnung erhöhen wir die Wahrscheinlichkeit, dass die beiden Gruppen ungefähr ähnliche Merkmale aufweisen, was bedeutet, dass alle beobachteten Unterschiede zwischen den beiden Gruppen auf die Behandlung zurückgeführt werden können.
Das bedeutet, dass die Studie interne Validität haben muss: Es ist gültig, etwaige Blutdruckunterschiede zwischen Gruppen auf die Pille selbst zurückzuführen, im Gegensatz zu Unterschieden zwischen Einzelpersonen in den Gruppen.
2. Blockieren
Unter Blockieren versteht man die Praxis, Personen in einer Studie auf der Grundlage eines bestimmten Werts einer Störvariablen in „Blöcke“ zu unterteilen, um den Effekt der Störvariablen zu eliminieren.
Angenommen, Forscher möchten die Wirkung einer neuen Diät auf die Gewichtsabnahme verstehen. Die unabhängige Variable ist die neue Diät und die abhängige Variable ist das Ausmaß des Gewichtsverlusts.
Eine Störvariable, die zu Schwankungen beim Gewichtsverlust führen kann, ist jedoch das Geschlecht . Es ist wahrscheinlich, dass das Geschlecht einer Person Einfluss darauf hat, wie viel Gewicht sie verliert, unabhängig davon, ob die neue Diät funktioniert oder nicht.
Eine Möglichkeit, dieses Problem zu lösen, besteht darin, Einzelpersonen in einen von zwei Blöcken einzuteilen:
- Männlich
- Weiblich
Dann würden wir innerhalb jedes Blocks Einzelpersonen nach dem Zufallsprinzip einer von zwei Behandlungen zuordnen:
- Eine neue Diät
- Eine Standarddiät
Auf diese Weise wäre die Variation innerhalb jedes Blocks viel geringer als die Variation zwischen allen Individuen und wir könnten besser verstehen, wie sich die neue Diät auf die Gewichtsabnahme auswirkt und gleichzeitig das Geschlecht kontrolliert.
3. Korrespondenz
Ein Matched-Pair-Design ist eine Art experimentelles Design, bei dem wir Einzelpersonen anhand der Werte potenzieller Störvariablen „zuordnen“.
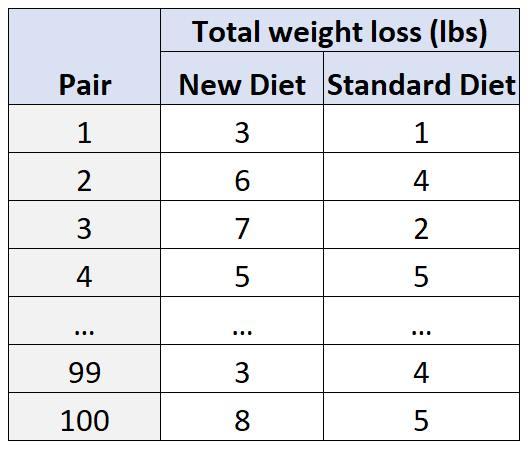
Angenommen, Forscher möchten wissen, wie sich eine neue Diät im Vergleich zu einer Standarddiät auf die Gewichtsabnahme auswirkt. Zwei potenziell verwirrende Variablen in dieser Situation sind Alter und Geschlecht .
Um dies zu berücksichtigen, rekrutieren Forscher 100 Probanden und gruppieren sie dann basierend auf ihrem Alter und Geschlecht in 50 Paare. Zum Beispiel:
- Ein 25-jähriger Mann wird mit einem anderen 25-jährigen Mann zusammengebracht, da beide hinsichtlich Alter und Geschlecht „passen“.
- Eine 30-jährige Frau wird mit einer anderen 30-jährigen Frau zusammengebracht, da sie auch in Bezug auf Alter, Geschlecht usw. übereinstimmen.
Dann wird innerhalb jedes Paares ein Proband nach dem Zufallsprinzip ausgewählt, um 30 Tage lang die neue Diät zu befolgen, und der andere Proband wird zugewiesen, um 30 Tage lang die Standarddiät zu befolgen.
Am Ende der 30 Tage messen die Forscher den Gesamtgewichtsverlust jedes Probanden.
Durch die Verwendung dieser Art von Design können Forscher sicher sein, dass etwaige Unterschiede beim Gewichtsverlust auf die Art der verwendeten Ernährung und nicht auf die Störvariablen Alter und Geschlecht zurückzuführen sind.
Diese Art von Design hat einige Nachteile, darunter:
1. Verlieren Sie zwei Fächer, wenn einer von ihnen ausfällt. Entscheidet sich ein Proband, das Studium abzubrechen, verliert man tatsächlich zwei Probanden, da man kein vollständiges Paar mehr hat.
2. Es braucht Zeit, Übereinstimmungen zu finden . Es kann zeitaufwändig sein, Themen zu finden, die bestimmten Variablen wie Geschlecht und Alter entsprechen.
3. Themen können nicht perfekt zugeordnet werden . Egal wie sehr Sie sich auch bemühen, es wird immer Variationen innerhalb der Motive jedes Paars geben.
Wenn einer Studie jedoch die Ressourcen zur Verfügung stehen, um dieses Design umzusetzen, kann es sehr effektiv sein, die Auswirkungen von Störvariablen zu eliminieren.
Über den Autor
Dr. Benjamin Anderson
Hallo, ich bin Benjamin, ein pensionierter Statistikprofessor, der sich zum engagierten Statorials-Lehrer entwickelt hat. Mit umfassender Erfahrung und Fachwissen auf dem Gebiet der Statistik bin ich bestrebt, mein Wissen zu teilen, um Studenten durch Statorials zu befähigen. Mehr wissen