So zeichnen sie eine roc-kurve in python (schritt für schritt)
Die logistische Regression ist eine statistische Methode, die wir verwenden, um ein Regressionsmodell anzupassen, wenn die Antwortvariable binär ist. Um zu bewerten, wie gut ein logistisches Regressionsmodell zu einem Datensatz passt, können wir uns die folgenden zwei Metriken ansehen:
- Sensitivität: Wahrscheinlichkeit, dass das Modell ein positives Ergebnis für eine Beobachtung vorhersagt, obwohl das Ergebnis tatsächlich positiv ist. Dies wird auch als „True-Positive-Rate“ bezeichnet.
- Spezifität: Die Wahrscheinlichkeit, dass das Modell ein negatives Ergebnis für eine Beobachtung vorhersagt, obwohl das Ergebnis tatsächlich negativ ist. Dies wird auch als „echte Negativrate“ bezeichnet.
Eine Möglichkeit, diese beiden Messungen zu visualisieren, besteht darin, eine ROC-Kurve zu erstellen, die für „Receiver Operating Characteristic“-Kurve steht. Dies ist ein Diagramm, das die Sensitivität und Spezifität eines logistischen Regressionsmodells anzeigt.
Das folgende Schritt-für-Schritt-Beispiel zeigt, wie Sie eine ROC-Kurve in Python erstellen und interpretieren.
Schritt 1: Importieren Sie die erforderlichen Pakete
Zuerst importieren wir die notwendigen Pakete, um eine logistische Regression in Python durchzuführen:
import pandas as pd import numpy as np from sklearn. model_selection import train_test_split from sklearn. linear_model import LogisticRegression from sklearn import metrics import matplotlib. pyplot as plt
Schritt 2: Passen Sie das logistische Regressionsmodell an
Als Nächstes importieren wir einen Datensatz und passen ein logistisches Regressionsmodell daran an:
#import dataset from CSV file on Github
url = "https://raw.githubusercontent.com/Statorials/Python-Guides/main/default.csv"
data = pd. read_csv (url)
#define the predictor variables and the response variable
X = data[[' student ',' balance ',' income ']]
y = data[' default ']
#split the dataset into training (70%) and testing (30%) sets
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3,random_state=0)
#instantiate the model
log_regression = LogisticRegression()
#fit the model using the training data
log_regression. fit (X_train,y_train)
Schritt 3: Zeichnen Sie die ROC-Kurve
Als nächstes berechnen wir die True-Positive-Rate und die False-Positive-Rate und erstellen eine ROC-Kurve mit dem Matplotlib-Datenvisualisierungspaket:
#define metrics
y_pred_proba = log_regression. predict_proba (X_test)[::,1]
fpr, tpr, _ = metrics. roc_curve (y_test, y_pred_proba)
#create ROC curve
plt. plot (fpr,tpr)
plt. ylabel (' True Positive Rate ')
plt. xlabel (' False Positive Rate ')
plt. show ()
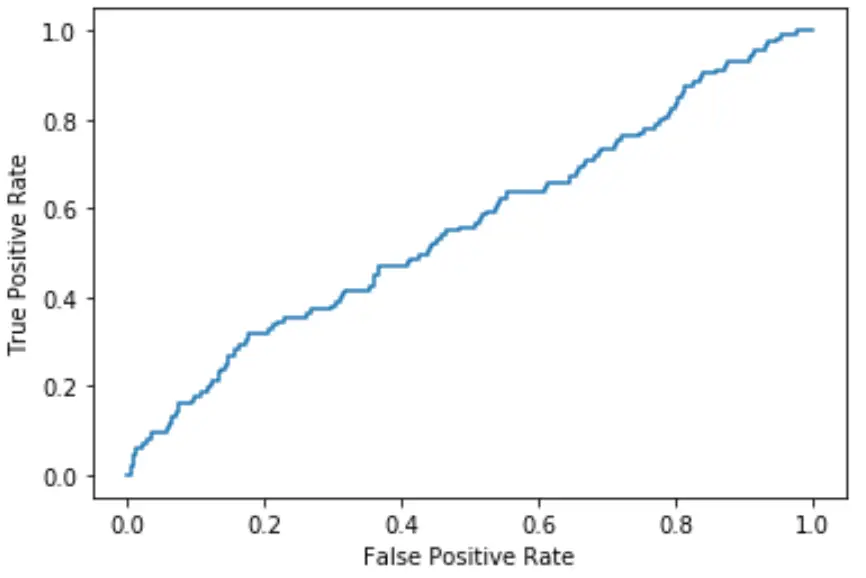
Je näher die Kurve an der oberen linken Ecke des Diagramms liegt, desto besser kann das Modell die Daten in Kategorien einteilen.
Wie wir aus der obigen Grafik ersehen können, gelingt es diesem logistischen Regressionsmodell ziemlich schlecht, die Daten in Kategorien zu sortieren.
Um dies zu quantifizieren, können wir die AUC – Fläche unter der Kurve – berechnen, die uns sagt, wie viel von der Handlung unter der Kurve liegt.
Je näher die AUC bei 1 liegt, desto besser ist das Modell. Ein Modell mit einer AUC von 0,5 ist nicht besser als ein Modell, das zufällige Klassifizierungen durchführt.
Schritt 4: Berechnen Sie die AUC
Wir können den folgenden Code verwenden, um die AUC des Modells zu berechnen und sie in der unteren rechten Ecke des ROC-Diagramms anzuzeigen:
#define metrics
y_pred_proba = log_regression. predict_proba (X_test)[::,1]
fpr, tpr, _ = metrics. roc_curve (y_test, y_pred_proba)
auc = metrics. roc_auc_score (y_test, y_pred_proba)
#create ROC curve
plt. plot (fpr,tpr,label=" AUC= "+str(auc))
plt. ylabel (' True Positive Rate ')
plt. xlabel (' False Positive Rate ')
plt. legend (loc=4)
plt. show ()
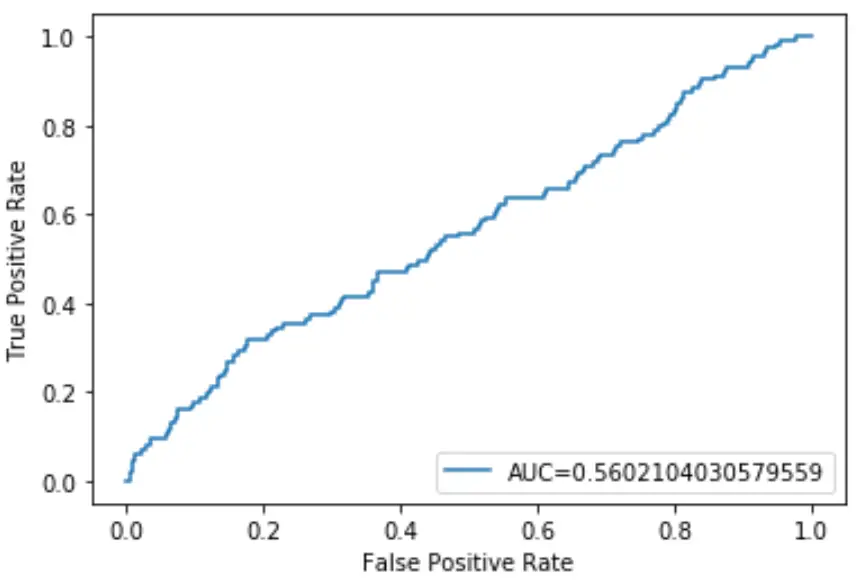
Die AUC dieses logistischen Regressionsmodells beträgt 0,5602 . Da dieser Wert nahe bei 0,5 liegt, bestätigt dies, dass das Modell die Daten schlecht klassifiziert.
Verwandte Themen: So zeichnen Sie mehrere ROC-Kurven in Python
Über den Autor
Dr. Benjamin Anderson
Hallo, ich bin Benjamin, ein pensionierter Statistikprofessor, der sich zum engagierten Statorials-Lehrer entwickelt hat. Mit umfassender Erfahrung und Fachwissen auf dem Gebiet der Statistik bin ich bestrebt, mein Wissen zu teilen, um Studenten durch Statorials zu befähigen. Mehr wissen