Eine kurze einführung in überwachtes und unbeaufsichtigtes lernen
Der Bereich des maschinellen Lernens umfasst eine riesige Menge an Algorithmen, die zum Verstehen von Daten verwendet werden können. Diese Algorithmen können in eine der folgenden zwei Kategorien eingeteilt werden:
1. Algorithmen für überwachtes Lernen: Dazu gehört die Erstellung eines Modells, um ein Ergebnis auf der Grundlage einer oder mehrerer Eingaben abzuschätzen oder vorherzusagen.
2. Algorithmen für unbeaufsichtigtes Lernen: Dazu gehört das Finden von Strukturen und Beziehungen aus Eingaben. Es gibt keinen „Supervision“-Ausgang.
In diesem Tutorial werden die Unterschiede zwischen diesen beiden Arten von Algorithmen anhand mehrerer Beispiele erläutert.
Überwachte Lernalgorithmen
Ein überwachter Lernalgorithmus kann verwendet werden , wenn wir eine oder mehrere erklärende Variablen haben ( X1, die Antwortvariable:
Y = f (X) + ε
Dabei stellt f die systematische Information dar, die X über Y liefert, und ε ist ein von X unabhängiger Zufallsfehlerterm mit einem Mittelwert von Null.
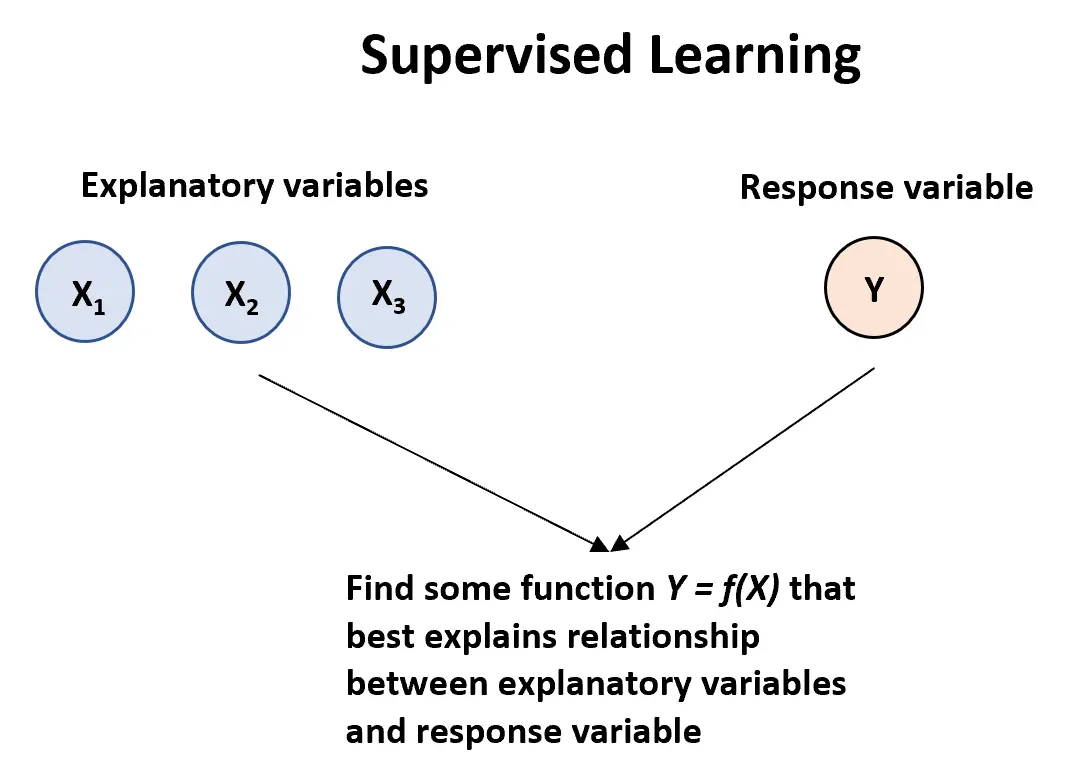
Es gibt zwei Haupttypen von überwachten Lernalgorithmen:
1. Regression: Die Ausgabevariable ist kontinuierlich (z. B. Gewicht, Größe, Zeit usw.)
2. Klassifizierung: Die Ausgabevariable ist kategorisch (z. B. männlich oder weiblich, Erfolg oder Misserfolg, gutartig oder bösartig usw.)
Es gibt zwei Hauptgründe, warum wir überwachte Lernalgorithmen verwenden:
1. Vorhersage: Wir verwenden häufig eine Reihe erklärender Variablen, um den Wert einer Antwortvariablen vorherzusagen (z. B. verwenden wir die Quadratmeterzahl und die Anzahl der Schlafzimmer , um den Preis eines Hauses vorherzusagen).
2. Schlussfolgerung: Wir könnten daran interessiert sein zu verstehen, wie eine Antwortvariable beeinflusst wird, wenn sich der Wert der erklärenden Variablen ändert (z. B. um wie viel erhöht sich der Immobilienpreis im Durchschnitt, wenn die Anzahl der Zimmer um eins steigt?)
Je nachdem, ob unser Ziel Inferenz oder Vorhersage (oder eine Mischung aus beidem) ist, können wir unterschiedliche Methoden verwenden, um die Funktion f zu schätzen. Beispielsweise bieten lineare Modelle eine einfachere Interpretation, schwer zu interpretierende nichtlineare Modelle können jedoch genauere Vorhersagen liefern.
Hier ist eine Liste der am häufigsten verwendeten überwachten Lernalgorithmen:
- Lineare Regression
- Logistische Regression
- Lineare Diskriminanzanalyse
- Quadratische Diskriminanzanalyse
- Entscheidungsbäume
- Naiver Bayes
- Support-Vektor-Maschinen
- Neuronale Netze
Unüberwachte Lernalgorithmen
Ein unbeaufsichtigter Lernalgorithmus kann verwendet werden, wenn wir eine Liste von Variablen ( X 1 , Daten) haben.
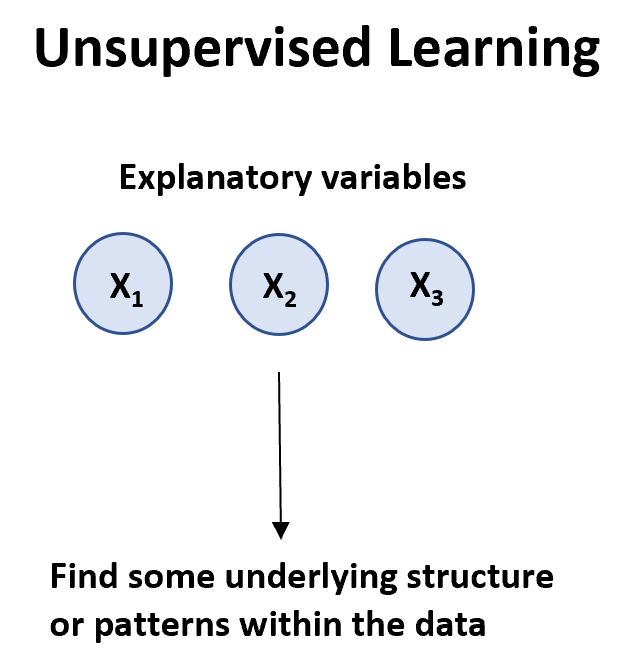
Es gibt zwei Haupttypen von unbeaufsichtigten Lernalgorithmen:
1. Clustering: Mithilfe dieser Art von Algorithmen versuchen wir, „Cluster“ von Beobachtungen in einem Datensatz zu finden, die einander ähnlich sind. Dies wird häufig im Einzelhandel verwendet, wenn ein Unternehmen Kundengruppen mit ähnlichen Kaufgewohnheiten identifizieren möchte, um spezifische Marketingstrategien für bestimmte Kundengruppen entwickeln zu können.
2. Assoziation: Mithilfe dieser Art von Algorithmen versuchen wir, „Regeln“ zu finden, mit denen Assoziationen hergestellt werden können. Einzelhändler können beispielsweise einen Assoziationsalgorithmus entwickeln, der besagt: „Wenn ein Kunde Produkt X kauft, wird er mit hoher Wahrscheinlichkeit auch Produkt Y kaufen.“
Hier ist eine Liste der am häufigsten verwendeten unbeaufsichtigten Lernalgorithmen:
- Hauptkomponentenanalyse
- K-bedeutet Clustering
- Gruppierung von K-Medoiden
- Hierarchische Klassifizierung
- A-priori-Algorithmus
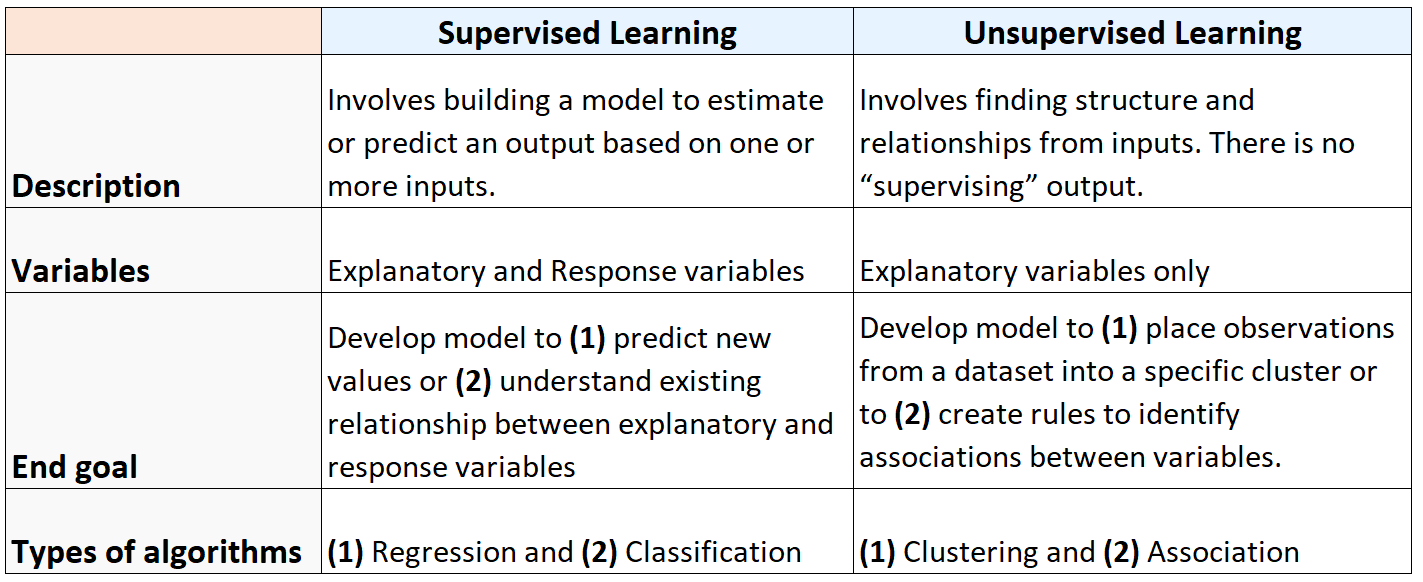
Zusammenfassung: Überwachtes oder unbeaufsichtigtes Lernen
Die folgende Tabelle fasst die Unterschiede zwischen überwachten und unüberwachten Lernalgorithmen zusammen:
Und das folgende Diagramm fasst die Arten von Algorithmen für maschinelles Lernen zusammen:

Über den Autor
Dr. Benjamin Anderson
Hallo, ich bin Benjamin, ein pensionierter Statistikprofessor, der sich zum engagierten Statorials-Lehrer entwickelt hat. Mit umfassender Erfahrung und Fachwissen auf dem Gebiet der Statistik bin ich bestrebt, mein Wissen zu teilen, um Studenten durch Statorials zu befähigen. Mehr wissen