So führen sie eine univariate analyse in r durch (mit beispielen)
Der Begriff univariate Analyse bezieht sich auf die Analyse einer Variablen. Sie können sich das merken, denn das Präfix „uni“ bedeutet „eins“.
Es gibt drei gängige Methoden zur Durchführung einer univariaten Analyse einer Variablen:
1. Zusammenfassungsstatistik – Misst die Mitte und Verteilung der Werte.
2. Häufigkeitstabelle – Beschreibt, wie oft unterschiedliche Werte auftreten.
3. Diagramme – werden zur Visualisierung der Werteverteilung verwendet.
Dieses Tutorial enthält ein Beispiel für die Durchführung einer univariaten Analyse für die folgende Variable:
#create variable with 15 values
x <- c(1, 1, 2, 3.5, 4, 4, 4, 5, 5, 6.5, 7, 7.4, 8, 13, 14.2)
Zusammengefasste Statistiken
Mit der folgenden Syntax können wir verschiedene zusammenfassende Statistiken für unsere Variable berechnen:
#find means mean(x) [1] 5.706667 #find median median(x) [1] 5 #find range max(x) - min(x) [1] 13.2 #find interquartile range (spread of middle 50% of values) IQR(x) [1] 3.45 #find standard deviation sd(x) [1] 3.858287
Häufigkeitstabelle
Mit der folgenden Syntax können wir eine Häufigkeitstabelle für unsere Variable erstellen:
#produce frequency table
table(s)
1 2 3.5 4 5 6.5 7 7.4 8 13 14.2
2 1 1 3 2 1 1 1 1 1 1
Dies sagt uns Folgendes:
- Der Wert 1 erscheint zweimal
- Der Wert 2 erscheint 1 Mal
- Der Wert 3,5 erscheint 1 Mal
Und so weiter.
Grafik
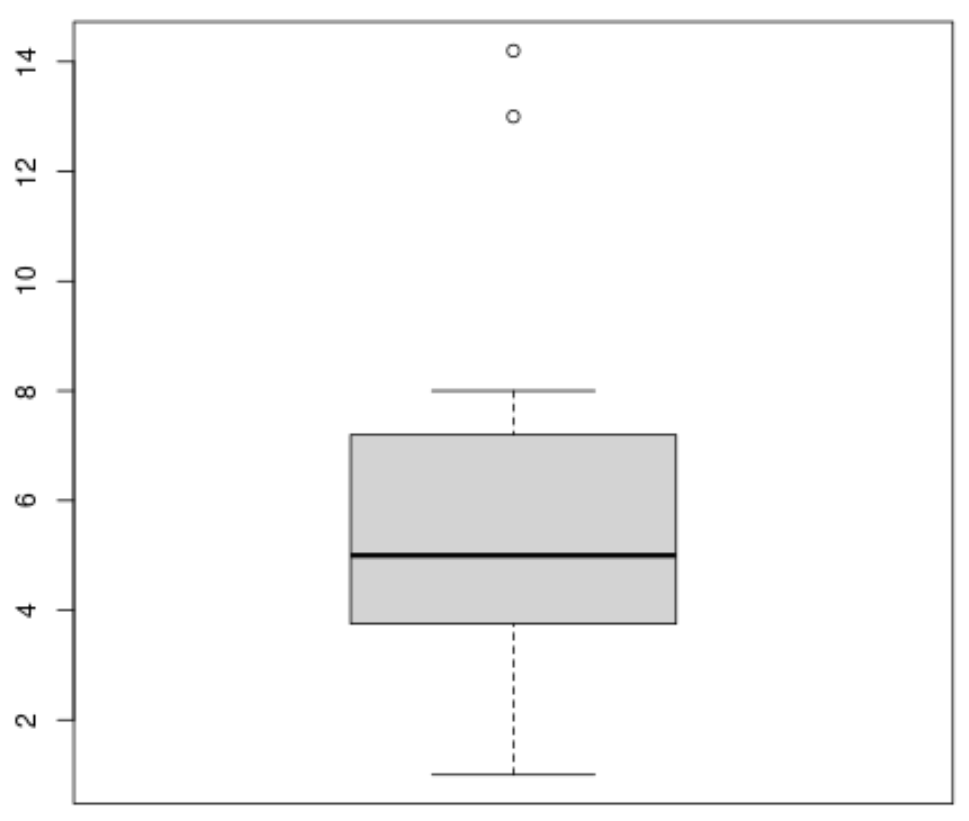
Wir können einen Boxplot mit der folgenden Syntax erstellen:
#produce boxplot
boxplot(x)
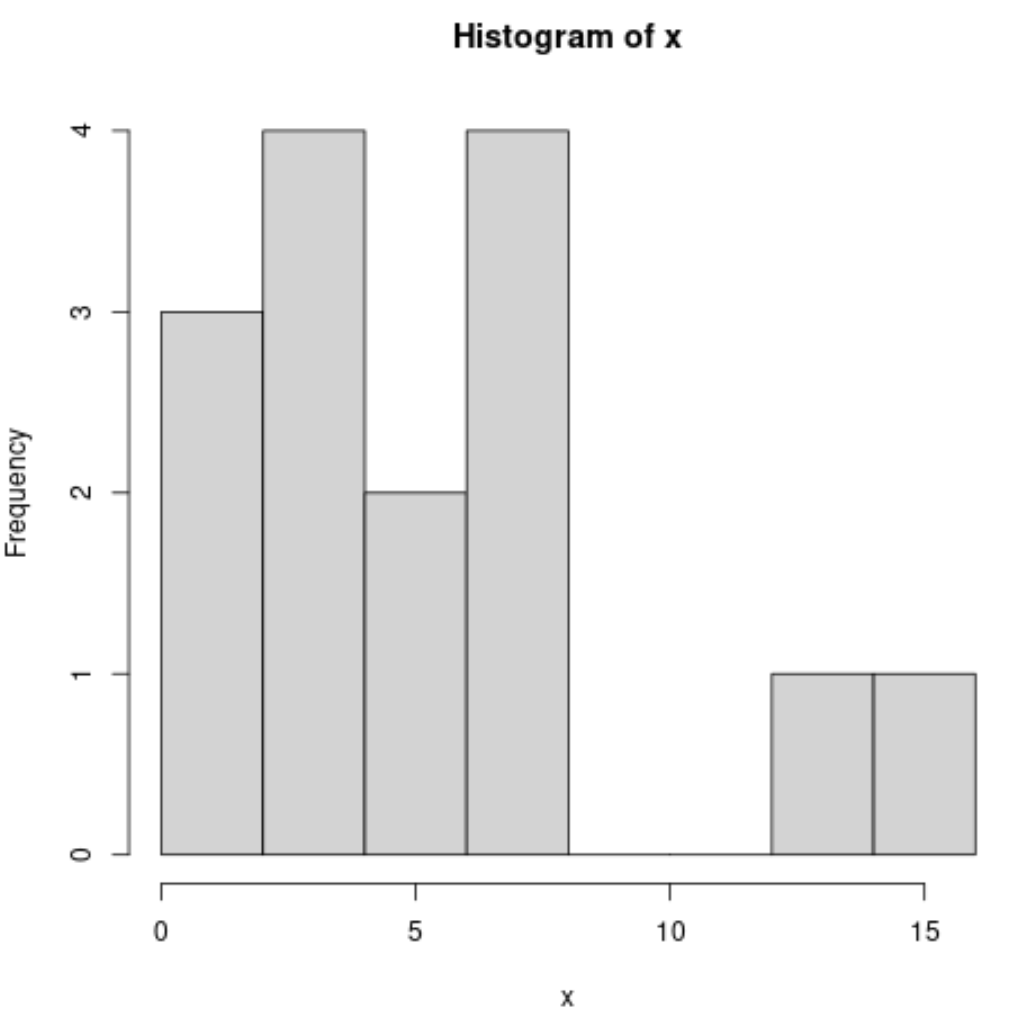
Wir können ein Histogramm mit der folgenden Syntax erstellen:
#produce histogram
hist(x)
Mit der folgenden Syntax können wir eine Dichtekurve erstellen:
#produce density curve
plot(density(x))
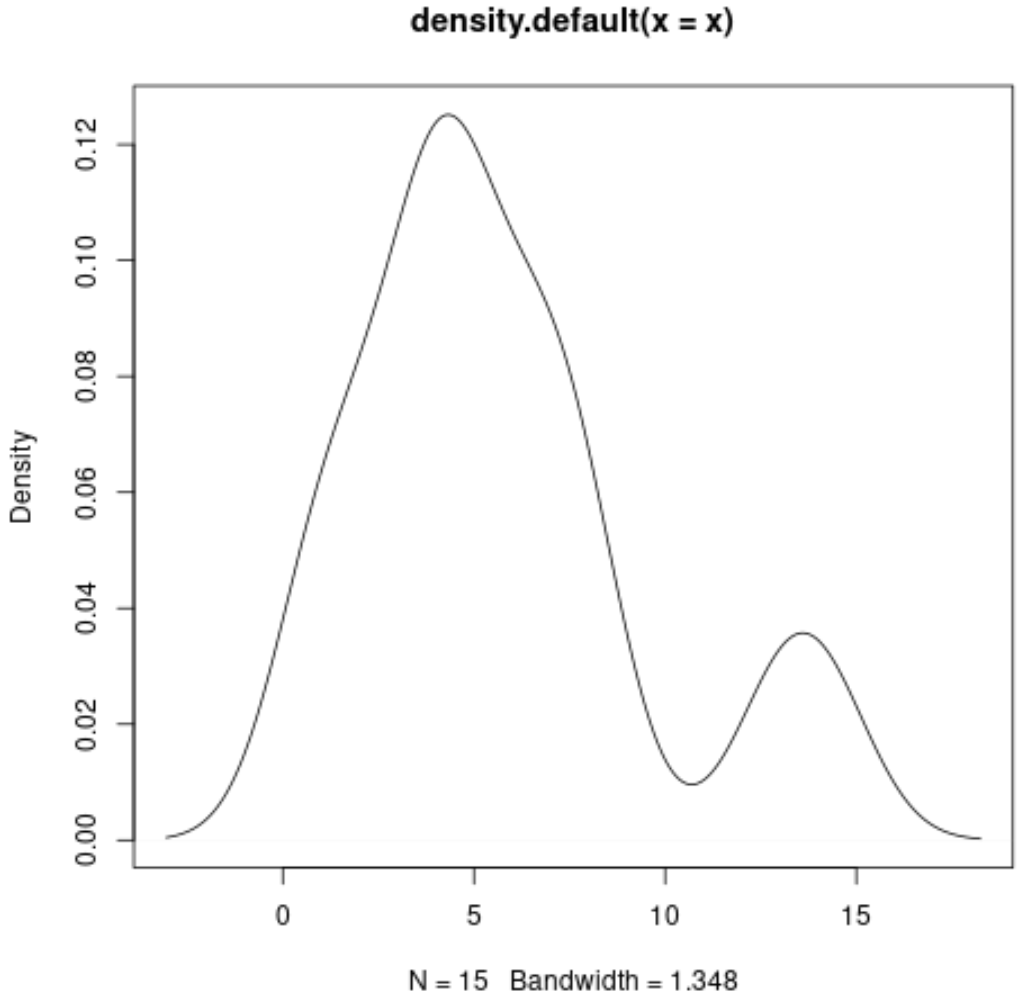
Jedes dieser Diagramme bietet uns eine einzigartige Möglichkeit, die Werteverteilung unserer Variablen zu visualisieren.
Weitere R-Tutorials finden Sie auf dieser Seite .
Über den Autor
Dr. Benjamin Anderson
Hallo, ich bin Benjamin, ein pensionierter Statistikprofessor, der sich zum engagierten Statorials-Lehrer entwickelt hat. Mit umfassender Erfahrung und Fachwissen auf dem Gebiet der Statistik bin ich bestrebt, mein Wissen zu teilen, um Studenten durch Statorials zu befähigen. Mehr wissen