So erhalten sie vorhergesagte werte und residuen in stata
Die lineare Regression ist eine Methode, mit der wir die Beziehung zwischen einer oder mehreren erklärenden Variablen und einer Antwortvariablen verstehen können.
Wenn wir eine lineare Regression für einen Datensatz durchführen, erhalten wir eine Regressionsgleichung, mit der wir die Werte einer Antwortvariablen anhand der Werte der erklärenden Variablen vorhersagen können.
Anschließend können wir die Differenz zwischen den vorhergesagten Werten und den tatsächlichen Werten messen, um die Residuen für jede Vorhersage zu erhalten. Dies hilft uns, eine Vorstellung davon zu bekommen, wie gut unser Regressionsmodell Antwortwerte vorhersagt.
In diesem Tutorial wird erläutert, wie Sie sowohl vorhergesagte Werte als auch Residuen für ein Regressionsmodell in Stata erhalten.
Beispiel: So erhalten Sie vorhergesagte Werte und Residuen
Für dieses Beispiel verwenden wir den integrierten Stata-Datensatz namens auto . Wir werden mpg und Hubraum als erklärende Variablen und den Preis als Antwortvariable verwenden.
Führen Sie die folgenden Schritte aus, um eine lineare Regression durchzuführen und dann die vorhergesagten Werte und Residuen für das Regressionsmodell zu erhalten.
Schritt 1: Daten laden und anzeigen.
Zuerst laden wir die Daten mit dem folgenden Befehl:
automatische Nutzung des Systems
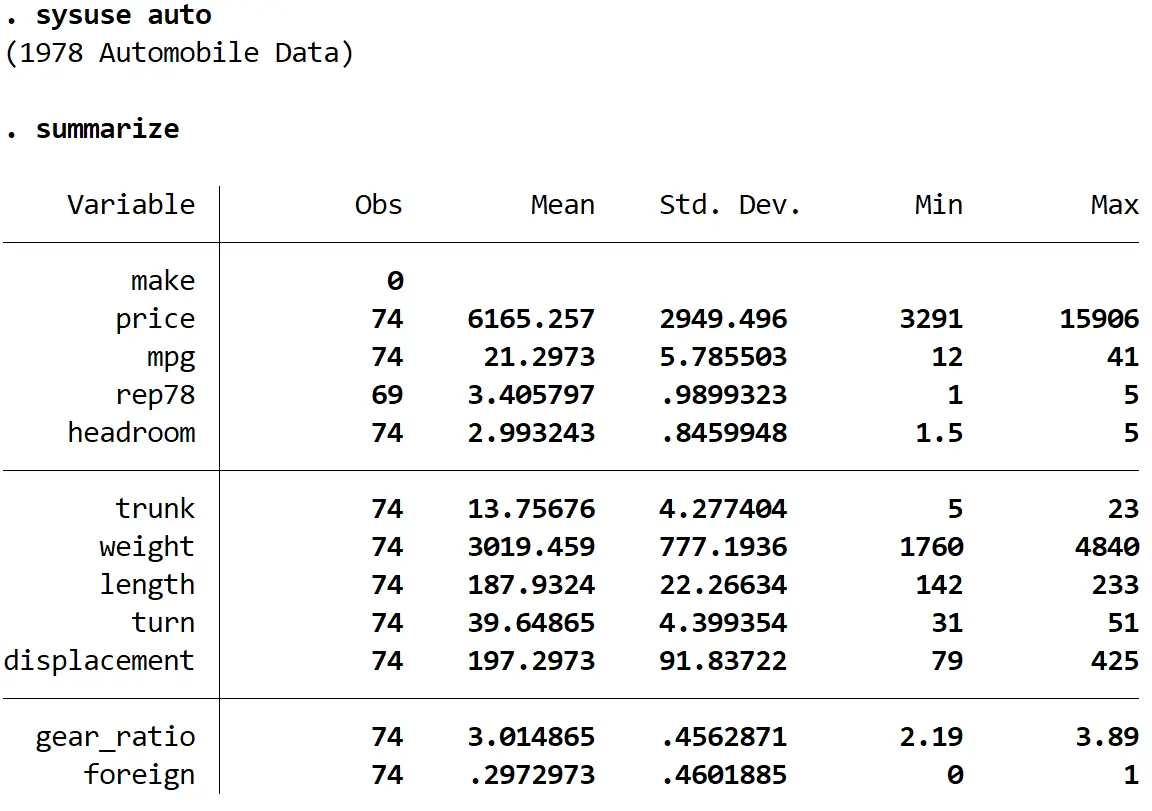
Als nächstes erhalten wir mit dem folgenden Befehl eine kurze Zusammenfassung der Daten:
zusammenfassen
Schritt 2: Passen Sie das Regressionsmodell an.
Als nächstes verwenden wir den folgenden Befehl, um das Regressionsmodell anzupassen:
Regressionspreis mpg Hubraum
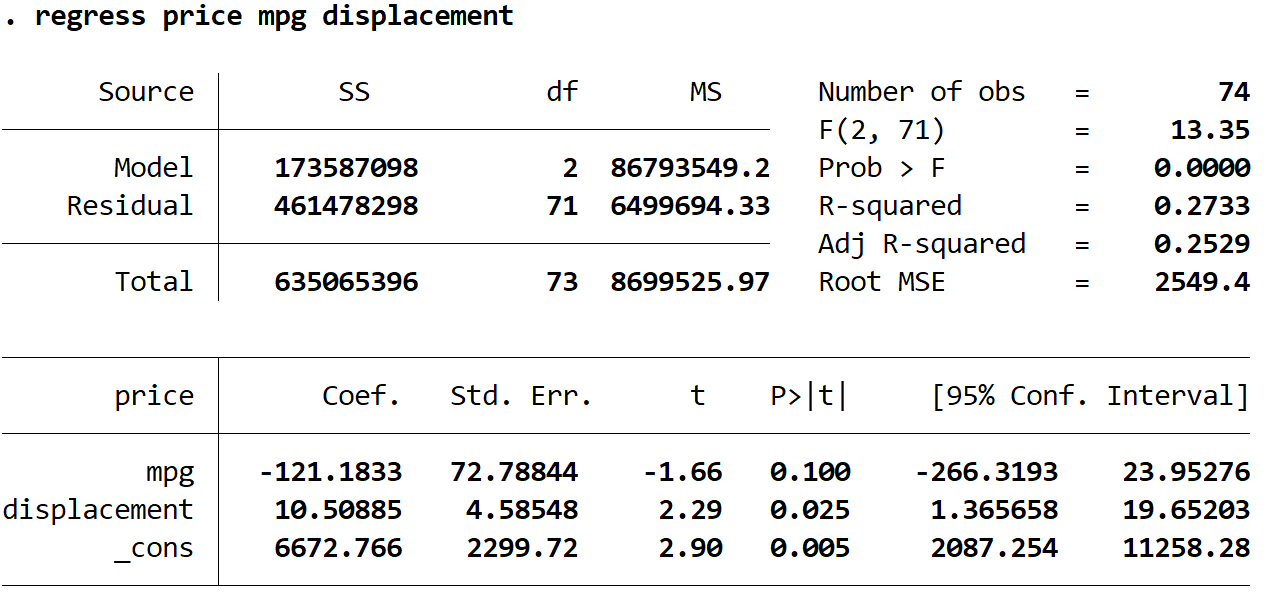
Die geschätzte Regressionsgleichung lautet:
geschätzter Preis = 6672,766 -121,1833*(mpg) + 10,50885*(Hubraum)
Schritt 3: Ermitteln Sie die vorhergesagten Werte.
Wir können die vorhergesagten Werte erhalten, indem wir den Befehl „predict“ verwenden und diese Werte in einer Variablen mit einem beliebigen Namen speichern. In diesem Fall verwenden wir den Namen pred_price :
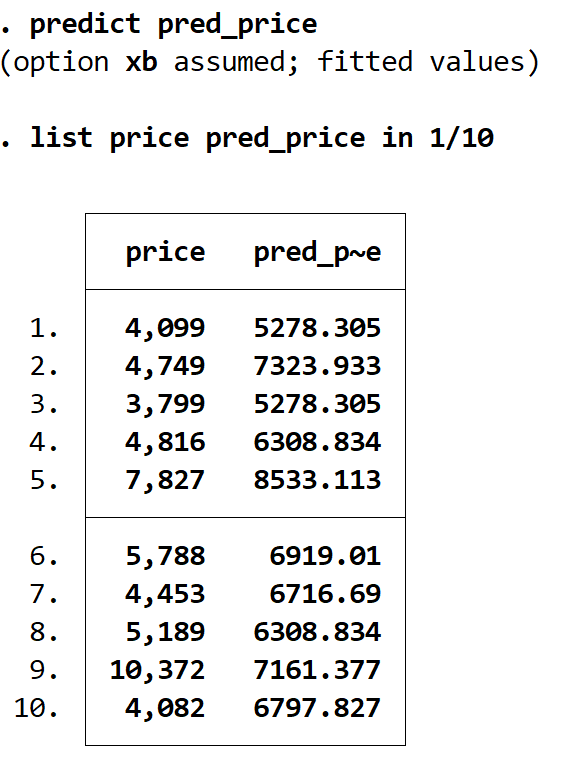
pred_price vorhersagen
Mit dem Listenbefehl können wir tatsächliche Preise und vorhergesagte Preise nebeneinander anzeigen. Insgesamt gibt es 74 vorhergesagte Werte, wir zeigen jedoch nur die ersten 10 mit dem Befehl in 1/10 an:
Listenpreis pred_price in 1/10
Schritt 4: Holen Sie sich den Rückstand.
Wir können die Residuen jeder Vorhersage erhalten, indem wir den Befehl „Residuen“ verwenden und diese Werte in einer Variablen mit einem beliebigen Namen speichern. In diesem Fall verwenden wir den Namen resid_price :
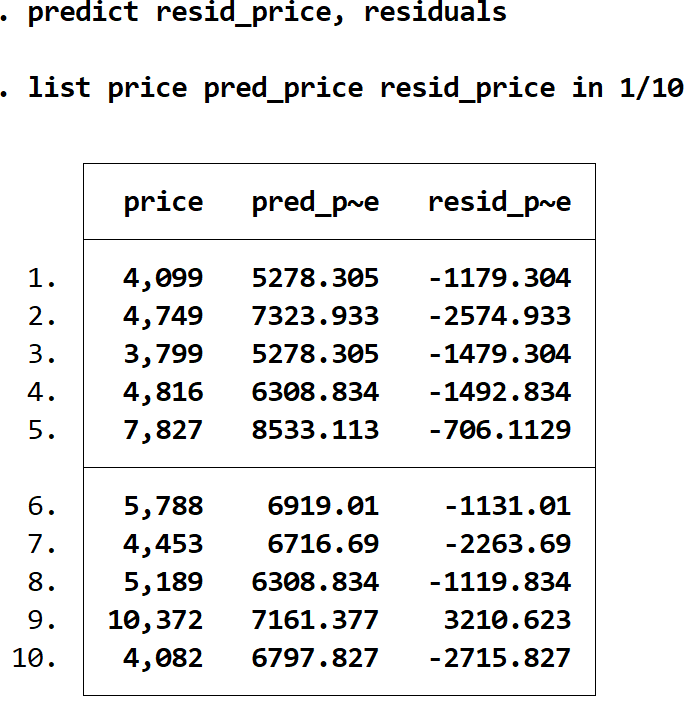
prognostizieren Sie den Residenzpreis und die Residuen
Wir können den tatsächlichen Preis, den erwarteten Preis und die Residuen nebeneinander anzeigen, indem wir erneut den Befehl list verwenden:
Listenpreis pred_price resid_price in 1/10
Schritt 5: Erstellen Sie ein Diagramm der vorhergesagten Werte gegenüber den Residuen.
Schließlich können wir ein Streudiagramm erstellen, um die Beziehung zwischen den vorhergesagten Werten und den Residuen zu visualisieren:
Streuung resident_price pred_price
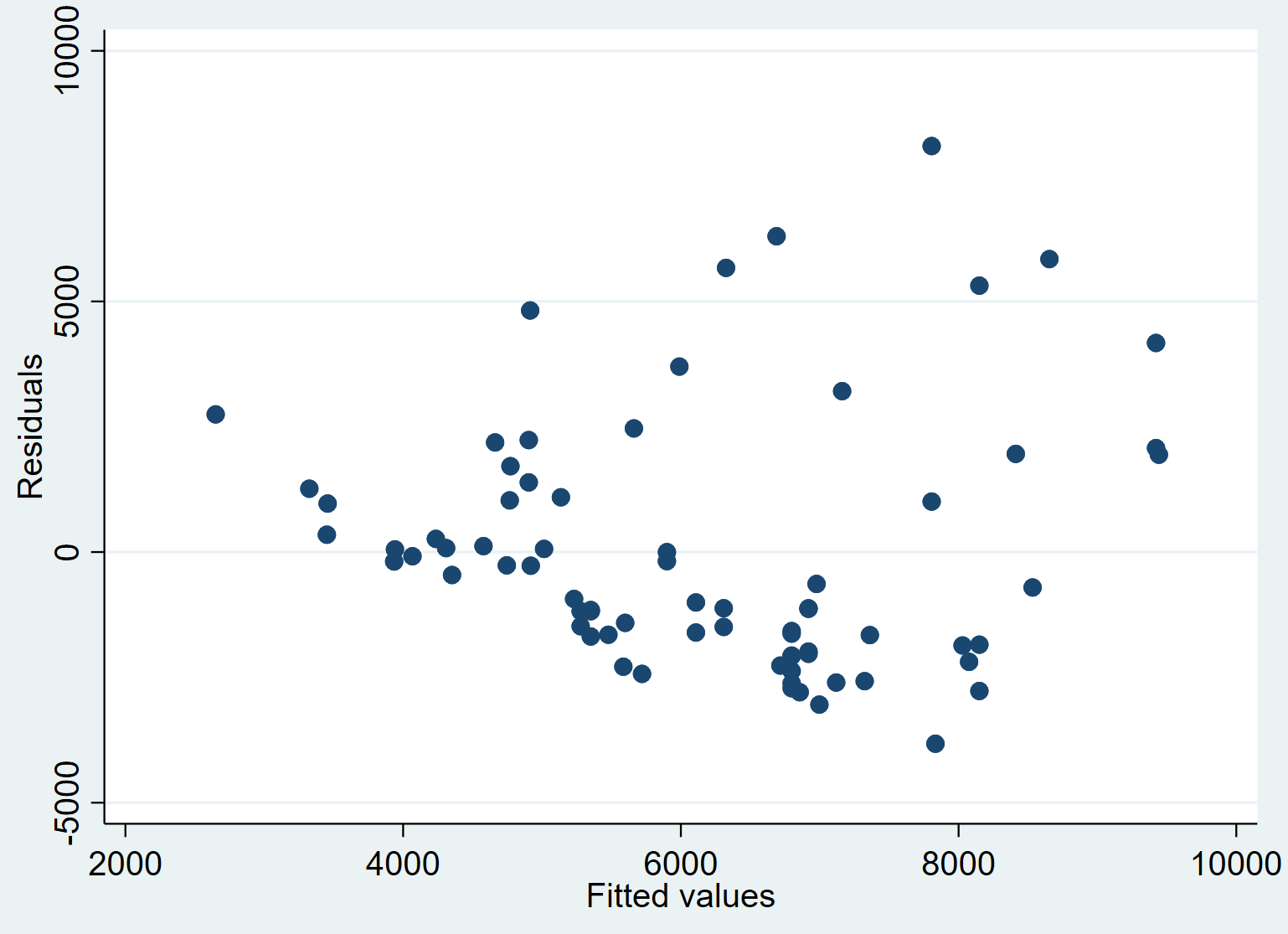
Wir können sehen, dass die Residuen im Durchschnitt tendenziell zunehmen, wenn die angepassten Werte zunehmen. Dies könnte ein Zeichen für Heteroskedastizität sein – wenn die Verteilung der Residuen nicht auf jeder Antwortebene konstant ist.
Wir könnten mithilfe des Breusch-Pagan-Tests formal auf Heteroskedastizität testen und dies mithilferobuster Standardfehler beheben.
Über den Autor
Dr. Benjamin Anderson
Hallo, ich bin Benjamin, ein pensionierter Statistikprofessor, der sich zum engagierten Statorials-Lehrer entwickelt hat. Mit umfassender Erfahrung und Fachwissen auf dem Gebiet der Statistik bin ich bestrebt, mein Wissen zu teilen, um Studenten durch Statorials zu befähigen. Mehr wissen