Was gilt als „gut“? f1-ergebnis?
Bei der Verwendung von Klassifizierungsmodellen beim maschinellen Lernen ist der F1-Score eine gängige Metrik, die wir zur Bewertung der Modellqualität verwenden.
Diese Metrik wird wie folgt berechnet:
F1-Score = 2 * (Präzision * Rückruf) / (Präzision + Rückruf)
Gold:
- Genauigkeit : Korrigieren Sie positive Vorhersagen im Verhältnis zur Gesamtzahl der positiven Vorhersagen
- Erinnerung : Korrigieren Sie positive Vorhersagen anhand der gesamten tatsächlichen positiven Ergebnisse
Angenommen, wir verwenden ein logistisches Regressionsmodell, um vorherzusagen, ob 400 verschiedene College-Basketballspieler in die NBA eingezogen werden oder nicht.
Die folgende Verwirrungsmatrix fasst die vom Modell getroffenen Vorhersagen zusammen:

So berechnen Sie den F1-Score des Modells:
Genauigkeit = Richtig positiv / (Richtig positiv + Falsch positiv) = 120/ (120+70) = 0,63157
Rückruf = Richtig positiv / (Richtig positiv + Falsch negativ) = 120 / (120+40) = 0,75
F1-Score = 2 * (.63157 * .75) / (.63157 + .75) = . 6857
Was ist ein gutes F1-Ergebnis?
Eine Frage, die Studenten oft stellen, ist:
Was ist ein gutes Ergebnis in der Formel 1?
Einfach ausgedrückt sind höhere F1-Ergebnisse im Allgemeinen besser.
Denken Sie daran, dass F1-Scores zwischen 0 und 1 liegen können, wobei 1 ein Modell darstellt, das jede Beobachtung perfekt in die richtige Klasse einordnet, und 0 ein Modell darstellt, das eine Beobachtung nicht in die richtige Klasse einordnen kann.
Um dies zu veranschaulichen, nehmen wir an, wir hätten ein logistisches Regressionsmodell, das die folgende Verwirrungsmatrix erzeugt:
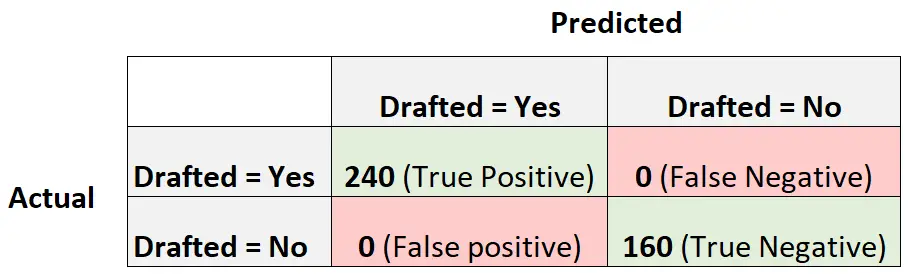
So berechnen Sie den F1-Score des Modells:
Genauigkeit = Richtig positiv / (Richtig positiv + Falsch positiv) = 240/ (240+0) = 1
Rückruf = Richtig positiv / (Richtig positiv + Falsch negativ) = 240 / (240+0) = 1
F1-Score = 2 * (1 * 1) / (1 + 1) = 1
Der F1-Score ist gleich eins, da er jede der 400 Beobachtungen perfekt in eine Klasse einordnen kann.
Betrachten Sie nun ein weiteres logistisches Regressionsmodell, das einfach vorhersagt, dass jeder Spieler eingezogen wird:
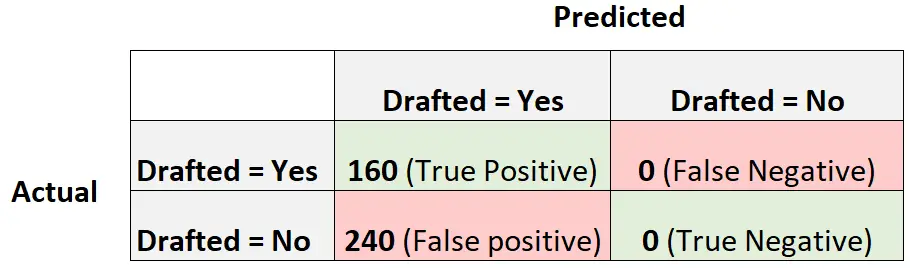
So berechnen Sie den F1-Score des Modells:
Genauigkeit = Richtig positiv / (Richtig positiv + Falsch positiv) = 160/ (160+240) = 0,4
Rückruf = Richtig positiv / (Richtig positiv + Falsch negativ) = 160 / (160+0) = 1
F1-Score = 2 * (.4 * 1) / (.4 + 1) = 0,5714
Dies würde als Basismodell betrachtet, mit dem wir unser logistisches Regressionsmodell vergleichen könnten, da es ein Modell darstellt, das für jede Beobachtung im Datensatz die gleiche Vorhersage trifft.
Je höher unser F1-Score im Vergleich zu einem Referenzmodell ist, desto nützlicher ist unser Modell.
Erinnern Sie sich an früher, dass unser Modell einen F1-Score von 0,6857 hatte. Dies ist nicht viel höher als 0,5714 , was darauf hindeutet, dass unser Modell nützlicher ist als ein Basismodell, aber nicht viel.
Beim Vergleich der F1-Ergebnisse
In der Praxis verwenden wir normalerweise den folgenden Prozess, um das „beste“ Modell für ein Klassifizierungsproblem auszuwählen:
Schritt 1: Passen Sie ein Referenzmodell an, das für jede Beobachtung die gleiche Vorhersage macht.
Schritt 2: Passen Sie mehrere verschiedene Klassifizierungsmodelle an und berechnen Sie den F1-Score für jedes Modell.
Schritt 3: Wählen Sie das Modell mit der höchsten F1-Bewertung als „bestes“ Modell aus und stellen Sie sicher, dass es eine höhere F1-Bewertung als das Referenzmodell erzielt.
Kein bestimmter Wert gilt als „guter“ F1-Score, daher wählen wir im Allgemeinen das Klassifizierungsmodell, das den höchsten F1-Score liefert.
Zusätzliche Ressourcen
F1-Score vs. Genauigkeit: Was sollten Sie verwenden?
So berechnen Sie den F1-Score in R
So berechnen Sie den F1-Score in Python
Über den Autor
Dr. Benjamin Anderson
Hallo, ich bin Benjamin, ein pensionierter Statistikprofessor, der sich zum engagierten Statorials-Lehrer entwickelt hat. Mit umfassender Erfahrung und Fachwissen auf dem Gebiet der Statistik bin ich bestrebt, mein Wissen zu teilen, um Studenten durch Statorials zu befähigen. Mehr wissen