Zufällige auswahl oder zufällige zuweisung
Zufällige Auswahl und zufällige Zuweisung sind zwei häufig verwendete, aber oft verwechselte statistische Techniken.
Unter Zufallsauswahl versteht man den Prozess der zufälligen Auswahl von Personen aus einer Population, die an einer Studie beteiligt werden sollen.
Unter „Zufallszuordnung“ versteht man den Prozess der zufälligen Zuteilung von Personen, die an einer Studie teilnehmen, einer Behandlungsgruppe oder einer Kontrollgruppe.
Sie können sich Zufallsauswahl als den Prozess vorstellen, mit dem Sie Einzelpersonen in eine Studie „einbeziehen“, und Sie können sich Zufallszuweisung als das vorstellen, was Sie mit diesen Personen „tun“, sobald sie für die Teilnahme an der Studie ausgewählt wurden.
Die Bedeutung der zufälligen Auswahl und zufälligen Zuweisung
Wenn eine Studie eine Zufallsauswahl verwendet, wählt sie mithilfe eines Zufallsprozesses Personen aus einer Population aus. Wenn eine Population beispielsweise 1.000 Individuen umfasst, könnten wir einen Computer verwenden, um 100 dieser Individuen zufällig aus einer Datenbank auszuwählen. Dies bedeutet, dass jede Person die gleiche Wahrscheinlichkeit hat, für die Teilnahme an der Studie ausgewählt zu werden, was die Chancen erhöht, eine repräsentative Stichprobe zu erhalten – eine Stichprobe mit ähnlichen Merkmalen wie die Allgemeinbevölkerung.
Durch die Verwendung einer repräsentativen Stichprobe in unserer Studie können wir die Ergebnisse unserer Studie auf die Bevölkerung übertragen. Statistisch gesehen nennt man dies externe Validität – es ist gültig, unsere Ergebnisse auf die allgemeine Bevölkerung zu externalisieren.
Wenn eine Studie eine Zufallszuordnung verwendet, werden Personen nach dem Zufallsprinzip einer Behandlungsgruppe oder einer Kontrollgruppe zugeordnet. Wenn wir beispielsweise 100 Personen in einer Studie haben, könnten wir einen Zufallszahlengenerator verwenden, um 50 Personen nach dem Zufallsprinzip einer Kontrollgruppe und 50 Personen einer Behandlungsgruppe zuzuordnen.
Durch die zufällige Zuordnung erhöhen wir die Wahrscheinlichkeit, dass die beiden Gruppen ungefähr ähnliche Merkmale aufweisen, was bedeutet, dass alle beobachteten Unterschiede zwischen den beiden Gruppen auf die Behandlung zurückgeführt werden können. Dies bedeutet, dass die Studie interne Gültigkeit hat: Es ist zulässig, etwaige Unterschiede zwischen Gruppen auf die Behandlung selbst zurückzuführen, im Gegensatz zu Unterschieden zwischen Einzelpersonen in den Gruppen.
Beispiele für zufällige Auswahl und zufällige Zuweisung
Es ist möglich, dass eine Studie sowohl Zufallsauswahl als auch Zufallszuordnung oder nur eine dieser Techniken oder keine der beiden Techniken verwendet. Eine starke Studie ist eine, die beide Techniken verwendet.
Die folgenden Beispiele zeigen, wie eine Studie beide, eine oder keine dieser Techniken nutzen könnte und welche Auswirkungen sich daraus ergeben.
Beispiel 1: Verwendung von Zufallsauswahl und Zufallszuweisung
Studie: Forscher wollen wissen, ob eine neue Diät in einer bestimmten Gemeinschaft von 10.000 Menschen zu einem größeren Gewichtsverlust führt als eine Standarddiät. Sie rekrutieren 100 Personen für die Teilnahme an der Studie, indem sie mithilfe eines Computers zufällig 100 Namen aus einer Datenbank auswählen. Sobald sie alle 100 Personen haben, verwenden sie erneut einen Computer, um 50 Personen nach dem Zufallsprinzip einer Kontrollgruppe (z. B. Einhaltung ihrer Standarddiät) und 50 Personen einer Behandlungsgruppe (z. B. Einhaltung der neuen Diät) zuzuordnen. Sie erfassen den Gesamtgewichtsverlust jedes Einzelnen nach einem Monat.
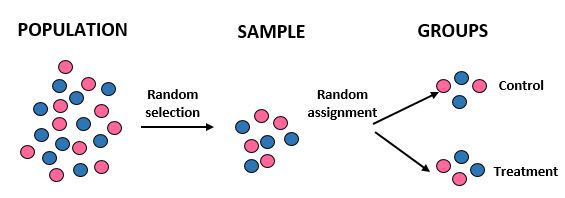
Ergebnisse: Die Forscher verwendeten eine Zufallsauswahl, um ihre Stichprobe zu erhalten, und eine zufällige Zuordnung, wenn sie Personen einer Behandlungs- oder Kontrollgruppe zuordneten. Dadurch sind sie in der Lage, die Studienergebnisse auf die Gesamtbevölkerung zu übertragen und die Unterschiede im durchschnittlichen Gewichtsverlust zwischen den beiden Gruppen auf die neue Ernährung zurückzuführen.
Beispiel 2: Verwenden Sie nur eine zufällige Auswahl
Studie: Forscher wollen wissen, ob eine neue Diät in einer bestimmten Gemeinschaft von 10.000 Menschen zu einem größeren Gewichtsverlust führt als eine Standarddiät. Sie rekrutieren 100 Personen für die Teilnahme an der Studie, indem sie mithilfe eines Computers zufällig 100 Namen aus einer Datenbank auswählen. Sie beschließen jedoch, Einzelpersonen ausschließlich nach ihrem Geschlecht in Gruppen einzuteilen. Frauen werden der Kontrollgruppe und Männer der Behandlungsgruppe zugeordnet. Sie erfassen den Gesamtgewichtsverlust jedes Einzelnen nach einem Monat.
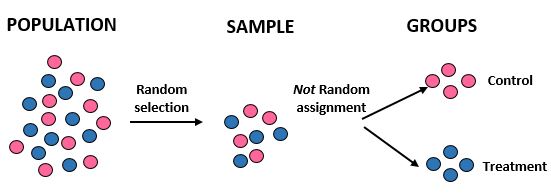
Ergebnisse: Die Forscher nutzten eine Zufallsauswahl, um ihre Stichprobe zu erhalten, verwendeten jedoch keine zufällige Zuordnung, als sie Personen einer Behandlungs- oder Kontrollgruppe zuordneten. Stattdessen verwendeten sie einen bestimmten Faktor – das Geschlecht –, um zu entscheiden, welcher Gruppe die einzelnen Personen zugeordnet werden sollten. Damit sind sie in der Lage, die Studienergebnisse auf die Gesamtbevölkerung zu übertragen, sie sind jedoch nicht in der Lage, die Unterschiede im durchschnittlichen Gewichtsverlust zwischen den beiden Gruppen auf die neue Ernährung zurückzuführen. Die interne Validität der Studie wurde beeinträchtigt, da der Unterschied beim Gewichtsverlust möglicherweise einfach auf das Geschlecht und nicht auf die neue Ernährung zurückzuführen ist.
Beispiel 3: Verwenden Sie nur eine zufällige Zuweisung
Studie: Forscher wollen wissen, ob eine neue Diät in einer bestimmten Gemeinschaft von 10.000 Menschen zu einem größeren Gewichtsverlust führt als eine Standarddiät. Sie rekrutieren 100 männliche Sportler, um an der Studie teilzunehmen. Anschließend weisen sie mithilfe eines Computerprogramms nach dem Zufallsprinzip 50 männliche Sportler einer Kontrollgruppe und 50 der Behandlungsgruppe zu. Sie erfassen den Gesamtgewichtsverlust jedes Einzelnen nach einem Monat.
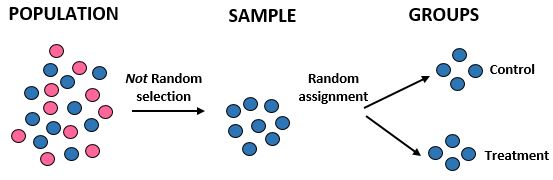
Ergebnisse: Die Forscher nutzten zur Gewinnung ihrer Stichprobe keine Zufallsauswahl, da sie gezielt 100 männliche Sportler auswählten. Aus diesem Grund ist ihre Stichprobe nicht repräsentativ für die Gesamtbevölkerung und ihre externe Validität ist daher beeinträchtigt – sie werden nicht in der Lage sein, die Studienergebnisse auf die Gesamtbevölkerung zu übertragen. Allerdings verwendeten sie eine zufällige Zuordnung, was bedeutet, dass sie jeden Unterschied im Gewichtsverlust auf die neue Ernährung zurückführen können.
Beispiel 4: Keine der beiden Techniken verwenden
Studie: Forscher wollen wissen, ob eine neue Diät in einer bestimmten Gemeinschaft von 10.000 Menschen zu einem größeren Gewichtsverlust führt als eine Standarddiät. Sie rekrutieren 50 männliche und 50 weibliche Sportler für die Teilnahme an der Studie. Anschließend ordnen sie alle Sportlerinnen der Kontrollgruppe und alle männlichen Sportler der Behandlungsgruppe zu. Sie erfassen den Gesamtgewichtsverlust jedes Einzelnen nach einem Monat.
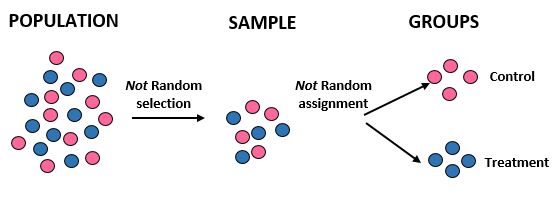
Ergebnisse: Die Forscher nutzten zur Gewinnung ihrer Stichprobe keine Zufallsauswahl, da sie gezielt 100 Sportler auswählten. Aus diesem Grund ist ihre Stichprobe nicht repräsentativ für die Gesamtbevölkerung und ihre externe Validität ist daher beeinträchtigt – sie werden nicht in der Lage sein, die Studienergebnisse auf die Gesamtbevölkerung zu übertragen. Darüber hinaus teilen sie Einzelpersonen anhand des Geschlechts in Gruppen ein und verlassen sich nicht auf eine zufällige Zuordnung, was bedeutet, dass auch ihre interne Validität beeinträchtigt ist – Unterschiede beim Gewichtsverlust könnten eher auf das Geschlecht als auf die Ernährung zurückzuführen sein.
Über den Autor
Dr. Benjamin Anderson
Hallo, ich bin Benjamin, ein pensionierter Statistikprofessor, der sich zum engagierten Statorials-Lehrer entwickelt hat. Mit umfassender Erfahrung und Fachwissen auf dem Gebiet der Statistik bin ich bestrebt, mein Wissen zu teilen, um Studenten durch Statorials zu befähigen. Mehr wissen