आर में चाउ टेस्ट कैसे करें
चाउ परीक्षण का उपयोग यह जांचने के लिए किया जाता है कि विभिन्न डेटा सेट पर दो अलग-अलग प्रतिगमन मॉडल के गुणांक बराबर हैं या नहीं।
इस परीक्षण का उपयोग आम तौर पर समय श्रृंखला डेटा के साथ अर्थमिति के क्षेत्र में यह निर्धारित करने के लिए किया जाता है कि किसी निश्चित समय पर डेटा में कोई संरचनात्मक खराबी है या नहीं।
यह ट्यूटोरियल आर में चाउ परीक्षण कैसे करें इसका चरण-दर-चरण उदाहरण प्रदान करता है।
चरण 1: डेटा बनाएं
सबसे पहले, हम नकली डेटा बनाएंगे:
#create data data <- data.frame(x = c(1, 1, 2, 3, 4, 4, 5, 5, 6, 7, 7, 8, 8, 9, 10, 10, 11, 12, 12, 13, 14, 15, 15, 16, 17, 18, 18, 19, 20, 20), y = c(3, 5, 6, 10, 13, 15, 17, 14, 20, 23, 25, 27, 30, 30, 31, 33, 32, 32, 30, 32, 34, 34, 37, 35, 34, 36, 34, 37, 38, 36)) #view first six rows of data head(data) xy 1 1 3 2 1 5 3 2 6 4 3 10 5 4 13 6 4 15
चरण 2: डेटा को विज़ुअलाइज़ करें
इसके बाद, हम डेटा को विज़ुअलाइज़ करने के लिए एक सरल स्कैटरप्लॉट बनाएंगे:
#load ggplot2 visualization package library (ggplot2) #create scatterplot ggplot(data, aes (x = x, y = y)) + geom_point(col=' steelblue ', size= 3 )
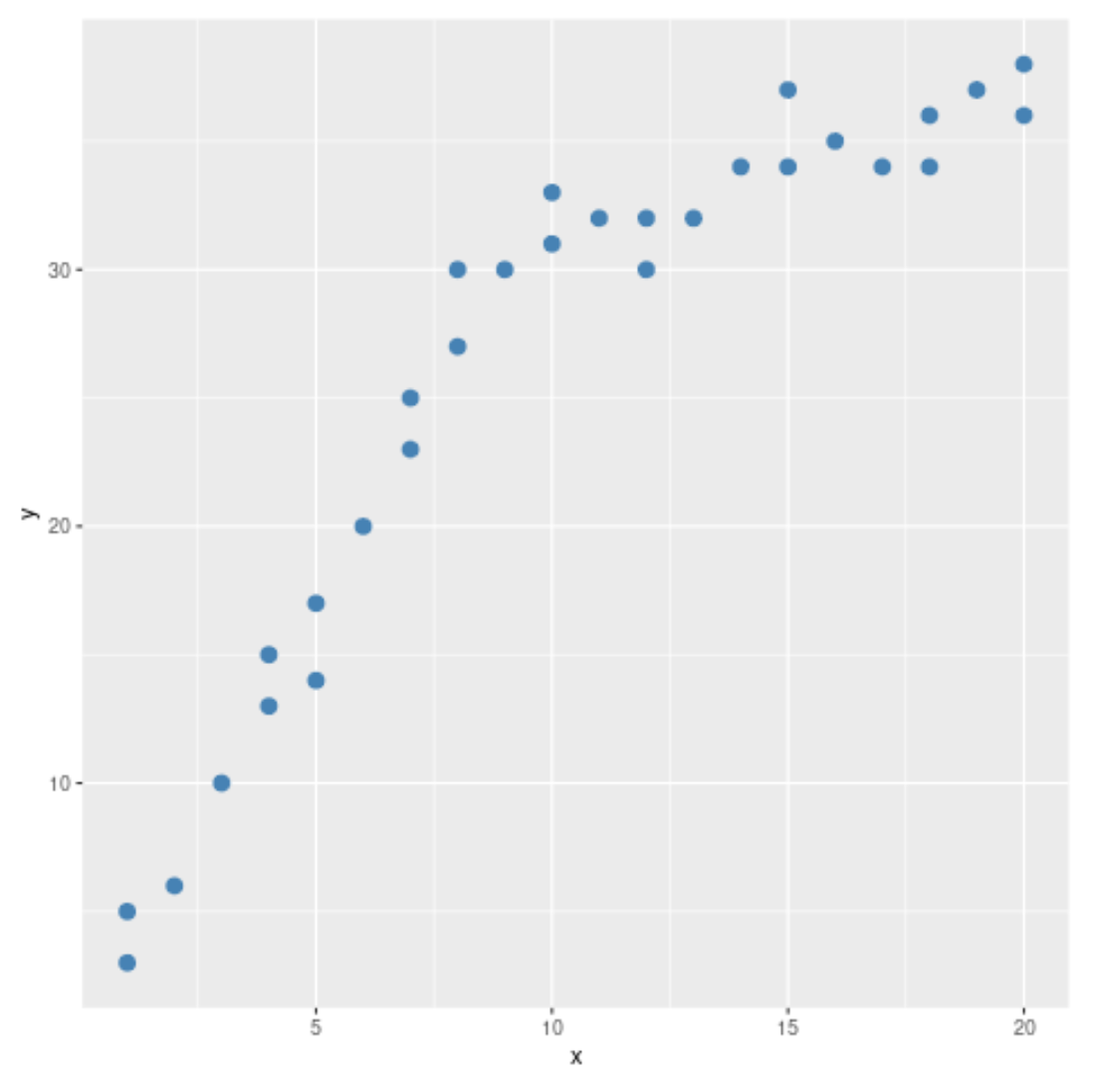
स्कैटरप्लॉट से, हम देख सकते हैं कि डेटा में पैटर्न x = 10 पर बदलता प्रतीत होता है। इस प्रकार, हम यह निर्धारित करने के लिए चाउ परीक्षण कर सकते हैं कि x = 10 पर डेटा में कोई संरचनात्मक ब्रेक पॉइंट है या नहीं।
चरण 3: चाउ टेस्ट करें
चाउ परीक्षण करने के लिए हम स्ट्रुचेंज पैकेज से सबसे अच्छे फ़ंक्शन का उपयोग कर सकते हैं:
#load strucchange package library (strucchange) #perform Chow test sctest(data$y ~ data$x, type = " Chow ", point = 10 ) Chow test data: data$y ~ data$x F = 110.14, p-value = 2.023e-13
परीक्षण परिणाम से हम देख सकते हैं:
- एफ-परीक्षण आँकड़ा : 110.14
- पी-वैल्यू: <.0000
चूँकि पी-मान 0.05 से कम है, हम परीक्षण की शून्य परिकल्पना को अस्वीकार कर सकते हैं। इसका मतलब यह है कि हमारे पास यह कहने के लिए पर्याप्त सबूत हैं कि डेटा में एक संरचनात्मक ब्रेकप्वाइंट मौजूद है।
दूसरे शब्दों में, दो प्रतिगमन रेखाएं एकल प्रतिगमन रेखा की तुलना में मॉडल को डेटा में अधिक प्रभावी ढंग से फिट कर सकती हैं।
लेखक के बारे में
डॉ. बेंजामिन एंडरसन
नमस्ते, मैं बेंजामिन हूं, एक सेवानिवृत्त सांख्यिकी प्रोफेसर जो अब समर्पित Statorials शिक्षक बन गया है। सांख्यिकी के क्षेत्र में व्यापक अनुभव और विशेषज्ञता के साथ, मैं Statorials के माध्यम से छात्रों को सशक्त बनाने के लिए अपना ज्ञान साझा करने के लिए उत्सुक हूं। अधिक जाने