आर में बहुआयामी स्केलिंग कैसे करें (उदाहरण के साथ)
आंकड़ों में, बहुआयामी स्केलिंग एक अमूर्त कार्टेशियन स्पेस (आमतौर पर 2 डी स्पेस) में डेटा सेट में अवलोकनों की समानता को देखने का एक तरीका है।
R में बहुआयामी स्केलिंग करने का सबसे आसान तरीका अंतर्निहित cmdscale() फ़ंक्शन का उपयोग करना है, जो निम्नलिखित मूल सिंटैक्स का उपयोग करता है:
cmdscale(d, eig = FALSE, k = 2,…)
सोना:
- d : एक दूरी मैट्रिक्स जिसकी गणना आम तौर पर dist() फ़ंक्शन द्वारा की जाती है।
- eig : eigenvalues वापस करना है या नहीं।
- k : डेटा को देखने के लिए आयामों की संख्या। डिफ़ॉल्ट 2 है.
निम्नलिखित उदाहरण दिखाता है कि व्यवहार में इस फ़ंक्शन का उपयोग कैसे करें।
उदाहरण: आर में बहुआयामी स्केलिंग
मान लीजिए कि हमारे पास आर में निम्नलिखित डेटा फ्रेम है जिसमें विभिन्न बास्केटबॉल खिलाड़ियों के बारे में जानकारी है:
#create data frame df <- data. frame (points=c(4, 4, 6, 7, 8, 14, 16, 19, 25, 25, 28), assists=c(3, 2, 2, 5, 4, 8, 7, 6, 8, 10, 11), blocks=c(7, 3, 6, 7, 5, 8, 8, 4, 2, 2, 1), rebounds=c(4, 5, 5, 6, 5, 8, 10, 4, 3, 2, 2)) #add row names row. names (df) <- LETTERS[1:11] #view data frame df points assists blocks rebounds A 4 3 7 4 B 4 2 3 5 C 6 2 6 5 D 7 5 7 6 E 8 4 5 5 F 14 8 8 8 G 16 7 8 10 H 19 6 4 4 I 25 8 2 3 D 25 10 2 2 K 28 11 1 2
हम cmdscale() फ़ंक्शन के साथ बहुआयामी स्केलिंग करने और 2डी स्पेस में परिणामों की कल्पना करने के लिए निम्नलिखित कोड का उपयोग कर सकते हैं:
#calculate distance matrix
d <- dist(df)
#perform multidimensional scaling
fit <- cmdscale(d, eig= TRUE , k= 2 )
#extract (x, y) coordinates of multidimensional scaling
x <- fit$points[,1]
y <- fit$points[,2]
#create scatterplot
plot(x, y, xlab=" Coordinate 1 ", ylab=" Coordinate 2 ",
main=" Multidimensional Scaling Results ", type=" n ")
#add row names of data frame as labels
text(x, y, labels=row. names (df))
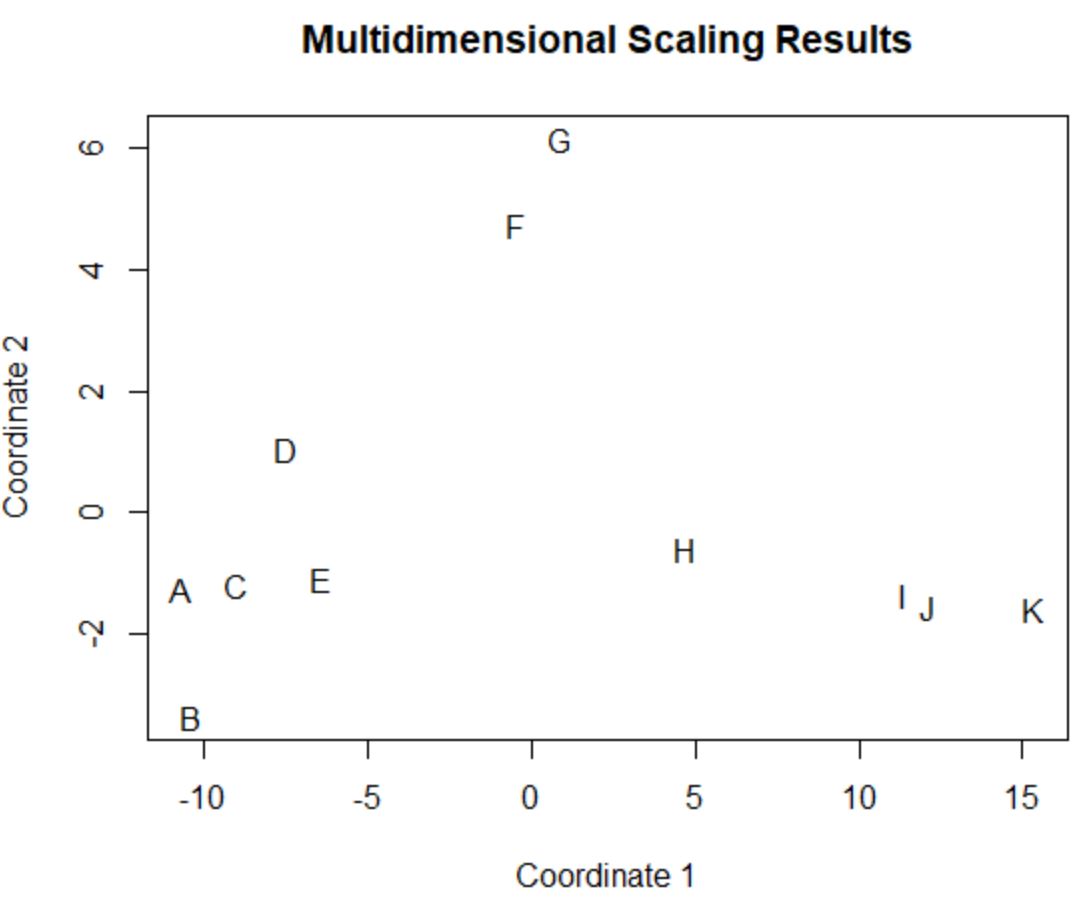
मूल डेटा फ़्रेम में खिलाड़ी जिनके मूल चार कॉलम (अंक, सहायता, ब्लॉक और रिबाउंड) में समान मान हैं, प्लॉट में एक दूसरे के करीब हैं।
उदाहरण के लिए, खिलाड़ी A और C एक दूसरे के करीब हैं। मूल डेटा फ़्रेम से उनके मान यहां दिए गए हैं:
#view data frame values for players A and C df[rownames(df) %in% c(' A ', ' C '), ] points assists blocks rebounds A 4 3 7 4 C 6 2 6 5
अंक, सहायता, ब्लॉक और रिबाउंड के लिए उनके मूल्य काफी समान हैं, जो बताता है कि वे 2डी प्लॉट में एक-दूसरे के इतने करीब क्यों हैं।
इसके विपरीत, खिलाड़ी बी और के पर विचार करें जो कथानक में बहुत दूर हैं।
यदि हम मूल डेटा में उनके मूल्यों का संदर्भ लें, तो हम देख सकते हैं कि वे काफी भिन्न हैं:
#view data frame values for players B and K df[rownames(df) %in% c(' B ', ' K '), ] points assists blocks rebounds B 4 2 3 5 K 28 11 1 2
इसलिए 2डी प्लॉट यह कल्पना करने का एक अच्छा तरीका है कि प्रत्येक खिलाड़ी डेटा फ्रेम में सभी वेरिएबल्स में कितना समान है।
समान आँकड़े वाले खिलाड़ियों को एक साथ समूहीकृत किया जाता है जबकि बहुत भिन्न आँकड़ों वाले खिलाड़ी कथानक में एक-दूसरे से दूर होते हैं।
ध्यान दें कि आप फिट टाइप करके प्लॉट में प्रत्येक खिलाड़ी के सटीक निर्देशांक (x, y) भी निकाल सकते हैं, जो उस वेरिएबल का नाम है जिसमें हमने cmdscale() फ़ंक्शन के परिणाम संग्रहीत किए हैं:
#view (x, y) coordinates of points in the plot
fit
[,1] [,2]
A -10.6617577 -1.2511291
B -10.3858237 -3.3450473
C -9.0330408 -1.1968116
D -7.4905743 1.0578445
E -6.4021114 -1.0743669
F -0.4618426 4.7392534
G 0.8850934 6.1460850
H 4.7352436 -0.6004609
I 11.3793381 -1.3563398
J 12.0844168 -1.5494108
K 15.3510585 -1.5696166
अतिरिक्त संसाधन
निम्नलिखित ट्यूटोरियल बताते हैं कि आर में अन्य सामान्य कार्य कैसे करें:
आर में डेटा को सामान्य कैसे करें
आर में डेटा सेंटर कैसे बनायें?
आर में आउटलेर्स को कैसे हटाएं
लेखक के बारे में
डॉ. बेंजामिन एंडरसन
नमस्ते, मैं बेंजामिन हूं, एक सेवानिवृत्त सांख्यिकी प्रोफेसर जो अब समर्पित Statorials शिक्षक बन गया है। सांख्यिकी के क्षेत्र में व्यापक अनुभव और विशेषज्ञता के साथ, मैं Statorials के माध्यम से छात्रों को सशक्त बनाने के लिए अपना ज्ञान साझा करने के लिए उत्सुक हूं। अधिक जाने