पांडा: प्रति पंक्ति अलग-अलग संख्या में कॉलम के साथ सीएसवी आयात करें
जब प्रति पंक्ति में अलग-अलग संख्या में कॉलम हों तो आप CSV फ़ाइल को पांडा में आयात करने के लिए निम्नलिखित मूल सिंटैक्स का उपयोग कर सकते हैं:
df = pd. read_csv (' uneven_data.csv ', header= None , names=range( 4 ))
रेंज() फ़ंक्शन के अंदर का मान पंक्ति में कॉलम की अधिकतम संख्या के साथ कॉलम की संख्या होनी चाहिए।
निम्नलिखित उदाहरण दिखाता है कि व्यवहार में इस वाक्यविन्यास का उपयोग कैसे करें।
उदाहरण: प्रति पंक्ति अलग-अलग संख्या में कॉलम के साथ पांडा में सीएसवी आयात करें
मान लीजिए कि हमारे पास निम्नलिखित CSV फ़ाइल है, जिसे असमान_डेटा.csv कहा जाता है:
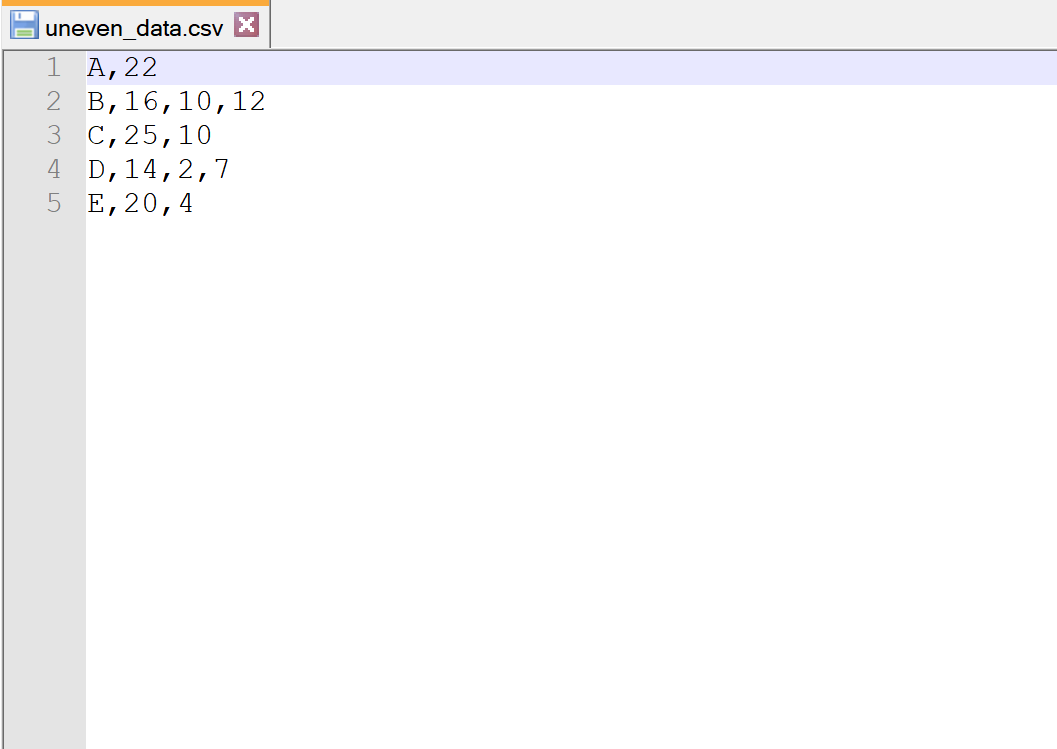
ध्यान दें कि प्रत्येक पंक्ति में स्तंभों की संख्या समान नहीं है।
यदि हम इस CSV फ़ाइल को पांडा डेटाफ़्रेम में आयात करने के लिए read_csv() फ़ंक्शन का उपयोग करने का प्रयास करते हैं, तो हमें एक त्रुटि प्राप्त होगी:
import pandas as pd #attempt to import CSV file with differing number of columns per row df = pd. read_csv (' uneven_data.csv ', header= None ) ParserError: Error tokenizing data. C error: Expected 2 fields in line 2, saw 4
हमें एक ParserError प्राप्त होता है जो हमें बताता है कि पांडा 2 फ़ील्ड की अपेक्षा कर रहा था (क्योंकि वह पहली पंक्ति में कॉलम की संख्या थी) लेकिन उसने 4 देखा।
यह त्रुटि हमें बताती है कि दी गई पंक्ति में स्तंभों की अधिकतम संख्या 4 है।
इसलिए, हम CSV फ़ाइल आयात कर सकते हैं और नाम तर्क के लिए श्रेणी (4) का मान प्रदान कर सकते हैं:
import pandas as pd #import CSV file with differing number of columns per row df = pd. read_csv (' uneven_data.csv ', header= None , names=range( 4 ))) #view DataFrame print (df) 0 1 2 3 0 to 22 NaN NaN 1 B 16 10.0 12.0 2 C 25 10.0 NaN 3 D 14 2.0 7.0 4 E 20 4.0 NaN
ध्यान दें कि हम सीएसवी फ़ाइल को बिना किसी त्रुटि के पांडा डेटाफ़्रेम में सफलतापूर्वक आयात करने में सक्षम हैं क्योंकि हमने स्पष्ट रूप से पांडा को 4 कॉलम की अपेक्षा करने के लिए कहा था।
डिफ़ॉल्ट रूप से, पांडा प्रत्येक पंक्ति में सभी लापता मानों को NaN से भरता है।
यदि आप चाहते हैं कि लुप्त मान शून्य के रूप में दिखाई दें, तो आप निम्नानुसार fillna() फ़ंक्शन का उपयोग कर सकते हैं:
#fill NaN values with zeros df_new = df. fillna ( 0 ) #view new DataFrame print (df_new) 0 1 2 3 0 to 22 0.0 0.0 1 B 16 10.0 12.0 2 C 25 10.0 0.0 3 D 14 2.0 7.0 4 E 20 4.0 0.0
डेटाफ़्रेम में प्रत्येक NaN मान को अब शून्य से बदल दिया गया है।
नोट : आप पांडा read_csv() फ़ंक्शन का पूरा दस्तावेज़ यहां पा सकते हैं।
अतिरिक्त संसाधन
निम्नलिखित ट्यूटोरियल बताते हैं कि पायथन में अन्य सामान्य कार्य कैसे करें:
पांडा: CSV फ़ाइल पढ़ते समय पंक्तियों को कैसे छोड़ें
पांडा: मौजूदा सीएसवी फ़ाइल में डेटा कैसे जोड़ें
पांडा: CSV फ़ाइल आयात करते समय प्रकार कैसे निर्दिष्ट करें
पांडा: CSV फ़ाइल आयात करते समय कॉलम नाम सेट करें
लेखक के बारे में
डॉ. बेंजामिन एंडरसन
नमस्ते, मैं बेंजामिन हूं, एक सेवानिवृत्त सांख्यिकी प्रोफेसर जो अब समर्पित Statorials शिक्षक बन गया है। सांख्यिकी के क्षेत्र में व्यापक अनुभव और विशेषज्ञता के साथ, मैं Statorials के माध्यम से छात्रों को सशक्त बनाने के लिए अपना ज्ञान साझा करने के लिए उत्सुक हूं। अधिक जाने