पायथन में के-मीन्स क्लस्टरिंग: चरण-दर-चरण उदाहरण
मशीन लर्निंग में सबसे आम क्लस्टरिंग एल्गोरिदम में से एक को के-मीन्स क्लस्टरिंग के रूप में जाना जाता है।
के-मीन्स क्लस्टरिंग एक ऐसी तकनीक है जिसमें हम डेटासेट से प्रत्येक अवलोकन को के क्लस्टर में से एक में रखते हैं।
अंतिम लक्ष्य K क्लस्टर बनाना है जिसमें प्रत्येक क्लस्टर के भीतर अवलोकन एक दूसरे के समान होते हैं जबकि विभिन्न समूहों में अवलोकन एक दूसरे से काफी भिन्न होते हैं।
व्यवहार में, हम K-मीन्स क्लस्टरिंग करने के लिए निम्नलिखित चरणों का उपयोग करते हैं:
1. K के लिए एक मान चुनें.
- सबसे पहले, हमें यह तय करना होगा कि हम डेटा में कितने समूहों की पहचान करना चाहते हैं। अक्सर हमें K के लिए कई अलग-अलग मानों का परीक्षण करने और परिणामों का विश्लेषण करने की आवश्यकता होती है ताकि यह देखा जा सके कि किसी दिए गए समस्या के लिए क्लस्टर की कौन सी संख्या सबसे अधिक समझ में आती है।
2. 1 से K तक, प्रत्येक अवलोकन को यादृच्छिक रूप से प्रारंभिक क्लस्टर में निर्दिष्ट करें।
3. निम्नलिखित प्रक्रिया तब तक करें जब तक क्लस्टर असाइनमेंट बदलना बंद न हो जाए।
- प्रत्येक K क्लस्टर के लिए, क्लस्टर के गुरुत्वाकर्षण के केंद्र की गणना करें। यह केवल केवें क्लस्टर के अवलोकनों के लिए पी- माध्य विशेषताओं का वेक्टर है।
- प्रत्येक अवलोकन को निकटतम केन्द्रक वाले क्लस्टर में निर्दिष्ट करें। यहां, यूक्लिडियन दूरी का उपयोग करके निकटतम को परिभाषित किया गया है।
निम्नलिखित चरण-दर-चरण उदाहरण दिखाता है कि स्केलेर मॉड्यूल से KMeans फ़ंक्शन का उपयोग करके पायथन में k-मीन्स क्लस्टरिंग कैसे करें।
चरण 1: आवश्यक मॉड्यूल आयात करें
सबसे पहले, हम उन सभी मॉड्यूल को आयात करेंगे जिनकी हमें k-मीन्स क्लस्टरिंग करने के लिए आवश्यकता होगी:
import pandas as pd
import numpy as np
import matplotlib. pyplot as plt
from sklearn. cluster import KMeans
from sklearn. preprocessing import StandardScaler
चरण 2: डेटाफ़्रेम बनाएं
इसके बाद, हम एक डेटाफ़्रेम बनाएंगे जिसमें 20 अलग-अलग बास्केटबॉल खिलाड़ियों के लिए निम्नलिखित तीन वेरिएबल होंगे:
- अंक
- मदद
- बाउंस
निम्नलिखित कोड दिखाता है कि इस पांडा डेटाफ़्रेम को कैसे बनाया जाए:
#createDataFrame
df = pd. DataFrame ({' points ': [18, np.nan, 19, 14, 14, 11, 20, 28, 30, 31,
35, 33, 29, 25, 25, 27, 29, 30, 19, 23],
' assists ': [3, 3, 4, 5, 4, 7, 8, 7, 6, 9, 12, 14,
np.nan, 9, 4, 3, 4, 12, 15, 11],
' rebounds ': [15, 14, 14, 10, 8, 14, 13, 9, 5, 4,
11, 6, 5, 5, 3, 8, 12, 7, 6, 5]})
#view first five rows of DataFrame
print ( df.head ())
points assists rebounds
0 18.0 3.0 15
1 NaN 3.0 14
2 19.0 4.0 14
3 14.0 5.0 10
4 14.0 4.0 8
हम इन तीन मैट्रिक्स के आधार पर समान अभिनेताओं को समूहित करने के लिए k-मीन्स क्लस्टरिंग का उपयोग करेंगे।
चरण 3: डेटाफ़्रेम को साफ़ करें और तैयार करें
फिर हम निम्नलिखित कदम उठाएंगे:
- किसी भी कॉलम में NaN मान वाली पंक्तियों को ड्रॉप करने के लिए ड्रॉपना() का उपयोग करें
- प्रत्येक वेरिएबल को स्केल करने के लिए स्टैंडर्ड स्केलर () का उपयोग करें ताकि माध्य 0 और मानक विचलन 1 हो।
निम्नलिखित कोड दिखाता है कि यह कैसे करना है:
#drop rows with NA values in any columns df = df. dropna () #create scaled DataFrame where each variable has mean of 0 and standard dev of 1 scaled_df = StandardScaler(). fit_transform (df) #view first five rows of scaled DataFrame print (scaled_df[:5]) [[-0.86660275 -1.22683918 1.72722524] [-0.72081911 -0.96077767 1.45687694] [-1.44973731 -0.69471616 0.37548375] [-1.44973731 -0.96077767 -0.16521285] [-1.88708823 -0.16259314 1.45687694]]
ध्यान दें : हम स्केलिंग का उपयोग करते हैं ताकि k-मीन्स एल्गोरिदम को फिट करते समय प्रत्येक चर का समान महत्व हो। अन्यथा, व्यापक रेंज वाले चरों का बहुत अधिक प्रभाव होगा।
चरण 4: समूहों की इष्टतम संख्या ज्ञात करें
पायथन में k-मीन्स क्लस्टरिंग करने के लिए, हम sklearn मॉड्यूल से KMeans फ़ंक्शन का उपयोग कर सकते हैं।
यह फ़ंक्शन निम्नलिखित मूल सिंटैक्स का उपयोग करता है:
KMeans(init=’random’, n_clusters=8, n_init=10, रैंडम_स्टेट=कोई नहीं)
सोना:
- init : आरंभीकरण तकनीक को नियंत्रित करता है।
- n_clusters : उन समूहों की संख्या जिनमें अवलोकन रखे जाने हैं।
- n_init : निष्पादित किए जाने वाले आरंभीकरणों की संख्या. डिफ़ॉल्ट रूप से k-मीन्स एल्गोरिथम को 10 बार चलाना और सबसे कम SSE वाले को वापस करना है।
- रैंडम_स्टेट : एक पूर्णांक मान जिसे आप एल्गोरिदम परिणामों को प्रतिलिपि प्रस्तुत करने योग्य बनाने के लिए चुन सकते हैं।
इस फ़ंक्शन का सबसे महत्वपूर्ण तर्क n_clusters है, जो निर्दिष्ट करता है कि कितने समूहों में अवलोकन रखना है।
हालाँकि, हम पहले से नहीं जानते कि कितने क्लस्टर इष्टतम हैं, इसलिए हमें एक ग्राफ बनाने की आवश्यकता है जो क्लस्टर की संख्या के साथ-साथ मॉडल के एसएसई (वर्ग त्रुटियों का योग) को प्रदर्शित करता है।
आमतौर पर, जब हम इस प्रकार का प्लॉट बनाते हैं, तो हम एक “घुटने” की तलाश करते हैं जहां वर्गों का योग “झुकना” या समतल होना शुरू हो जाता है। यह आम तौर पर समूहों की इष्टतम संख्या है।
निम्नलिखित कोड दिखाता है कि इस प्रकार का प्लॉट कैसे बनाया जाए जो x-अक्ष पर क्लस्टर की संख्या और y-अक्ष पर SSE प्रदर्शित करता है:
#initialize kmeans parameters kmeans_kwargs = { " init ": " random ", " n_init ": 10, " random_state ": 1, } #create list to hold SSE values for each k sse = [] for k in range(1, 11): kmeans = KMeans(n_clusters=k, ** kmeans_kwargs) kmeans. fit (scaled_df) sse. append (kmeans.inertia_) #visualize results plt. plot (range(1, 11), sse) plt. xticks (range(1, 11)) plt. xlabel (" Number of Clusters ") plt. ylabel (“ SSE ”) plt. show ()
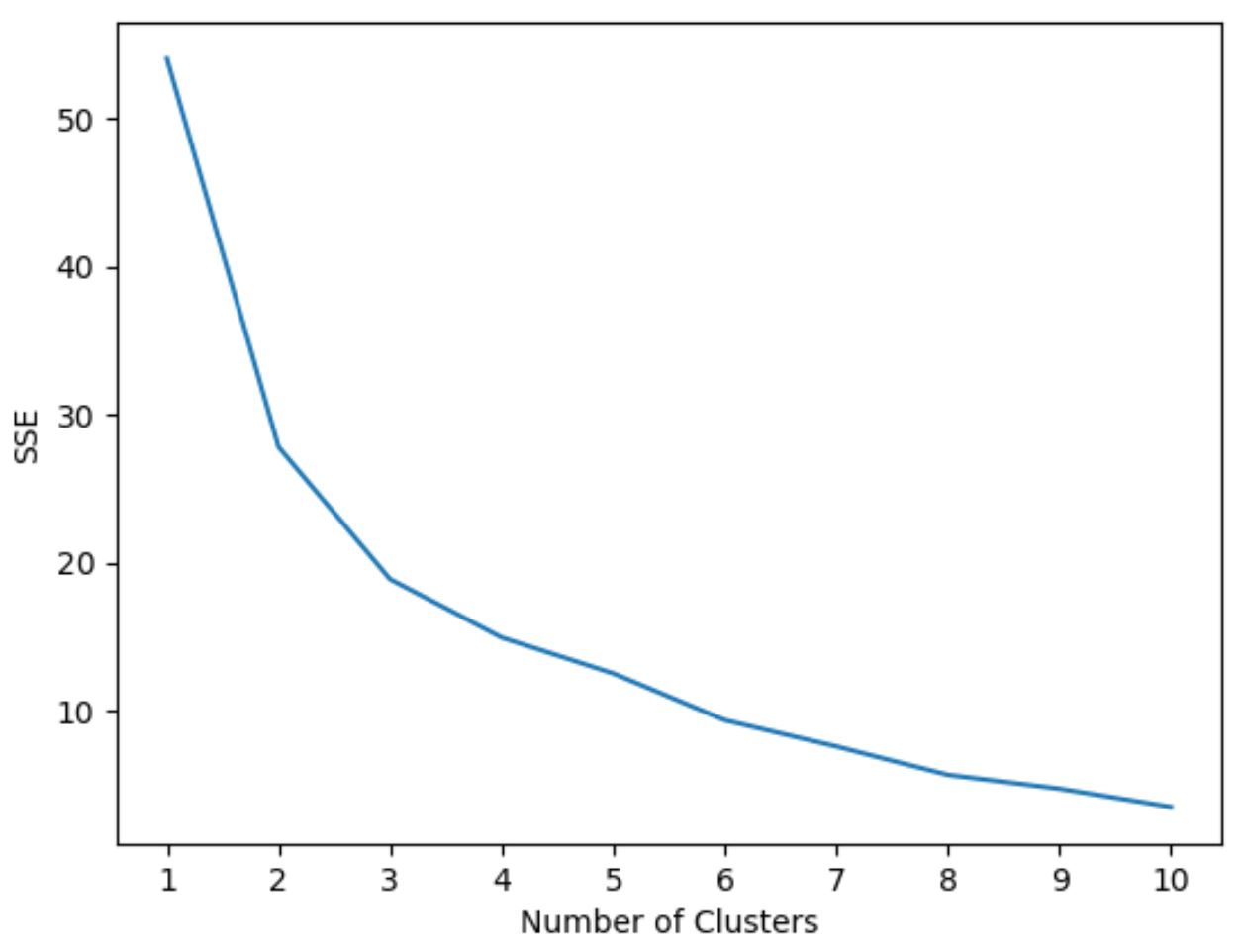
इस ग्राफ़ में, ऐसा प्रतीत होता है कि k = 3 समूहों पर एक किंक या “घुटना” है।
इसलिए, अगले चरण में अपने k-मीन्स क्लस्टरिंग मॉडल को फिट करते समय हम 3 क्लस्टर का उपयोग करेंगे।
ध्यान दें : वास्तविक दुनिया में, उपयोग करने के लिए क्लस्टर की संख्या चुनने के लिए इस प्लॉट और डोमेन विशेषज्ञता के संयोजन का उपयोग करने की अनुशंसा की जाती है।
चरण 5: ऑप्टिमल K के साथ K-मीन्स क्लस्टरिंग करें
निम्नलिखित कोड दिखाता है कि 3 में से k के लिए इष्टतम मान का उपयोग करके डेटासेट पर k-मीन्स क्लस्टरिंग कैसे करें:
#instantiate the k-means class, using optimal number of clusters
kmeans = KMeans(init=" random ", n_clusters= 3 , n_init= 10 , random_state= 1 )
#fit k-means algorithm to data
kmeans. fit (scaled_df)
#view cluster assignments for each observation
kmeans. labels_
array([1, 1, 1, 1, 1, 1, 2, 2, 0, 0, 0, 0, 2, 2, 2, 0, 0, 0])
परिणामी तालिका डेटाफ़्रेम में प्रत्येक अवलोकन के लिए क्लस्टर असाइनमेंट दिखाती है।
इन परिणामों की व्याख्या करना आसान बनाने के लिए, हम डेटाफ़्रेम में एक कॉलम जोड़ सकते हैं जो प्रत्येक खिलाड़ी के क्लस्टर असाइनमेंट को दिखाता है:
#append cluster assingments to original DataFrame
df[' cluster '] = kmeans. labels_
#view updated DataFrame
print (df)
points assists rebounds cluster
0 18.0 3.0 15 1
2 19.0 4.0 14 1
3 14.0 5.0 10 1
4 14.0 4.0 8 1
5 11.0 7.0 14 1
6 20.0 8.0 13 1
7 28.0 7.0 9 2
8 30.0 6.0 5 2
9 31.0 9.0 4 0
10 35.0 12.0 11 0
11 33.0 14.0 6 0
13 25.0 9.0 5 0
14 25.0 4.0 3 2
15 27.0 3.0 8 2
16 29.0 4.0 12 2
17 30.0 12.0 7 0
18 19.0 15.0 6 0
19 23.0 11.0 5 0
क्लस्टर कॉलम में एक क्लस्टर नंबर (0, 1, या 2) होता है जिसे प्रत्येक खिलाड़ी को सौंपा गया है।
एक ही क्लस्टर से संबंधित खिलाड़ियों के पास अंक , सहायता और रिबाउंड कॉलम के लिए लगभग समान मूल्य होते हैं।
नोट : आप sklearn के KMeans फ़ंक्शन के लिए संपूर्ण दस्तावेज़ यहां पा सकते हैं।
अतिरिक्त संसाधन
निम्नलिखित ट्यूटोरियल बताते हैं कि पायथन में अन्य सामान्य कार्य कैसे करें:
पायथन में लीनियर रिग्रेशन कैसे करें
पायथन में लॉजिस्टिक रिग्रेशन कैसे करें
पायथन में के-फोल्ड क्रॉस-वैलिडेशन कैसे करें
लेखक के बारे में
डॉ. बेंजामिन एंडरसन
नमस्ते, मैं बेंजामिन हूं, एक सेवानिवृत्त सांख्यिकी प्रोफेसर जो अब समर्पित Statorials शिक्षक बन गया है। सांख्यिकी के क्षेत्र में व्यापक अनुभव और विशेषज्ञता के साथ, मैं Statorials के माध्यम से छात्रों को सशक्त बनाने के लिए अपना ज्ञान साझा करने के लिए उत्सुक हूं। अधिक जाने