असमूहीकृत डेटा
इस लेख में, आप सीखेंगे कि सांख्यिकी में असमूहीकृत डेटा क्या है, असमूहीकृत डेटा का एक हल किया गया अभ्यास और यह भी कि समूहीकृत डेटा और असमूहीकृत डेटा के बीच क्या अंतर हैं।
असमूहीकृत डेटा क्या है?
आंकड़ों में, अनपूल्ड डेटा वह डेटा है जिसे समूहीकृत नहीं किया जाता है बल्कि अलग से अध्ययन किया जाता है। अर्थात्, जब डेटा को समूहीकृत नहीं किया जाता है, तो डेटासेट में प्रत्येक मान का व्यक्तिगत रूप से विश्लेषण किया जाता है।
असमूहीकृत डेटा अंतराल नहीं बनाता है, लेकिन समूहीकृत डेटा बनाता है।
सामान्य तौर पर, डेटा को तब समूहीकृत किया जाता है जब चर निरंतर होता है या जब विश्लेषण करने के लिए कई मान होते हैं। इसलिए, जब डेटा एक अलग चर का अनुसरण करता है और हमारे पास बहुत बड़ी मात्रा में डेटा नहीं है, तो डेटा को अंतरालों में समूहित करने की कोई आवश्यकता नहीं है।
असमूहीकृत डेटा का उदाहरण
एक बार जब हमने असमूहीकृत डेटा की परिभाषा देख ली, तो अब हम अवधारणा को बेहतर ढंग से समझने के लिए इस प्रकार के सांख्यिकीय डेटा के साथ एक उदाहरण को हल करने के लिए आगे बढ़ते हैं।
- 30 छात्रों की एक कक्षा में सांख्यिकी में प्राप्त अंक इस प्रकार हैं। प्रत्येक नोट की पूर्ण आवृत्ति क्या है?



इस मामले में यह एक अलग चर है क्योंकि इसमें केवल पूर्णांक हो सकते हैं, इसलिए डेटा को अंतरालों में समूहित करने की कोई आवश्यकता नहीं है।
तो बस प्रत्येक मान प्रकट होने की संख्या गिनें और इसे एक सरणी में लिखें:
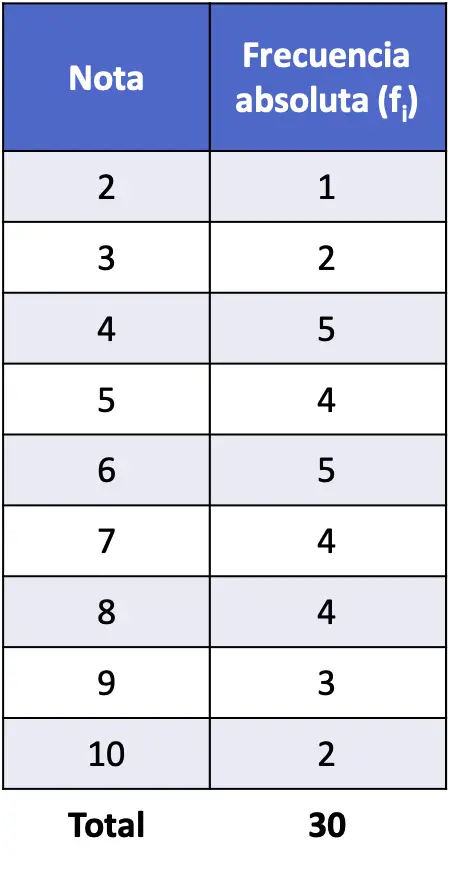
चूँकि डेटा को अंतरालों में समूहीकृत नहीं किया गया है, इसलिए प्रत्येक मान का अलग से अध्ययन किया जा सकता है। इस प्रकार हम प्रत्येक नोट लेने वाले छात्रों की संख्या जान सकते हैं।
ध्यान दें कि आवृत्ति तालिका को पूरा करने के लिए, आपको हमेशा संचयी निरपेक्ष आवृत्ति, सापेक्ष आवृत्ति, संचयी सापेक्ष आवृत्ति आदि की गणना करनी चाहिए। आप यहां देख सकते हैं कि यह कैसे किया गया है:
असमूहीकृत डेटा और समूहीकृत डेटा
इस अनुभाग में हम देखेंगे कि समूहीकृत डेटा और असमूहीकृत डेटा के बीच क्या अंतर है। इसके अलावा, हम देखेंगे कि कब डेटा को समूहीकृत करना उचित है और कब नहीं क्योंकि, तार्किक रूप से, यह बाकी जांच की स्थिति है।
समूहीकृत डेटा और असमूहीकृत डेटा के बीच अंतर समूहीकरण है या नहीं। जब डेटा को समूहीकृत किया जाता है, तो इसका मतलब है कि इसे अंतराल में एकत्र किया जाता है, दूसरी ओर, यदि डेटा को समूहीकृत नहीं किया जाता है, तो इसका मतलब है कि प्रत्येक मान का अलग-अलग अध्ययन किया जाता है।
सामान्य तौर पर, जब चर निरंतर होता है तो डेटा को अंतरालों द्वारा समूहीकृत किया जाता है, लेकिन यदि चर असतत है तो डेटा को समूहीकृत न करना बेहतर है। हालाँकि, यदि हमारे पास बड़ी मात्रा में डेटा है, तो हम सांख्यिकीय अध्ययन की सुविधा के लिए डेटा को अंतरालों में समूहित भी कर सकते हैं।
अनपूल किए गए डेटा के सांख्यिकीय उपाय
एक बार आवृत्ति तालिका का निर्माण हो जाने के बाद, जब डेटा को समूहीकृत नहीं किया जाता है, तो कई सांख्यिकीय उपायों की गणना करना सामान्य है।
विशेष रूप से, केंद्रीय प्रवृत्ति के माप, फैलाव के माप और स्थिति के माप आमतौर पर निर्धारित किए जाते हैं, क्योंकि वे डेटा के नमूने को संक्षेप में प्रस्तुत करने और इसके अलावा, अन्य डेटा सेटों के साथ तुलना करने की अनुमति देते हैं।
आप देख सकते हैं कि इन सभी सांख्यिकीय मापदंडों की गणना निम्नलिखित लिंक में कैसे की जाती है:
➤ देखें: अवर्गीकृत डेटा के लिए फैलाव के उपाय
➤ देखें: असमूहीकृत डेटा के लिए स्थिति माप
लेखक के बारे में
डॉ. बेंजामिन एंडरसन
नमस्ते, मैं बेंजामिन हूं, एक सेवानिवृत्त सांख्यिकी प्रोफेसर जो अब समर्पित Statorials शिक्षक बन गया है। सांख्यिकी के क्षेत्र में व्यापक अनुभव और विशेषज्ञता के साथ, मैं Statorials के माध्यम से छात्रों को सशक्त बनाने के लिए अपना ज्ञान साझा करने के लिए उत्सुक हूं। अधिक जाने