आर में डायमंड डेटासेट के लिए एक संपूर्ण गाइड
डायमंड डेटासेट R में ggplot2 पैकेज में निर्मित एक डेटासेट है।
इसमें 53,940 अलग-अलग हीरों के लिए 10 अलग-अलग चर (जैसे कीमत, रंग, स्पष्टता, आदि) पर माप शामिल हैं।
यह ट्यूटोरियल बताता है कि आर में डायमंड डेटासेट का अन्वेषण, सारांश और कल्पना कैसे करें।
डायमंड डेटासेट लोड करें
चूंकि डायमंड डेटासेट ggplot2 में एक अंतर्निहित डेटासेट है, इसलिए हमें सबसे पहले ggplot2 पैकेज को इंस्टॉल करना होगा (यदि पहले से नहीं है) और लोड करना होगा:
#install ggplot2 if not already installed
install. packages (' ggplot2 ')
#load ggplot2
library (ggplot2)
एक बार जब हम ggplot2 लोड कर लेते हैं, तो हम डायमंड डेटासेट लोड करने के लिए डेटा() फ़ंक्शन का उपयोग कर सकते हैं:
data(diamonds)
हम हेड() फ़ंक्शन का उपयोग करके डेटासेट की पहली छह पंक्तियों पर एक नज़र डाल सकते हैं:
#view first six rows of diamonds dataset
head(diamonds)
carat cut color clarity depth table price xyz
1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
3 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31
4 0.290 Premium I VS2 62.4 58 334 4.2 4.23 2.63
5 0.31 Good J SI2 63.3 58 335 4.34 4.35 2.75
6 0.24 Very Good J VVS2 62.8 57 336 3.94 3.96 2.48
डायमंड डेटासेट को सारांशित करें
हम डेटासेट में प्रत्येक चर को शीघ्रता से सारांशित करने के लिए सारांश() फ़ंक्शन का उपयोग कर सकते हैं:
#summarize diamonds dataset
summary(diamonds)
carat cut color clarity depth
Min. :0.2000 Fair: 1610 D: 6775 SI1:13065 Min. :43.00
1st Qu.:0.4000 Good: 4906 E: 9797 VS2:12258 1st Qu.:61.00
Median: 0.7000 Very Good: 12082 F: 9542 SI2: 9194 Median: 61.80
Mean: 0.7979 Premium: 13791 G: 11292 VS1: 8171 Mean: 61.75
3rd Qu.:1.0400 Ideal:21551 H:8304 VVS2:5066 3rd Qu.:62.50
Max. :5.0100 I: 5422 VVS1: 3655 Max. :79.00
D: 2808 (Other): 2531
table price xyz Min. :43.00 Min. : 326 Min. : 0.000 Min. : 0.000 Min. : 0.000
1st Qu.: 56.00 1st Qu.: 950 1st Qu.: 4.710 1st Qu.: 4.720 1st Qu.: 2.910
Median: 57.00 Median: 2401 Median: 5.700 Median: 5.710 Median: 3.530
Mean: 57.46 Mean: 3933 Mean: 5.731 Mean: 5.735 Mean: 3.539
3rd Qu.: 59.00 3rd Qu.: 5324 3rd Qu.: 6.540 3rd Qu.: 6.540 3rd Qu.: 4.040
Max. :95.00 Max. :18823 Max. :10,740 Max. :58,900 Max. :31,800
प्रत्येक संख्यात्मक चर के लिए हम निम्नलिखित जानकारी देख सकते हैं:
- न्यूनतम : न्यूनतम मान.
- पहला Qu : प्रथम चतुर्थक (25वाँ प्रतिशतक) का मान।
- माध्यिका : माध्यिका मान.
- औसत : औसत मूल्य.
- तीसरा Qu : तीसरे चतुर्थक (75वें प्रतिशतक) का मान।
- अधिकतम : अधिकतम मान.
डेटासेट में श्रेणीबद्ध चर (कट, रंग और स्पष्टता) के लिए, हम प्रत्येक मान की आवृत्ति गणना देखते हैं।
उदाहरण के लिए, कट वेरिएबल के लिए:
- उचित : यह मान 1,610 बार प्रकट होता है।
- अच्छा : यह मान 4,906 बार प्रकट होता है।
- बहुत अच्छा : यह मान 12,082 बार प्रकट होता है।
- प्रीमियम : यह मान 13,791 बार प्रकट होता है।
- आदर्श : यह मान 21,551 बार प्रकट होता है।
हम पंक्तियों और स्तंभों की संख्या के संदर्भ में डेटासेट के आयाम प्राप्त करने के लिए dim() फ़ंक्शन का उपयोग कर सकते हैं:
#display rows and columns
dim(diamonds)
[1] 53940 10
हम देख सकते हैं कि डेटासेट में 53,940 पंक्तियाँ और 10 कॉलम हैं।
हम डेटा फ़्रेम के कॉलम नाम प्रदर्शित करने के लिए नेम्स() फ़ंक्शन का भी उपयोग कर सकते हैं:
#display column names
names(diamonds)
[1] "carat" "cut" "color" "clarity" "depth" "table" "price" "x"
[9] “y” “z”
डायमंड डेटासेट की कल्पना करें
हम डेटासेट के मूल्यों की कल्पना करने के लिए प्लॉट भी बना सकते हैं।
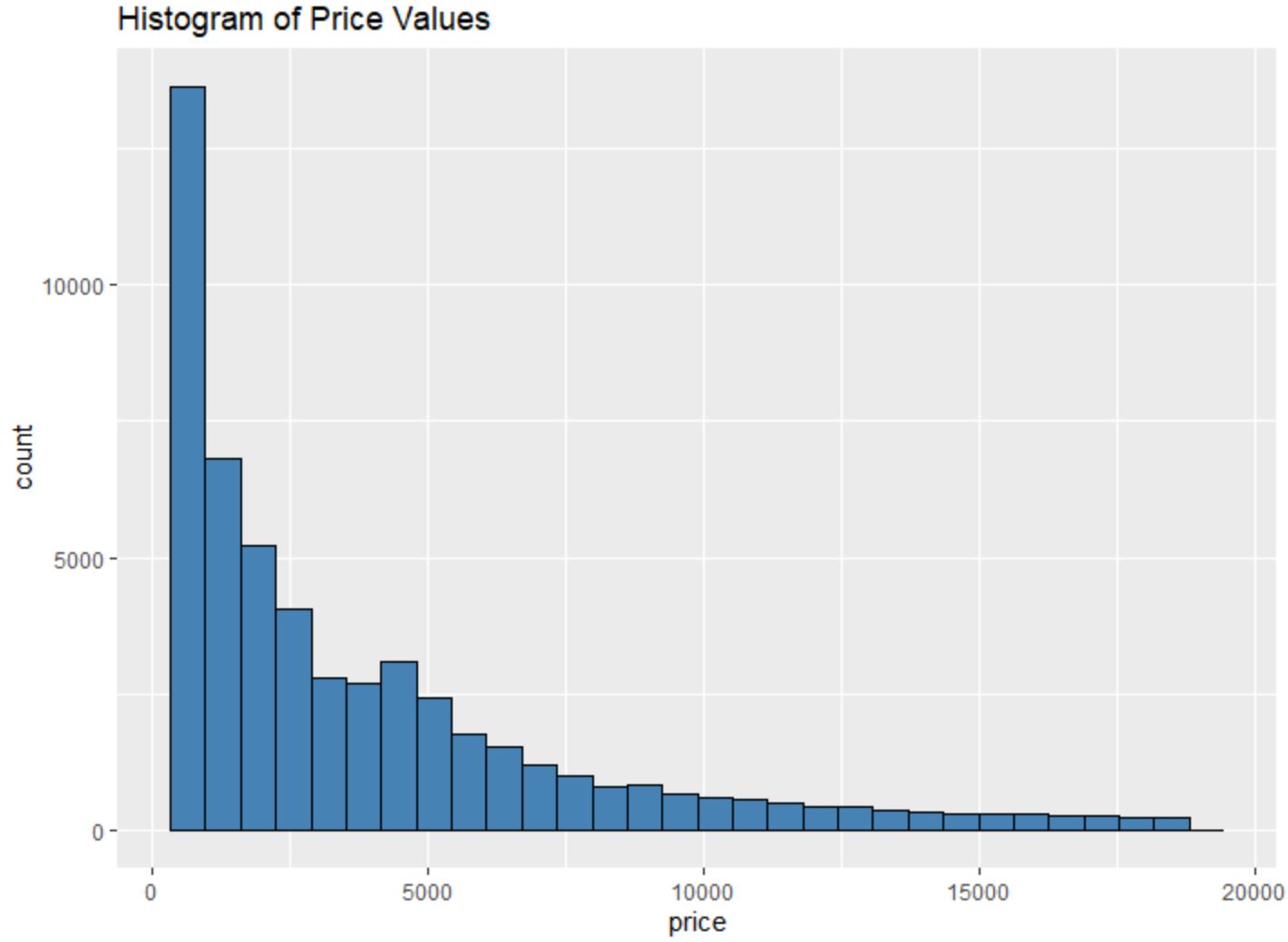
उदाहरण के लिए, हम एक निश्चित चर के मानों का हिस्टोग्राम बनाने के लिए geom_histogram() फ़ंक्शन का उपयोग कर सकते हैं:
#create histogram of values for price
ggplot(data=diamonds, aes (x=price)) +
geom_histogram(fill=" steelblue ", color=" black ") +
ggtitle(" Histogram of Price Values ")
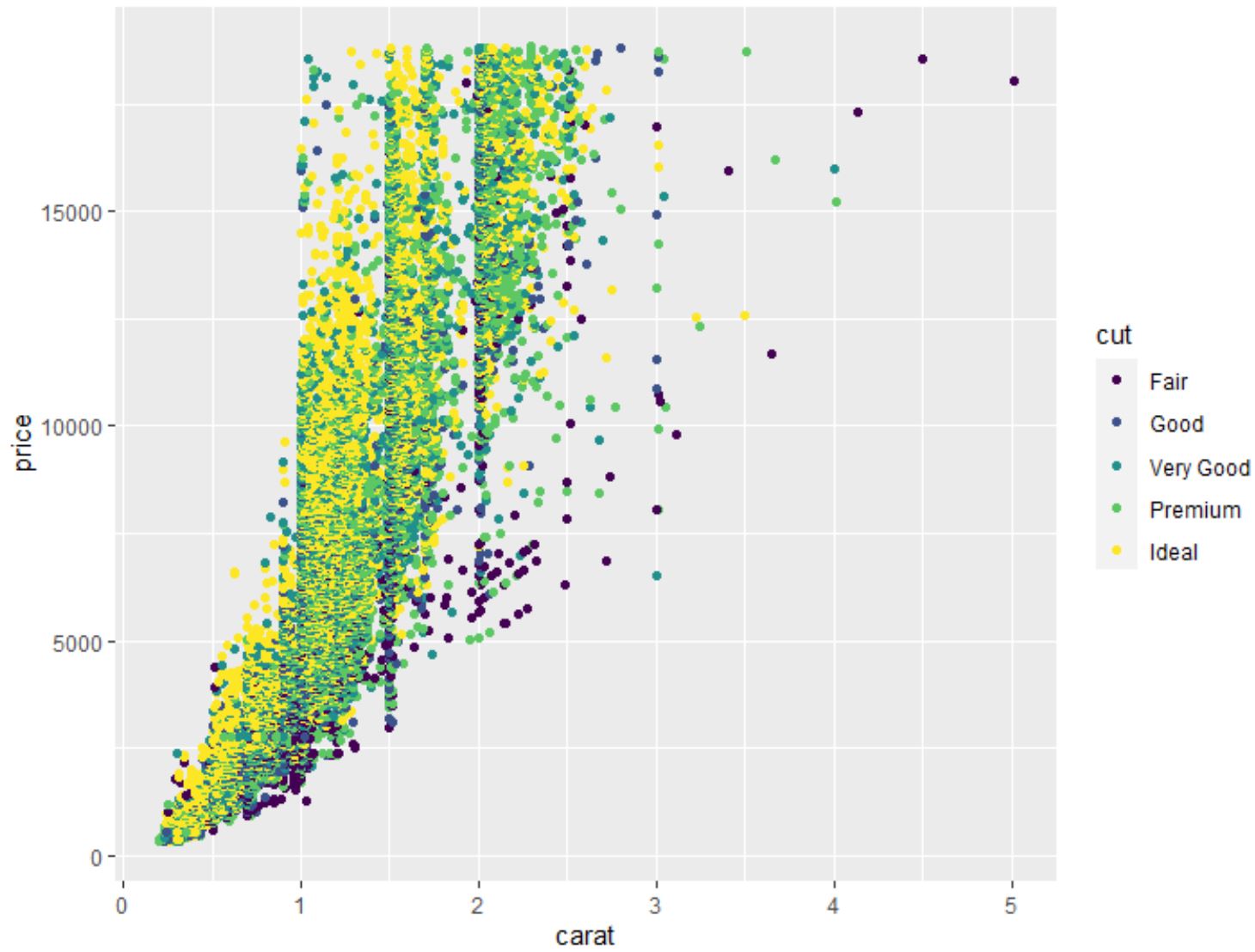
हम वेरिएबल्स के किसी भी जोड़ीदार संयोजन का पॉइंट क्लाउड बनाने के लिए जियोम_पॉइंट() फ़ंक्शन का भी उपयोग कर सकते हैं:
#create scatterplot of carat vs. price, using cut as color variable
ggplot(data=diamonds, aes (x=carat, y=price, color=cut)) +
geom_point()
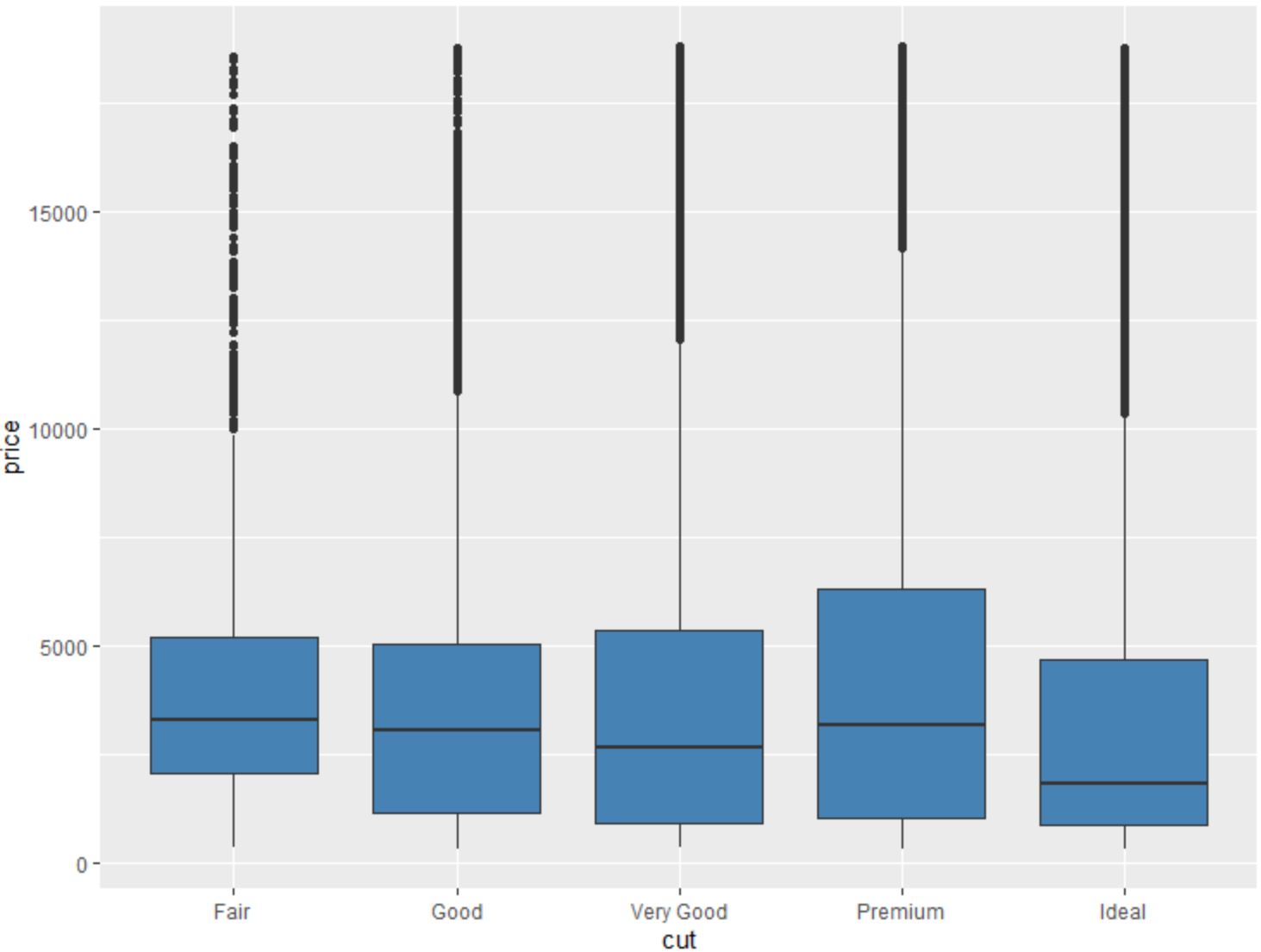
हम किसी अन्य वेरिएबल द्वारा समूहीकृत वेरिएबल का बॉक्सप्लॉट बनाने के लिए जियोम_बॉक्सप्लॉट() फ़ंक्शन का भी उपयोग कर सकते हैं:
#create scatterplot of price, grouped by cut
ggplot(data=diamonds, aes (x=cut, y=price)) +
geom_boxplot(fill=" steelblue ")
इन ggplot2 फ़ंक्शंस का उपयोग करके, हम डायमंड डेटासेट में वेरिएबल्स के बारे में बहुत कुछ सीख सकते हैं।
अतिरिक्त संसाधन
निम्नलिखित ट्यूटोरियल बताते हैं कि आर में अन्य डेटासेट का पता कैसे लगाया जाए:
आर में आइरिस डेटासेट के लिए एक संपूर्ण गाइड
आर में एमटीकार्स डेटासेट के लिए एक संपूर्ण मार्गदर्शिका
लेखक के बारे में
डॉ. बेंजामिन एंडरसन
नमस्ते, मैं बेंजामिन हूं, एक सेवानिवृत्त सांख्यिकी प्रोफेसर जो अब समर्पित Statorials शिक्षक बन गया है। सांख्यिकी के क्षेत्र में व्यापक अनुभव और विशेषज्ञता के साथ, मैं Statorials के माध्यम से छात्रों को सशक्त बनाने के लिए अपना ज्ञान साझा करने के लिए उत्सुक हूं। अधिक जाने