पायथन में एकाधिक आरओसी वक्र कैसे प्लॉट करें (उदाहरण के साथ)
मशीन लर्निंग में वर्गीकरण मॉडल के प्रदर्शन की कल्पना करने का एक तरीका एक आरओसी वक्र बनाना है, जो “रिसीवर ऑपरेटिंग विशेषता” वक्र के लिए है।
अक्सर, आप एकाधिक वर्गीकरण मॉडल को एक ही डेटासेट में फिट करना चाह सकते हैं और प्रत्येक मॉडल के लिए एक आरओसी वक्र बनाना चाह सकते हैं ताकि यह कल्पना की जा सके कि कौन सा मॉडल डेटा पर सबसे अच्छा प्रदर्शन करता है।
निम्नलिखित चरण-दर-चरण उदाहरण दिखाता है कि पायथन में एकाधिक आरओसी वक्र कैसे प्लॉट करें।
चरण 1: आवश्यक पैकेज आयात करें
सबसे पहले, हम पायथन में कई आवश्यक पैकेज आयात करेंगे:
from sklearn import metrics
from sklearn import datasets
from sklearn. model_selection import train_test_split
from sklearn. linear_model import LogisticRegression
from sklearn. set import GradientBoostingClassifier
import numpy as np
import matplotlib. pyplot as plt
चरण 2: नकली डेटा बनाएं
इसके बाद, हम 1000 पंक्तियों, चार भविष्यवक्ता चर और एक बाइनरी प्रतिक्रिया चर के साथ एक नकली डेटासेट बनाने के लिए स्केलेर के मेक_क्लासिफिकेशन() फ़ंक्शन का उपयोग करेंगे:
#create fake dataset
X, y = datasets. make_classification (n_samples= 1000 ,
n_features= 4 ,
n_informative= 3 ,
n_redundant= 1 ,
random_state= 0 )
#split dataset into training and testing set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size= .3 , random_state= 0 )
चरण 3: एकाधिक मॉडल फिट करें और आरओसी वक्र प्लॉट करें
इसके बाद, हम एक लॉजिस्टिक रिग्रेशन मॉडल और फिर एक ग्रेडिएंट-एन्हांस्ड मॉडल को डेटा में फिट करेंगे और उसी प्लॉट पर प्रत्येक मॉडल के लिए आरओसी वक्र प्लॉट करेंगे:
#set up plotting area
plt. Figure (0). clf ()
#fit logistic regression model and plot ROC curve
model = LogisticRegression()
model. fit (X_train, y_train)
y_pred = model. predict_proba (X_test)[:, 1]
fpr, tpr, _ = metrics. roc_curve (y_test, y_pred)
auc = round(metrics. roc_auc_score (y_test, y_pred), 4)
plt. plot (fpr,tpr,label="Logistic Regression, AUC="+str(auc))
#fit gradient boosted model and plot ROC curve
model = GradientBoostingClassifier()
model. fit (X_train, y_train)
y_pred = model. predict_proba (X_test)[:, 1]
fpr, tpr, _ = metrics. roc_curve (y_test, y_pred)
auc = round(metrics. roc_auc_score (y_test, y_pred), 4)
plt. plot (fpr,tpr,label="Gradient Boosting, AUC="+str(auc))
#add legend
plt. legend ()
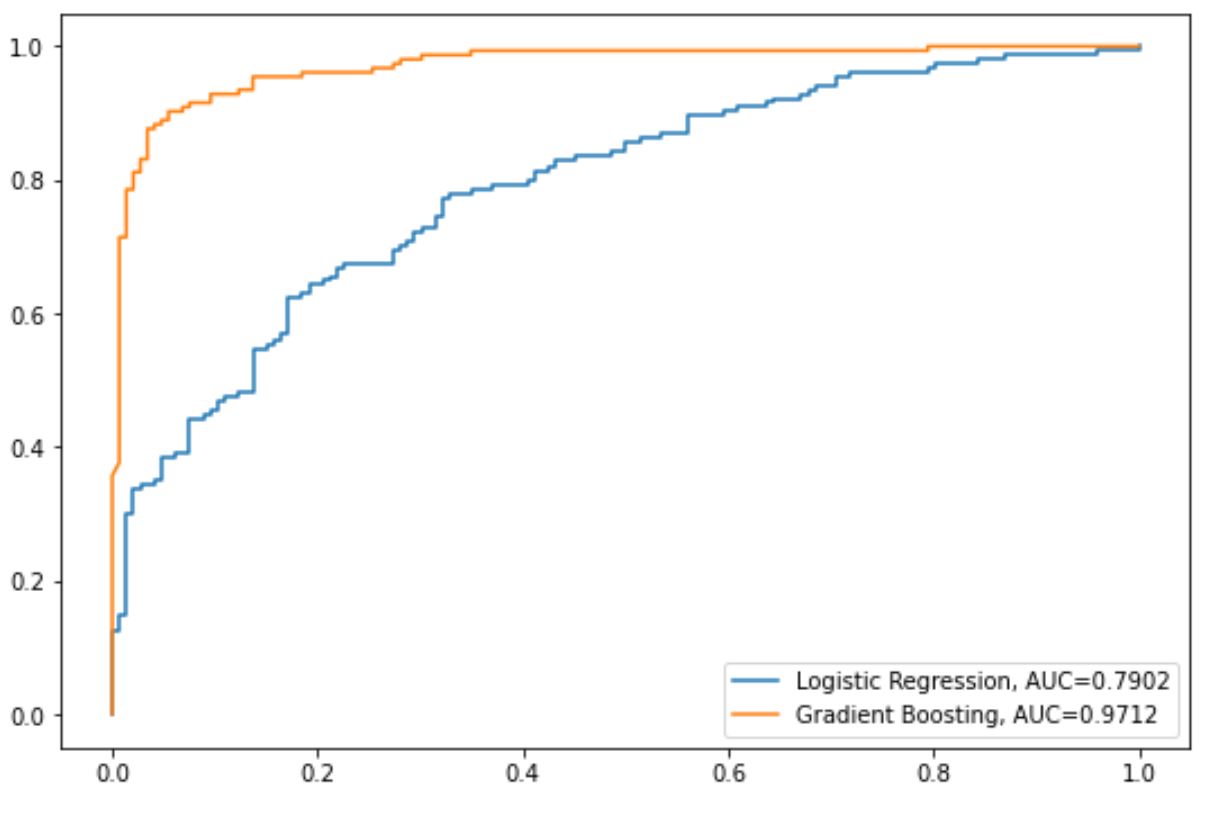
नीली रेखा लॉजिस्टिक रिग्रेशन मॉडल के लिए आरओसी वक्र दिखाती है और नारंगी रेखा ग्रेडिएंट बूस्टेड मॉडल के लिए आरओसी वक्र दिखाती है।
आरओसी वक्र प्लॉट के ऊपरी बाएँ कोने के जितना करीब फिट होता है, मॉडल उतना ही बेहतर डेटा को श्रेणियों में वर्गीकृत करने में सक्षम होता है।
इसे मापने के लिए, हम एयूसी – वक्र के नीचे का क्षेत्र – की गणना कर सकते हैं जो हमें बताता है कि प्लॉट का कितना हिस्सा वक्र के नीचे है।
AUC 1 के जितना करीब होगा, मॉडल उतना ही बेहतर होगा।
हमारे चार्ट से, हम प्रत्येक मॉडल के लिए निम्नलिखित एयूसी मेट्रिक्स देख सकते हैं:
- लॉजिस्टिक रिग्रेशन मॉडल का एयूसी: 0.7902
- ग्रेडिएंट बूस्टेड मॉडल का एयूसी: 0.9712
जाहिर है, ग्रेडिएंट-एन्हांस्ड मॉडल लॉजिस्टिक रिग्रेशन मॉडल की तुलना में डेटा को श्रेणियों में वर्गीकृत करने में अधिक सफल है।
अतिरिक्त संसाधन
निम्नलिखित ट्यूटोरियल वर्गीकरण मॉडल और आरओसी वक्रों के बारे में अतिरिक्त जानकारी प्रदान करते हैं:
लॉजिस्टिक रिग्रेशन का परिचय
आरओसी वक्र की व्याख्या कैसे करें (उदाहरण के साथ)
एक अच्छा AUC स्कोर क्या माना जाता है?
लेखक के बारे में
डॉ. बेंजामिन एंडरसन
नमस्ते, मैं बेंजामिन हूं, एक सेवानिवृत्त सांख्यिकी प्रोफेसर जो अब समर्पित Statorials शिक्षक बन गया है। सांख्यिकी के क्षेत्र में व्यापक अनुभव और विशेषज्ञता के साथ, मैं Statorials के माध्यम से छात्रों को सशक्त बनाने के लिए अपना ज्ञान साझा करने के लिए उत्सुक हूं। अधिक जाने