एक्सेल में covariance.p बनाम covariance.s: क्या अंतर है?
आँकड़ों में, सहप्रसरण यह मापने का एक तरीका है कि एक चर में परिवर्तन दूसरे चर में परिवर्तन से कैसे जुड़े हैं।
एक सकारात्मक सहप्रसरण मान इंगित करता है कि एक चर में वृद्धि दूसरे चर में वृद्धि के साथ जुड़ी हुई है।
एक नकारात्मक मान इंगित करता है कि एक चर में वृद्धि दूसरे चर में कमी के साथ जुड़ी हुई है।
एक्सेल में सहप्रसरण की गणना करने के लिए आप दो अलग-अलग फ़ंक्शन का उपयोग कर सकते हैं:
1. COVARIANCE.P: यह फ़ंक्शन जनसंख्या सहप्रसरण की गणना करता है। इस फ़ंक्शन का उपयोग तब करें जब मानों की श्रेणी संपूर्ण जनसंख्या का प्रतिनिधित्व करती हो।
यह फ़ंक्शन निम्न सूत्र का उपयोग करता है:
जनसंख्या सहप्रसरण = Σ(x i – x )(y i – y ) / n
सोना:
- Σ: एक ग्रीक प्रतीक जिसका अर्थ है “योग”
- x i : वेरिएबल x का i वां मान
- x : चर x का औसत मान
- y i : वेरिएबल y का iवां मान
- y : चर y का औसत मान
- n: अवलोकनों की कुल संख्या
2. सहप्रसरण.एस: यह फ़ंक्शन नमूना सहप्रसरण की गणना करता है। इस फ़ंक्शन का उपयोग तब करें जब मानों की श्रेणी संपूर्ण जनसंख्या के बजाय मानों के नमूने का प्रतिनिधित्व करती हो।
यह फ़ंक्शन निम्न सूत्र का उपयोग करता है:
नमूना सहप्रसरण = Σ(x i – x )(y i – y ) / (n-1)
सोना:
- Σ: एक ग्रीक प्रतीक जिसका अर्थ है “योग”
- x i : वेरिएबल x का i वां मान
- x : चर x का औसत मान
- y i : वेरिएबल y का iवां मान
- y : चर y का औसत मान
- n: अवलोकनों की कुल संख्या
दोनों सूत्रों के बीच सूक्ष्म अंतर पर ध्यान दें: COVARIANCE.P, n से विभाजित होता है जबकि COVARIANCE.S, n-1 से विभाजित होता है।
इस कारण से, COVARIANCE.S सूत्र हमेशा बड़ा मान उत्पन्न करेगा क्योंकि यह छोटे मान से विभाजित होता है।
निम्नलिखित उदाहरण दिखाता है कि व्यवहार में प्रत्येक सूत्र का उपयोग कैसे करें।
उदाहरण: एक्सेल में COVARIANCE.P बनाम COVARIANCE.S
मान लीजिए कि हमारे पास एक्सेल में निम्नलिखित डेटा सेट है जो 15 अलग-अलग बास्केटबॉल खिलाड़ियों के अंक और सहायता दिखाता है:
निम्नलिखित स्क्रीनशॉट दिखाता है कि दो अलग-अलग सहप्रसरण फ़ार्मुलों का उपयोग करके बिंदुओं और सहायताओं के बीच सहप्रसरण की गणना कैसे करें:
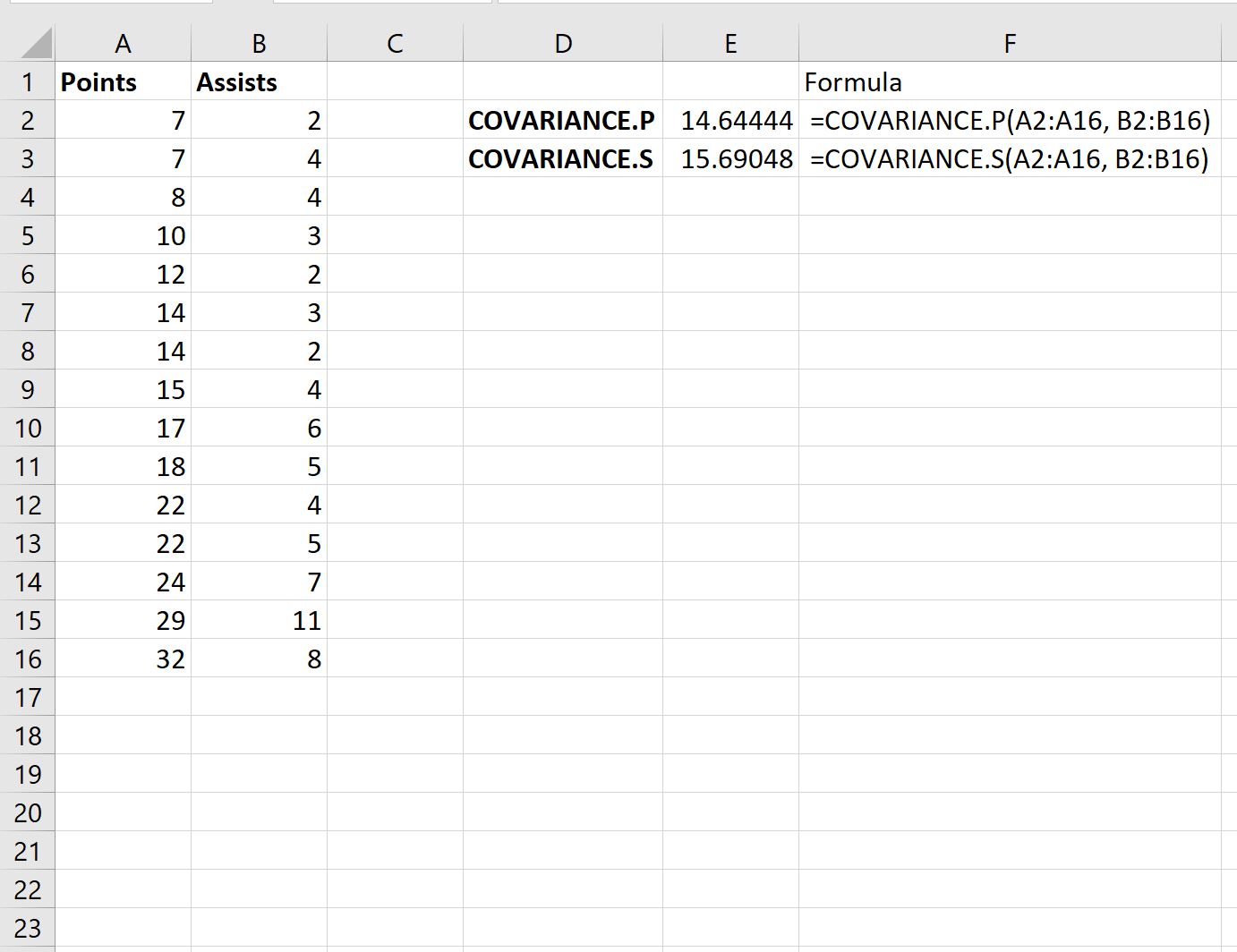
नमूना सहप्रसरण 15.69 निकला और जनसंख्या सहप्रसरण 14.64 निकला।
जैसा कि पहले उल्लेख किया गया है, नमूना सहप्रसरण हमेशा जनसंख्या सहप्रसरण से बड़ा होगा।
COVARIANCE.P या COVARIANCE.S का उपयोग कब करें
अधिकांश मामलों में हम पूरी जनसंख्या का डेटा एकत्र करने में सक्षम नहीं होते हैं। इसलिए हम केवल जनसंख्या के नमूने के लिए डेटा एकत्र करते हैं।
इसलिए, हम डेटा सेट के सहप्रसरण की गणना करने के लिए लगभग हमेशा COVARIANCE.S का उपयोग करते हैं क्योंकि हमारा डेटा सेट आम तौर पर एक नमूने का प्रतिनिधित्व करता है।
दुर्लभ मामलों में जहां आपका डेटा संपूर्ण जनसंख्या का प्रतिनिधित्व करता है, आप इसके बजाय COVARIANCE.P फ़ंक्शन का उपयोग कर सकते हैं।
अतिरिक्त संसाधन
निम्नलिखित ट्यूटोरियल आमतौर पर उपयोग किए जाने वाले अन्य एक्सेल फ़ंक्शंस के बीच अंतर बताते हैं:
एक्सेल में STDEV.P बनाम STDEV.S: क्या अंतर है?
Excel में PERCENTILE.EXC बनाम PERCENTILE.INC: क्या अंतर है?
एक्सेल में QUARTILE.EXC बनाम QUARTILE.INC: क्या अंतर है?
लेखक के बारे में
डॉ. बेंजामिन एंडरसन
नमस्ते, मैं बेंजामिन हूं, एक सेवानिवृत्त सांख्यिकी प्रोफेसर जो अब समर्पित Statorials शिक्षक बन गया है। सांख्यिकी के क्षेत्र में व्यापक अनुभव और विशेषज्ञता के साथ, मैं Statorials के माध्यम से छात्रों को सशक्त बनाने के लिए अपना ज्ञान साझा करने के लिए उत्सुक हूं। अधिक जाने