एनोवा टेबल
इस लेख में आपको एनोवा तालिका का स्पष्टीकरण मिलेगा। तो हम आपको समझाते हैं कि एनोवा टेबल क्या है, एनोवा टेबल कैसे बनाएं, एनोवा टेबल के सूत्र क्या हैं और इसके अलावा, आप चरण दर चरण हल किए गए अभ्यास को देख पाएंगे।
एनोवा टेबल क्या है?
एनोवा तालिका एक तालिका है जिसका उपयोग सांख्यिकी में विचरण के विश्लेषण में किया जाता है। अधिक विशेष रूप से, एनोवा तालिका में विचरण के विश्लेषण के लिए आवश्यक सभी जानकारी शामिल है।
इसलिए, एनोवा तालिका का उपयोग विचरण के विश्लेषण को सारांशित करने के लिए किया जाता है। किसी तालिका में विचरण के विश्लेषण की गणना करके, आप आसानी से निष्कर्ष निकाल सकते हैं और आपको एनोवा परीक्षण आंकड़ों के मूल्य की तुरंत गणना करने की अनुमति भी दे सकते हैं।
एनोवा तालिका सूत्र
एक-तरफ़ा एनोवा तालिका में, तीन पंक्तियाँ होती हैं: कारक, त्रुटि और कुल। इस प्रकार, एनोवा तालिका में, प्रत्येक पंक्ति के वर्गों के योग और उनकी स्वतंत्रता की डिग्री की गणना की जाती है। इसके अतिरिक्त, कारक और त्रुटि की माध्य वर्ग त्रुटि की गणना की जाती है और अंत में, एनोवा परीक्षण आँकड़ा निर्धारित किया जाता है, जो वर्ग त्रुटियों के अनुपात के बराबर है।
इसलिए एनोवा तालिका के सूत्र इस प्रकार हैं:
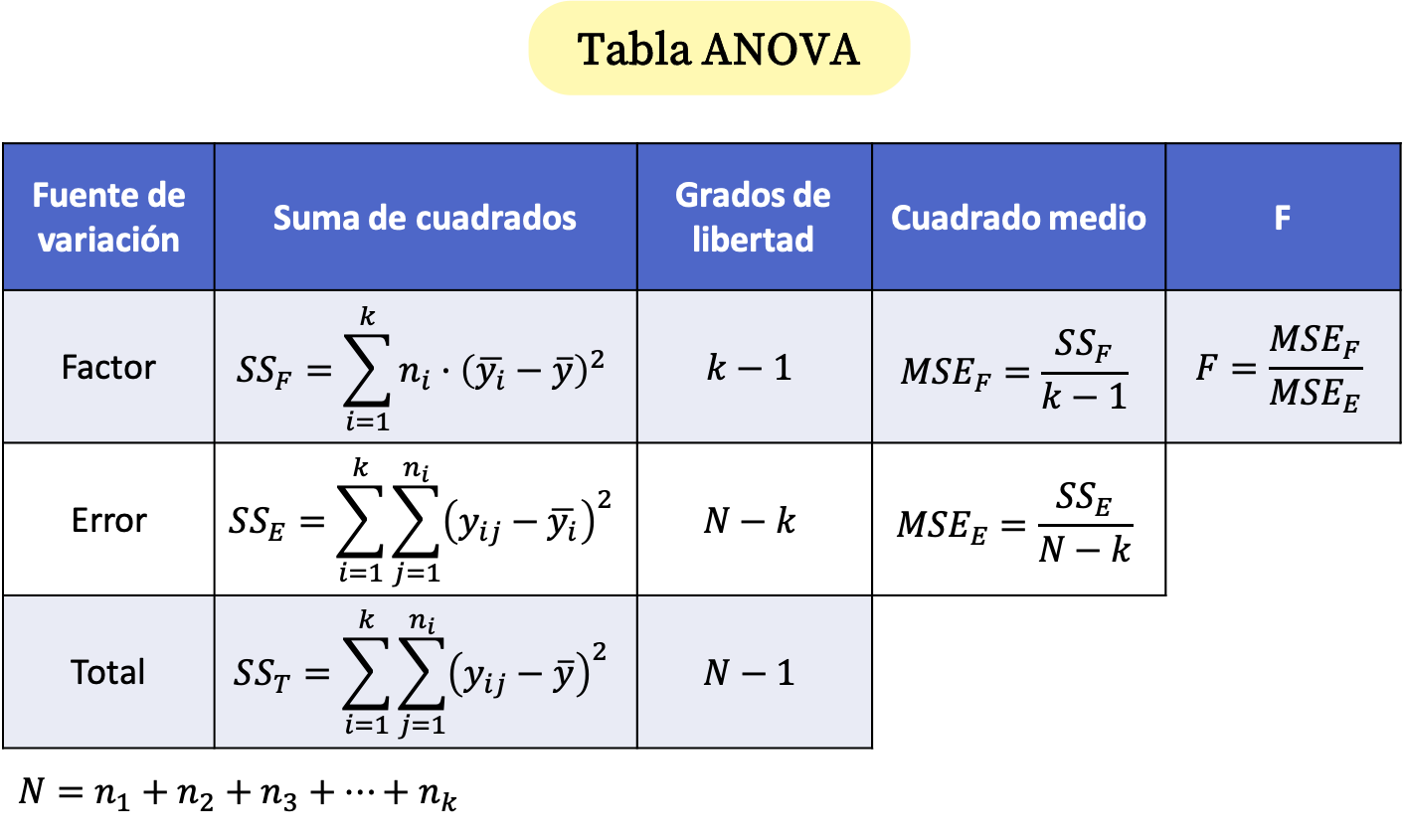
सोना:
-

नमूना आकार है I
-

प्रेक्षणों की कुल संख्या है.
-

विचरण के विश्लेषण में विभिन्न समूहों की संख्या है।
-

समूह i का मान j है।
-

समूह I का माध्य है.
-

यह सभी विश्लेषित आंकड़ों का औसत है।
एनोवा तालिका का उदाहरण
अवधारणा को अच्छी तरह से समझने के लिए, आइए देखें कि चरण दर चरण एक उदाहरण को हल करके एनोवा तालिका कैसे बनाई जाए।
- तीन अलग-अलग विषयों (ए, बी और सी) में चार छात्रों द्वारा प्राप्त अंकों की तुलना करने के लिए एक सांख्यिकीय अध्ययन किया जाता है। निम्नलिखित तालिका प्रत्येक छात्र द्वारा एक परीक्षा में प्राप्त अंकों का विवरण देती है जिसका अधिकतम अंक 20 है। प्रत्येक विषय में प्रत्येक छात्र द्वारा प्राप्त अंकों की तुलना करने के लिए एनोवा तालिका का निर्माण करें।
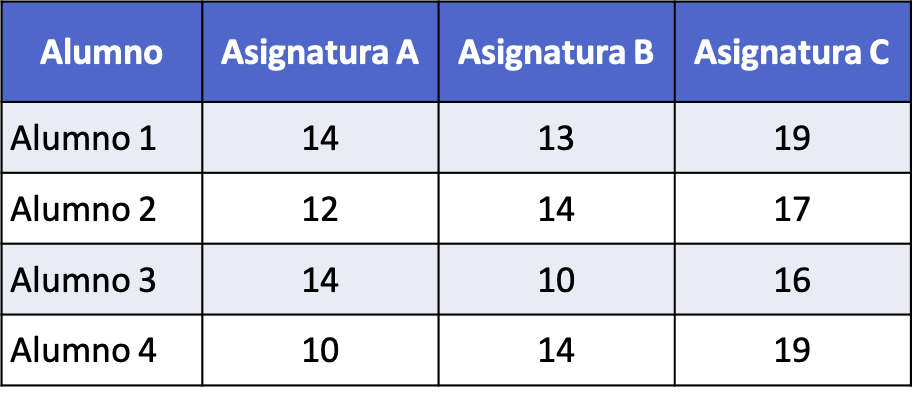
पहली चीज़ जो हमें करने की ज़रूरत है वह प्रत्येक विषय के औसत और डेटा के कुल औसत की गणना करना है:




एक बार जब हमें माध्य का मूल्य पता चल जाता है, तो हम एनोवा तालिका में सूत्रों का उपयोग करके वर्गों के योग की गणना करते हैं (ऊपर देखें):
![\begin{aligned}\displaystyle SS_F&=\sum_{i=1}^k n_i(\overline{y}_i-\overline{y})^2\\[2ex] SS_F&= 4\cdot (12,5-14,33)^2+4\cdot (12,75-14,33)^2+4\cdot (17,75-14,33)^2\\[2ex] SS_F&=70,17\end{aligned}](https://statorials.org/wp-content/ql-cache/quicklatex.com-77b3fecdc3b577841da684cd80297288_l3.png "Rendered by QuickLaTeX.com")
![\begin{aligned}\displaystyle SS_E=&\sum_{i=1}^k\sum_{j=1}^{n_i} (y_{ij}-\overline{y}_i)^2\\[2ex] \displaystyle SS_E=\ &(14-12,5)^2+(12-12,5)^2+(14-12,5)^2+(10-12,5)^2+\\&+(13-12,75)^2+(14-12,75)^2+(10-12,75)^2+(14-12,75)^2+\\&+(19-17,75)^2+(17-17,75)^2+(16-17,75)^2+(19-17,75)^2\\[2ex] SS_E=\ &28,50\end{aligned}](https://statorials.org/wp-content/ql-cache/quicklatex.com-aa02f1b826df45c26ead3537ecc4c7e5_l3.png "Rendered by QuickLaTeX.com")
![\begin{aligned}\displaystyle SS_T=&\sum_{i=1}^k\sum_{j=1}^{n_i} (y_{ij}-\overline{y})^2\\[2ex] \displaystyle SS_T= \ &(14-14,33)^2+(12-14,33)^2+(14-14,33)^2+(10-14,33)^2+\\&+(13-14,33)^2+(14-14,33)^2+(10-14,33)^2+(14-14,33)^2+\\&+(19-14,33)^2+(17-14,33)^2+(16-14,33)^2+(19-14,33)^2\\[2ex] SS_T= \ &98,67\end{aligned}](https://statorials.org/wp-content/ql-cache/quicklatex.com-2eb66d1d37653749f38916c905108a3b_l3.png "Rendered by QuickLaTeX.com")
फिर हम कारक, त्रुटि और कुल की स्वतंत्रता की डिग्री निर्धारित करते हैं:



अब हम कारक और त्रुटि के वर्गों के योग को उनकी स्वतंत्रता की संबंधित डिग्री से विभाजित करके माध्य वर्ग त्रुटियों की गणना करते हैं:


और अंत में, हम पिछले चरण में गणना की गई दो त्रुटियों को विभाजित करके एफ आंकड़े के मूल्य की गणना करते हैं:

संक्षेप में, उदाहरण डेटा के लिए एनोवा तालिका इस तरह दिखेगी:

एक बार एनोवा तालिका में सभी मूल्यों की गणना हो जाने के बाद, जो कुछ बचा है वह इसकी व्याख्या करना है। ऐसा करने के लिए, हमें एफ आँकड़ा, जिसे पी-वैल्यू कहा जाता है, के मान के अनुरूप संभाव्यता की तुलना करनी होगी। आप निम्न लिंक पर क्लिक करके देख सकते हैं कि यह कैसे किया जाता है:
लेखक के बारे में
डॉ. बेंजामिन एंडरसन
नमस्ते, मैं बेंजामिन हूं, एक सेवानिवृत्त सांख्यिकी प्रोफेसर जो अब समर्पित Statorials शिक्षक बन गया है। सांख्यिकी के क्षेत्र में व्यापक अनुभव और विशेषज्ञता के साथ, मैं Statorials के माध्यम से छात्रों को सशक्त बनाने के लिए अपना ज्ञान साझा करने के लिए उत्सुक हूं। अधिक जाने