पांडा: एक्सेल फ़ाइल आयात करते समय विशिष्ट कॉलमों को अनदेखा करें
किसी Excel फ़ाइल को पांडा डेटाफ़्रेम में आयात करते समय विशिष्ट कॉलमों को अनदेखा करने के लिए आप निम्नलिखित मूल सिंटैक्स का उपयोग कर सकते हैं:
#define columns to skip skip_cols = [1, 2] #define columns to keep keep_cols = [i for i in range (4) if i not in skip_cols] #import Excel file and skip specific columns df = pd. read_excel (' my_data.xlsx ', usecols=keep_cols)
यह विशेष उदाहरण my_data.xlsx नामक एक्सेल फ़ाइल को पांडा में आयात करते समय सूचकांक स्थिति 1 और 2 में कॉलम को अनदेखा कर देगा।
निम्नलिखित उदाहरण दिखाता है कि व्यवहार में इस वाक्यविन्यास का उपयोग कैसे करें।
उदाहरण: पांडा में एक्सेल फ़ाइल आयात करते समय विशिष्ट कॉलमों को अनदेखा करें
मान लीजिए कि हमारे पास प्लेयर_डेटा.xlsx नामक निम्नलिखित एक्सेल फ़ाइल है:
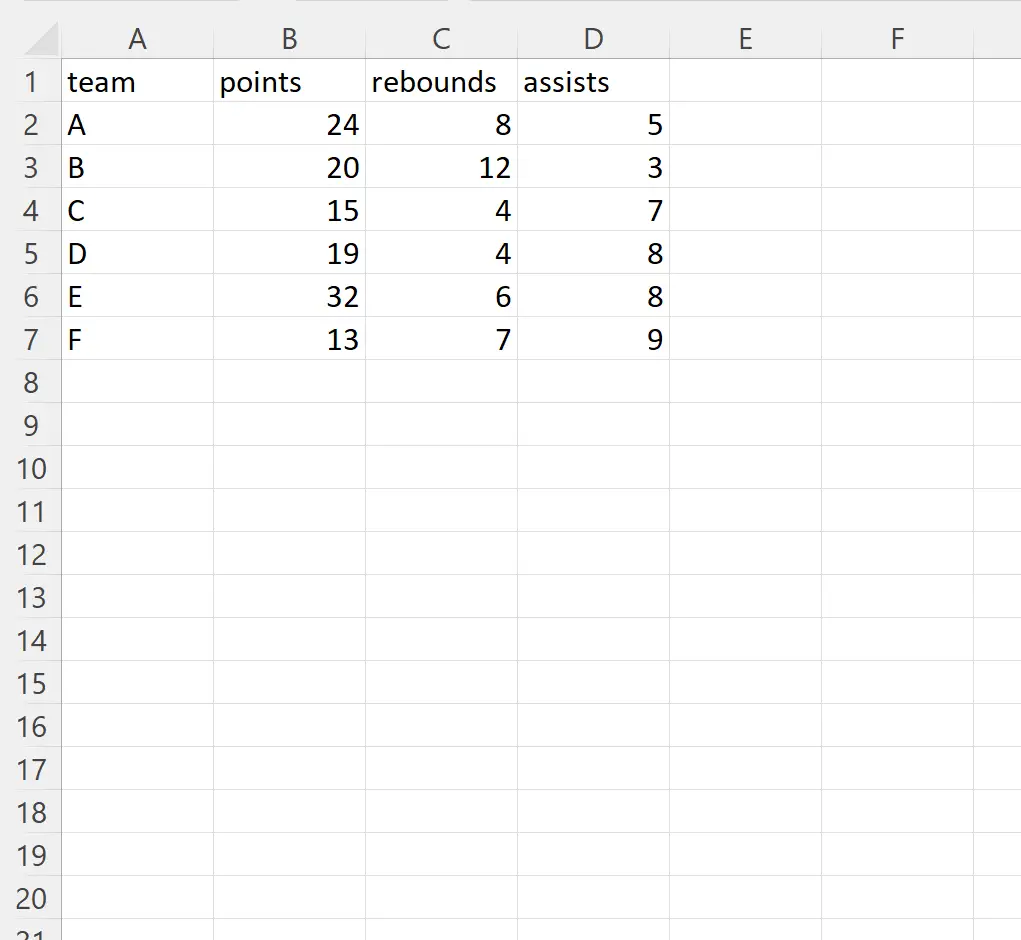
हम इस फ़ाइल को पांडा डेटाफ़्रेम में आयात करने के लिए निम्नलिखित सिंटैक्स का उपयोग कर सकते हैं और आयात के दौरान इंडेक्स स्थिति 1 और 2 (डॉट और बाउंस कॉलम) में कॉलम को अनदेखा कर सकते हैं:
#define columns to skip skip_cols = [1, 2] #define columns to keep keep_cols = [i for i in range (4) if i not in skip_cols] #import Excel file and skip specific columns df = pd. read_excel (' player_data.xlsx ', usecols=keep_cols) #view DataFrame print (df) team assists 0 to 5 1 B 3 2 C 7 3 D 8 4 E 8 5 F 9
ध्यान दें कि एक्सेल फ़ाइल में इंडेक्स पोजीशन 1 और 2 (पॉइंट और बाउंस कॉलम) के कॉलम को छोड़कर सभी कॉलम पांडा डेटाफ़्रेम में आयात किए गए हैं।
ध्यान दें कि यह विधि मानती है कि आपको पहले से पता है कि एक्सेल फ़ाइल में कितने कॉलम हैं।
चूँकि हमें पता था कि फ़ाइल में कुल 4 कॉलम हैं, हमने उन कॉलमों को परिभाषित करने के लिए रेंज (4) का उपयोग किया जिन्हें हम रखना चाहते थे।
नोट : आप पांडा read_excel() फ़ंक्शन का पूरा दस्तावेज़ यहां पा सकते हैं।
अतिरिक्त संसाधन
निम्नलिखित ट्यूटोरियल बताते हैं कि पांडा में अन्य सामान्य कार्य कैसे करें:
पांडा: एक्सेल फ़ाइल पढ़ते समय पंक्तियों को कैसे छोड़ें
पांडा: एक्सेल फ़ाइल आयात करते समय प्रकार कैसे निर्दिष्ट करें
पांडा: एकाधिक एक्सेल शीट को कैसे संयोजित करें
लेखक के बारे में
डॉ. बेंजामिन एंडरसन
नमस्ते, मैं बेंजामिन हूं, एक सेवानिवृत्त सांख्यिकी प्रोफेसर जो अब समर्पित Statorials शिक्षक बन गया है। सांख्यिकी के क्षेत्र में व्यापक अनुभव और विशेषज्ञता के साथ, मैं Statorials के माध्यम से छात्रों को सशक्त बनाने के लिए अपना ज्ञान साझा करने के लिए उत्सुक हूं। अधिक जाने