पायथन में कुक की दूरी की गणना कैसे करें
कुक की दूरी का उपयोग प्रतिगमन मॉडल में प्रभावशाली अवलोकनों की पहचान करने के लिए किया जाता है।
कुक की दूरी का सूत्र है:
डी आई = (आर आई 2 / पी*एमएसई) * (एच II / (1-एच II ) 2 )
सोना:
- आर मैं मैं वें अवशेष है
- p प्रतिगमन मॉडल में गुणांकों की संख्या है
- एमएसई माध्य वर्ग त्रुटि है
- h ii ith उत्तोलन मान है
अनिवार्य रूप से, कुक की दूरी मापती है कि i वें अवलोकन को हटा दिए जाने पर मॉडल के सभी फिट किए गए मान कितने बदल जाते हैं।
कुक की दूरी का मान जितना बड़ा होगा, दिया गया अवलोकन उतना ही अधिक प्रभावशाली होगा।
एक सामान्य नियम के रूप में, कुक की दूरी 4/n (जहां n = कुल अवलोकन) से अधिक होने वाले किसी भी अवलोकन को बड़ा प्रभाव माना जाता है।
यह ट्यूटोरियल पायथन में दिए गए प्रतिगमन मॉडल के लिए कुक की दूरी की गणना करने का चरण-दर-चरण उदाहरण प्रदान करता है।
चरण 1: डेटा दर्ज करें
सबसे पहले, हम पायथन में काम करने के लिए एक छोटा डेटासेट बनाएंगे:
import pandas as pd #create dataset df = pd. DataFrame ({' x ': [8, 12, 12, 13, 14, 16, 17, 22, 24, 26, 29, 30], ' y ': [41, 42, 39, 37, 35, 39, 45, 46, 39, 49, 55, 57]})
चरण 2: प्रतिगमन मॉडल को फ़िट करें
इसके बाद, हम एक सरल रैखिक प्रतिगमन मॉडल फिट करेंगे:
import statsmodels. api as sm
#define response variable
y = df[' y ']
#define explanatory variable
x = df[' x ']
#add constant to predictor variables
x = sm. add_constant (x)
#fit linear regression model
model = sm. OLS (y,x). fit ()
चरण 3: कुक दूरी की गणना करें
इसके बाद, हम मॉडल में प्रत्येक अवलोकन के लिए कुक दूरी की गणना करेंगे:
#suppress scientific notation
import numpy as np
n.p. set_printoptions (suppress= True )
#create instance of influence
influence = model. get_influence ()
#obtain Cook's distance for each observation
cooks = influence. cooks_distance
#display Cook's distances
print (cooks)
(array([0.368, 0.061, 0.001, 0.028, 0.105, 0.022, 0.017, 0. , 0.343,
0. , 0.15 , 0.349]),
array([0.701, 0.941, 0.999, 0.973, 0.901, 0.979, 0.983, 1. , 0.718,
1. , 0.863, 0.713]))
डिफ़ॉल्ट रूप से, cooks_distance() फ़ंक्शन प्रत्येक अवलोकन के लिए कुक की दूरी के लिए मानों की एक सरणी प्रदर्शित करता है, जिसके बाद संबंधित पी-मानों की एक सरणी प्रदर्शित होती है।
उदाहरण के लिए:
- अवलोकन के लिए कुक की दूरी #1: 0.368 (पी-मान: 0.701)
- अवलोकन #2 के लिए कुक की दूरी: 0.061 (पी-मान: 0.941)
- अवलोकन के लिए कुक की दूरी #3: 0.001 (पी-मान: 0.999)
और इसी तरह।
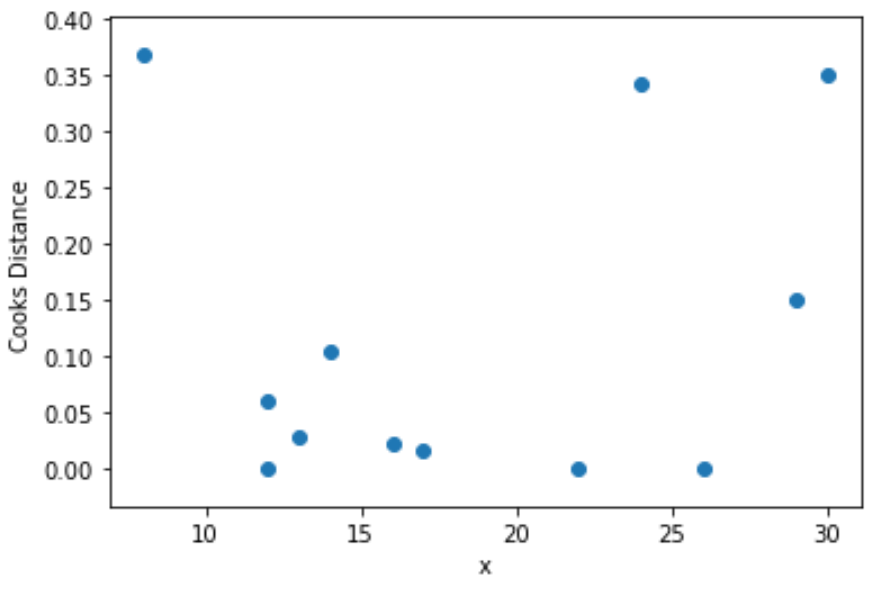
चरण 4: रसोइये की दूरियों की कल्पना करें
अंत में, हम प्रत्येक अवलोकन के लिए कुक की दूरी के एक फ़ंक्शन के रूप में भविष्यवक्ता चर के मूल्यों की कल्पना करने के लिए एक स्कैटरप्लॉट बना सकते हैं:
import matplotlib. pyplot as plt
plt. scatter (df.x, cooks[0])
plt. xlabel (' x ')
plt. ylabel (' Cooks Distance ')
plt. show ()
अंतिम विचार
यह ध्यान रखना महत्वपूर्ण है कि संभावित प्रभावशाली टिप्पणियों की पहचान करने के लिए कुक की दूरी का उपयोग किया जाना चाहिए। सिर्फ इसलिए कि कोई अवलोकन प्रभावशाली है इसका मतलब यह नहीं है कि उसे डेटासेट से हटा दिया जाना चाहिए।
सबसे पहले, आपको यह सत्यापित करना होगा कि अवलोकन डेटा प्रविष्टि त्रुटि या अन्य अजीब घटना का परिणाम नहीं है। यदि यह एक वैध मान साबित होता है, तो आप यह तय कर सकते हैं कि क्या इसे हटाना उचित है, इसे वैसे ही छोड़ दें, या बस इसे माध्यिका जैसे वैकल्पिक मान से बदल दें।
लेखक के बारे में
डॉ. बेंजामिन एंडरसन
नमस्ते, मैं बेंजामिन हूं, एक सेवानिवृत्त सांख्यिकी प्रोफेसर जो अब समर्पित Statorials शिक्षक बन गया है। सांख्यिकी के क्षेत्र में व्यापक अनुभव और विशेषज्ञता के साथ, मैं Statorials के माध्यम से छात्रों को सशक्त बनाने के लिए अपना ज्ञान साझा करने के लिए उत्सुक हूं। अधिक जाने