एफ डिस्ट्रीब्यूशन बोर्ड को कैसे पढ़ें
यह ट्यूटोरियल बताता है कि एफ वितरण तालिका को कैसे पढ़ा जाए और उसकी व्याख्या कैसे की जाए।
एफ वितरण तालिका क्या है?
एफ वितरण तालिका एक तालिका है जो एफ वितरण के महत्वपूर्ण मूल्यों को दर्शाती है। F वितरण तालिका का उपयोग करने के लिए, आपको केवल तीन मानों की आवश्यकता है:
- अंश की स्वतंत्रता की डिग्री
- हर की स्वतंत्रता की डिग्री
- अल्फ़ा स्तर (सामान्य विकल्प 0.01, 0.05 और 0.10 हैं)
निम्न तालिका अल्फा = 0.10 के लिए एफ वितरण तालिका दिखाती है। तालिका के शीर्ष पर स्थित संख्याएँ अंश की स्वतंत्रता की डिग्री (तालिका में DF1 लेबल) का प्रतिनिधित्व करती हैं और तालिका के बाईं ओर की संख्याएँ हर की स्वतंत्रता की डिग्री (तालिका में DF2 लेबल) का प्रतिनिधित्व करती हैं।
ज़ूम करने के लिए बेझिझक टेबल पर क्लिक करें।
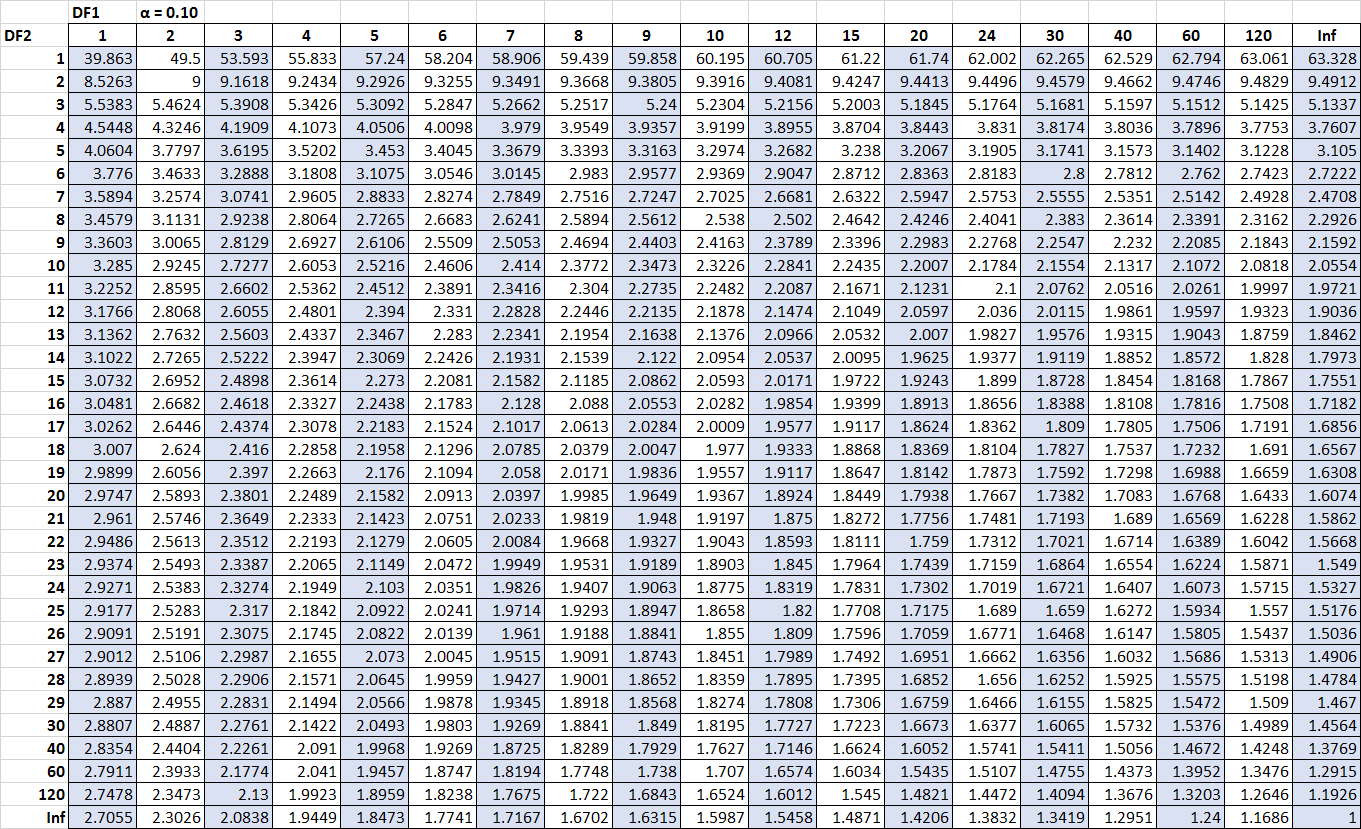
तालिका में महत्वपूर्ण मानों की तुलना अक्सर F परीक्षण के F आँकड़े से की जाती है। यदि एफ आँकड़ा तालिका में पाए गए महत्वपूर्ण मान से अधिक है, तो आप एफ परीक्षण की शून्य परिकल्पना को अस्वीकार कर सकते हैं और निष्कर्ष निकाल सकते हैं कि परीक्षण के परिणाम सांख्यिकीय रूप से महत्वपूर्ण हैं।
एफ वितरण तालिका का उपयोग करने के उदाहरण
एफ परीक्षण के लिए महत्वपूर्ण मान ज्ञात करने के लिए एफ वितरण तालिका का उपयोग किया जाता है। तीन सबसे सामान्य परिदृश्य जिनमें आप एफ परीक्षण करेंगे, वे हैं:
- प्रतिगमन मॉडल के समग्र महत्व का परीक्षण करने के लिए प्रतिगमन विश्लेषण में एफ-परीक्षण।
- समूह साधनों के बीच समग्र अंतर का परीक्षण करने के लिए एनोवा (विचरण का विश्लेषण) में एफ परीक्षण।
- एफ परीक्षण यह पता लगाने के लिए कि क्या दो आबादी में समान भिन्नताएं हैं।
आइए इनमें से प्रत्येक परिदृश्य में एफ वितरण तालिका का उपयोग करने का एक उदाहरण देखें।
प्रतिगमन विश्लेषण में एफ टेस्ट
मान लीजिए कि हम अध्ययन किए गए घंटों और पूर्वसूचक चर के रूप में ली गई प्रारंभिक परीक्षाओं और प्रतिक्रिया चर के रूप में अंतिम परीक्षा ग्रेड का उपयोग करके एक बहु रेखीय प्रतिगमन विश्लेषण करते हैं। जब हम प्रतिगमन विश्लेषण चलाते हैं, तो हमें निम्नलिखित परिणाम प्राप्त होते हैं:
| स्रोत | एसएस | डीएफ | एमएस। | एफ | पी। |
|---|---|---|---|---|---|
| वापसी | 546.53 | 2 | 273.26 | 5.09 | 0.033 |
| अवशिष्ट | 483.13 | 9 | 53.68 | ||
| कुल | 1029.66 | 11 |
प्रतिगमन विश्लेषण में, एफ सांख्यिकी की गणना प्रतिगमन एमएस/अवशिष्ट एमएस के रूप में की जाती है। यह आँकड़ा इंगित करता है कि क्या प्रतिगमन मॉडल उस मॉडल की तुलना में डेटा के लिए बेहतर फिट प्रदान करता है जिसमें कोई स्वतंत्र चर नहीं है। मूलतः, यह परीक्षण करता है कि समग्र रूप से प्रतिगमन मॉडल उपयोगी है या नहीं।
इस उदाहरण में, एफ आँकड़ा 273.26 / 53.68 = 5.09 है ।
मान लीजिए हम जानना चाहते हैं कि क्या यह एफ आँकड़ा अल्फा = 0.05 स्तर पर महत्वपूर्ण है। अल्फ़ा = 0.05 के लिए एफ वितरण तालिका का उपयोग करते हुए, स्वतंत्रता की अंश डिग्री 2 ( प्रतिगमन के लिए डीएफ) और स्वतंत्रता की हर डिग्री 9 ( अवशिष्ट के लिए डीएफ) के साथ, हम पाते हैं कि महत्वपूर्ण मान एफ 4, 2565 है।
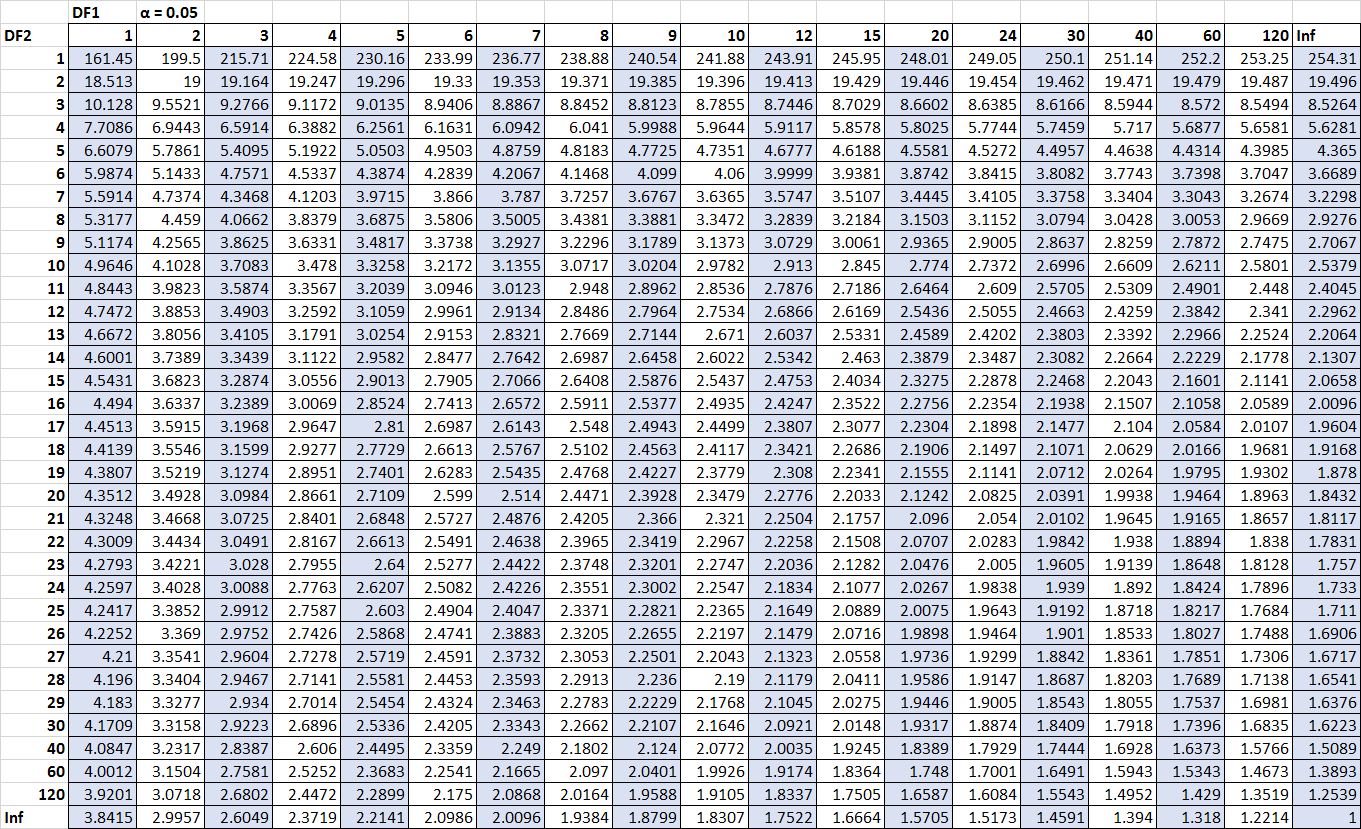
चूँकि हमारा आँकड़ा f( 5.09 ) महत्वपूर्ण मान F( 4.2565) से अधिक है, हम यह निष्कर्ष निकाल सकते हैं कि समग्र रूप से प्रतिगमन मॉडल सांख्यिकीय रूप से महत्वपूर्ण है।
एनोवा में एफ परीक्षण
मान लीजिए हम जानना चाहते हैं कि तीन अलग-अलग अध्ययन तकनीकों से अलग-अलग परीक्षण परिणाम मिलते हैं या नहीं। इसका परीक्षण करने के लिए हम 60 छात्रों की भर्ती कर रहे हैं। हम बेतरतीब ढंग से 20 छात्रों को एक परीक्षा की तैयारी के लिए एक महीने के लिए तीन अध्ययन तकनीकों में से एक का उपयोग करने के लिए नियुक्त करते हैं। एक बार जब सभी छात्रों ने परीक्षा दे दी, तो हम यह निर्धारित करने के लिए एक-तरफ़ा एनोवा का प्रदर्शन करते हैं कि अध्ययन तकनीक का परीक्षा परिणामों पर प्रभाव पड़ता है या नहीं। निम्न तालिका एक-तरफ़ा एनोवा के परिणाम दिखाती है:
| स्रोत | एसएस | डीएफ | एमएस। | एफ | पी। |
|---|---|---|---|---|---|
| इलाज | 58.8 | 2 | 29.4 | 1.74 | 0.217 |
| गलती | 202.8 | 12 | 16.9 | ||
| कुल | 261.6 | 14 |
एनोवा में, एफ सांख्यिकी की गणना उपचार एमएस/त्रुटि एमएस के रूप में की जाती है। यह आँकड़ा बताता है कि तीनों समूहों का औसत स्कोर बराबर है या नहीं।
इस उदाहरण में, एफ आँकड़ा 29.4 / 16.9 = 1.74 है ।
मान लीजिए हम जानना चाहते हैं कि क्या यह एफ आँकड़ा अल्फा = 0.05 स्तर पर महत्वपूर्ण है। अल्फ़ा = 0.05 के लिए एफ वितरण तालिका का उपयोग करते हुए, स्वतंत्रता की अंश डिग्री 2 ( उपचार के लिए डीएफ) और स्वतंत्रता की हर डिग्री 12 ( त्रुटि के लिए डीएफ) के साथ, हम पाते हैं कि महत्वपूर्ण मान एफ 3, 8853 है।
चूंकि हमारा एफ आँकड़ा ( 1.74 ) महत्वपूर्ण मान एफ ( 3.8853) से अधिक नहीं है, हम निष्कर्ष निकालते हैं कि तीन समूहों के औसत स्कोर के बीच कोई सांख्यिकीय महत्वपूर्ण अंतर नहीं है।
दो जनसंख्याओं के समान प्रसरणों के लिए एफ परीक्षण
मान लीजिए हम जानना चाहते हैं कि दो जनसंख्याओं के प्रसरण बराबर हैं या नहीं। इसका परीक्षण करने के लिए, हम समान भिन्नताओं के लिए एक एफ-परीक्षण कर सकते हैं जिसमें हम प्रत्येक जनसंख्या से 25 अवलोकनों का एक यादृच्छिक नमूना लेते हैं और प्रत्येक नमूने के लिए नमूना भिन्नता पाते हैं।
इस एफ-टेस्ट के परीक्षण आँकड़े को इस प्रकार परिभाषित किया गया है:
सांख्यिकी एफ = एस 1 2 / एस 2 2
जहां s 1 2 और s 2 2 नमूना भिन्नताएं हैं। यह अनुपात एक से जितना अधिक होगा, जनसंख्या के भीतर असमान भिन्नताओं के प्रमाण उतने ही मजबूत होंगे।
एफ परीक्षण का महत्वपूर्ण मूल्य इस प्रकार परिभाषित किया गया है:
महत्वपूर्ण मान F = वितरण तालिका F में n 1 -1 और n 2 -1 स्वतंत्रता की डिग्री और α के महत्व स्तर के साथ पाया गया मान।
मान लें कि नमूना 1 के लिए नमूना भिन्नता 30.5 है और नमूना 2 के लिए नमूना भिन्नता 20.5 है। इसका मतलब है कि हमारा परीक्षण आँकड़ा 30.5 / 20.5 = 1.487 है। यह पता लगाने के लिए कि क्या यह परीक्षण आँकड़ा अल्फा = 0.10 पर महत्वपूर्ण है, हम अल्फा = 0.10, अंश डीएफ = 24 और हर डीएफ = 24 से जुड़ी एफ वितरण तालिका में महत्वपूर्ण मान पा सकते हैं। यह संख्या 1.7019 निकली है। .
चूँकि हमारा आँकड़ा f( 1.487 ) महत्वपूर्ण मान F( 1.7019) से अधिक नहीं है, हम निष्कर्ष निकालते हैं कि इन दो आबादी के भिन्नताओं के बीच कोई सांख्यिकीय महत्वपूर्ण अंतर नहीं है।
अतिरिक्त संसाधन
अल्फा मान 0.001, 0.01, 0.025, 0.05 और 0.10 के लिए एफ वितरण तालिकाओं के पूरे सेट के लिए, यह पृष्ठ देखें।
लेखक के बारे में
डॉ. बेंजामिन एंडरसन
नमस्ते, मैं बेंजामिन हूं, एक सेवानिवृत्त सांख्यिकी प्रोफेसर जो अब समर्पित Statorials शिक्षक बन गया है। सांख्यिकी के क्षेत्र में व्यापक अनुभव और विशेषज्ञता के साथ, मैं Statorials के माध्यम से छात्रों को सशक्त बनाने के लिए अपना ज्ञान साझा करने के लिए उत्सुक हूं। अधिक जाने