एसएएस: डिलीमीटर द्वारा स्ट्रिंग्स को कैसे विभाजित करें
आप किसी विशेष सीमांकक के आधार पर स्ट्रिंग को शीघ्रता से विभाजित करने के लिए एसएएस में स्कैन() फ़ंक्शन का उपयोग कर सकते हैं।
निम्नलिखित उदाहरण दिखाता है कि व्यवहार में इस फ़ंक्शन का उपयोग कैसे करें।
उदाहरण: एसएएस में डिलीमीटर द्वारा स्ट्रिंग को विभाजित करें
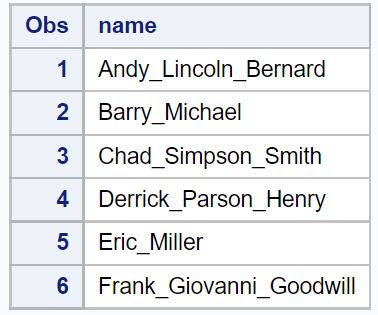
आइए मान लें कि हमारे पास एसएएस में निम्नलिखित डेटा सेट है:
/*create dataset*/ data my_data1; input name $25.; datalines ; Andy_Lincoln_Bernard Barry_Michael Chad_Simpson_Smith Derrick_Parson_Henry Eric_Miller Frank_Giovanni_Goodwill ; run ; /*print dataset*/ proc print data =my_data1;
हम नाम स्ट्रिंग को तीन अलग-अलग स्ट्रिंग में तुरंत विभाजित करने के लिए निम्नलिखित कोड का उपयोग कर सकते हैं:
/*create second dataset with name split into three columns*/ data my_data2; set my_data1; name1= scan (name, 1 , '_'); name2= scan (name, 2 , '_'); name3= scan (name, 3 , '_'); run ; /*view second dataset*/ proc print data =my_data2;
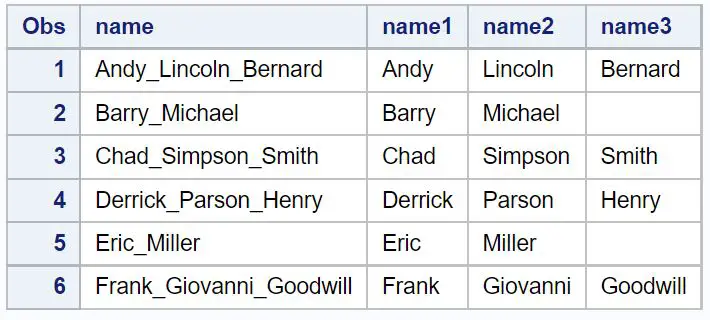
ध्यान दें कि नाम कॉलम स्ट्रिंग को तीन नए कॉलम में विभाजित किया गया है।
उन नामों के लिए जिनके लिए केवल एक सीमांकक है, name3 कॉलम में मान बस खाली है।
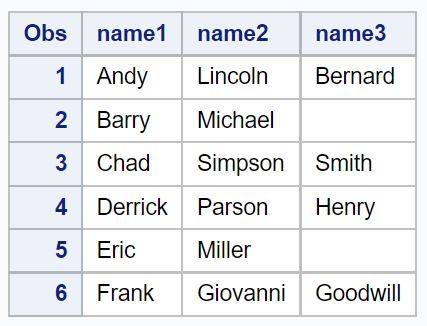
ध्यान दें कि हम नए डेटासेट से मूल नाम कॉलम को हटाने के लिए ड्रॉप फ़ंक्शन का भी उपयोग कर सकते हैं:
/*create second dataset with name split into three columns, drop original name*/ data my_data2; set my_data1; name1= scan (name, 1 , '_'); name2= scan (name, 2 , '_'); name3= scan (name, 3 , '_'); dropname ; run ; /*view second dataset*/ proc print data =my_data2;
अतिरिक्त संसाधन
निम्नलिखित ट्यूटोरियल बताते हैं कि एसएएस में अन्य सामान्य कार्य कैसे करें:
एसएएस में डेटा को सामान्य कैसे करें
एसएएस में वेरिएबल्स का नाम कैसे बदलें
एसएएस में डुप्लिकेट कैसे हटाएं
एसएएस में लुप्त मानों को शून्य से कैसे बदलें
लेखक के बारे में
डॉ. बेंजामिन एंडरसन
नमस्ते, मैं बेंजामिन हूं, एक सेवानिवृत्त सांख्यिकी प्रोफेसर जो अब समर्पित Statorials शिक्षक बन गया है। सांख्यिकी के क्षेत्र में व्यापक अनुभव और विशेषज्ञता के साथ, मैं Statorials के माध्यम से छात्रों को सशक्त बनाने के लिए अपना ज्ञान साझा करने के लिए उत्सुक हूं। अधिक जाने