पांडा में मूविंग एवरेज की गणना कैसे करें
एक चलती औसत एक समय श्रृंखला में पिछली कई अवधियों का औसत मात्र है।
पांडा डेटाफ़्रेम में एक या अधिक कॉलम के रोलिंग औसत की गणना करने के लिए, हम निम्नलिखित सिंटैक्स का उपयोग कर सकते हैं:
df[' column_name ']. rolling ( rolling_window ). mean ()
यह ट्यूटोरियल इस फ़ंक्शन के व्यावहारिक उपयोग के कई उदाहरण प्रदान करता है।
उदाहरण: पांडा में चलती औसत की गणना
मान लीजिए हमारे पास निम्नलिखित पांडा डेटाफ़्रेम हैं:
import numpy as np import pandas as pd #make this example reproducible n.p. random . seeds (0) #create dataset period = np. arange (1, 101, 1) leads = np. random . uniform (1, 20, 100) sales = 60 + 2*period + np. random . normal (loc=0, scale=.5*period, size=100) df = pd. DataFrame ({' period ': period, ' leads ': leads, ' sales ': sales}) #view first 10 rows df. head (10) period leads sales 0 1 11.427457 61.417425 1 2 14.588598 64.900826 2 3 12.452504 66.698494 3 4 11.352780 64.927513 4 5 9.049441 73.720630 5 6 13.271988 77.687668 6 7 9.314157 78.125728 7 8 17.943687 75.280301 8 9 19.309592 73.181613 9 10 8.285389 85.272259
हम पिछले 5 अवधियों के लिए “बिक्री” की चलती औसत वाला एक नया कॉलम बनाने के लिए निम्नलिखित सिंटैक्स का उपयोग कर सकते हैं:
#find rolling mean of previous 5 sales periods df[' rolling_sales_5 '] = df[' sales ']. rolling (5). mean () #view first 10 rows df. head (10) period leads sales rolling_sales_5 0 1 11.427457 61.417425 NaN 1 2 14.588598 64.900826 NaN 2 3 12.452504 66.698494 NaN 3 4 11.352780 64.927513 NaN 4 5 9.049441 73.720630 66.332978 5 6 13.271988 77.687668 69.587026 6 7 9.314157 78.125728 72.232007 7 8 17.943687 75.280301 73.948368 8 9 19.309592 73.181613 75.599188 9 10 8.285389 85.272259 77.909514
हम मैन्युअल रूप से सत्यापित कर सकते हैं कि अवधि 5 के लिए प्रदर्शित रोलिंग बिक्री औसत पिछली 5 अवधियों का औसत है:
अवधि 5 में चलती औसत: (61.417+64.900+66.698+64.927+73.720)/5 = 66.33
हम कई कॉलमों की चलती औसत की गणना करने के लिए समान सिंटैक्स का उपयोग कर सकते हैं:
#find rolling mean of previous 5 leads periods df[' rolling_leads_5 '] = df[' leads ']. rolling (5). mean () #find rolling mean of previous 5 leads periods df[' rolling_sales_5 '] = df[' sales ']. rolling (5). mean () #view first 10 rows df. head (10) period leads sales rolling_sales_5 rolling_leads_5 0 1 11.427457 61.417425 NaN NaN 1 2 14.588598 64.900826 NaN NaN 2 3 12.452504 66.698494 NaN NaN 3 4 11.352780 64.927513 NaN NaN 4 5 9.049441 73.720630 66.332978 11.774156 5 6 13.271988 77.687668 69.587026 12.143062 6 7 9.314157 78.125728 72.232007 11.088174 7 8 17.943687 75.280301 73.948368 12.186411 8 9 19.309592 73.181613 75.599188 13.777773 9 10 8.285389 85.272259 77.909514 13.624963
सकल बिक्री बनाम चलती बिक्री औसत की कल्पना करने के लिए हम मैटप्लोटलिब का उपयोग करके एक त्वरित लाइन प्लॉट भी बना सकते हैं:
import matplotlib. pyplot as plt
plt. plot (df[' rolling_sales_5 '], label=' Rolling Mean ')
plt. plot (df[' sales '], label=' Raw Data ')
plt. legend ()
plt. ylabel (' Sales ')
plt. xlabel (' Period ')
plt. show ()
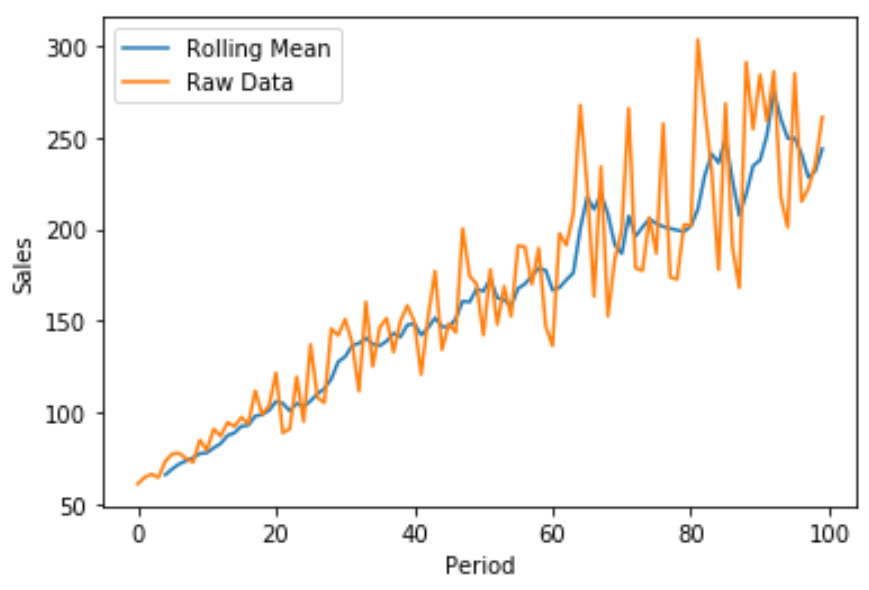
नीली रेखा बिक्री की 5-अवधि की चलती औसत दिखाती है और नारंगी रेखा कच्चे बिक्री डेटा को दिखाती है।
अतिरिक्त संसाधन
निम्नलिखित ट्यूटोरियल बताते हैं कि पांडा में अन्य सामान्य कार्य कैसे करें:
पांडा में स्लाइडिंग सहसंबंध की गणना कैसे करें
पांडा में स्तंभों के औसत की गणना कैसे करें
लेखक के बारे में
डॉ. बेंजामिन एंडरसन
नमस्ते, मैं बेंजामिन हूं, एक सेवानिवृत्त सांख्यिकी प्रोफेसर जो अब समर्पित Statorials शिक्षक बन गया है। सांख्यिकी के क्षेत्र में व्यापक अनुभव और विशेषज्ञता के साथ, मैं Statorials के माध्यम से छात्रों को सशक्त बनाने के लिए अपना ज्ञान साझा करने के लिए उत्सुक हूं। अधिक जाने