आर में आइरिस डेटासेट के लिए एक संपूर्ण गाइड
आईरिस डेटासेट आर में एक एकीकृत डेटासेट है जिसमें 3 अलग-अलग प्रजातियों के 50 फूलों के लिए 4 अलग-अलग विशेषताओं (सेंटीमीटर में) पर माप शामिल हैं।
यह ट्यूटोरियल उदाहरण के रूप में आईरिस डेटासेट का उपयोग करके आर में डेटासेट का पता लगाने और सारांशित करने का तरीका बताता है।
संबंधित: आर में एमटीकार्स डेटासेट के लिए एक संपूर्ण गाइड
आईरिस डेटासेट लोड करें
चूँकि आईरिस डेटासेट R में एक अंतर्निहित डेटासेट है, हम इसे निम्नलिखित कमांड का उपयोग करके लोड कर सकते हैं:
data(iris)
हम हेड() फ़ंक्शन का उपयोग करके डेटासेट की पहली छह पंक्तियों पर एक नज़र डाल सकते हैं:
#view first six rows of iris dataset
head(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
आईरिस डेटासेट को संक्षेप में प्रस्तुत करें
हम डेटासेट में प्रत्येक चर को शीघ्रता से सारांशित करने के लिए सारांश() फ़ंक्शन का उपयोग कर सकते हैं:
#summarize iris dataset
summary(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width
Min. :4,300 Min. :2,000 Min. :1,000 Min. :0.100
1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600 1st Qu.:0.300
Median: 5,800 Median: 3,000 Median: 4,350 Median: 1,300
Mean:5.843 Mean:3.057 Mean:3.758 Mean:1.199
3rd Qu.:6,400 3rd Qu.:3,300 3rd Qu.:5,100 3rd Qu.:1,800
Max. :7,900 Max. :4,400 Max. :6,900 Max. :2,500
Species
setosa:50
versicolor:50
virginica :50
प्रत्येक संख्यात्मक चर के लिए हम निम्नलिखित जानकारी देख सकते हैं:
- न्यूनतम : न्यूनतम मान.
- पहला Qu : प्रथम चतुर्थक (25वाँ प्रतिशतक) का मान।
- माध्यिका : माध्यिका मान.
- औसत : औसत मूल्य.
- तीसरा Qu : तीसरे चतुर्थक (75वें प्रतिशतक) का मान।
- अधिकतम : अधिकतम मान.
डेटासेट (प्रजाति) में एकमात्र श्रेणीबद्ध चर के लिए, हम प्रत्येक मान की आवृत्ति गणना देखते हैं:
- सेटोसा : यह प्रजाति 50 बार मौजूद है।
- वर्सिकलर : यह प्रजाति 50 बार पाई जाती है।
- वर्जिनिका : यह प्रजाति 50 बार मौजूद है।
हम पंक्तियों और स्तंभों की संख्या के संदर्भ में डेटासेट के आयाम प्राप्त करने के लिए dim() फ़ंक्शन का उपयोग कर सकते हैं:
#display rows and columns
dim(iris)
[1] 150 5
हम देख सकते हैं कि डेटासेट में 150 पंक्तियाँ और 5 कॉलम हैं।
हम डेटा फ़्रेम के कॉलम नाम प्रदर्शित करने के लिए नेम्स() फ़ंक्शन का भी उपयोग कर सकते हैं:
#display column names
names(iris)
[1] "Sepal.Length" "Sepal.Width" "Petal.Length" "Petal.Width" "Species"
आइरिस डेटासेट को विज़ुअलाइज़ करें
हम डेटासेट के मूल्यों की कल्पना करने के लिए प्लॉट भी बना सकते हैं।
उदाहरण के लिए, हम एक निश्चित चर के मानों का हिस्टोग्राम बनाने के लिए हिस्ट() फ़ंक्शन का उपयोग कर सकते हैं:
#create histogram of values for sepal length
hist(iris$Sepal.Length,
col=' steelblue ',
main=' Histogram ',
xlab=' Length ',
ylab=' Frequency ')
हम वेरिएबल्स के किसी भी जोड़ीदार संयोजन का स्कैटरप्लॉट बनाने के लिए प्लॉट() फ़ंक्शन का भी उपयोग कर सकते हैं:
#create scatterplot of sepal width vs. sepal length
plot(iris$Sepal.Width, iris$Sepal.Length,
col=' steelblue ',
main=' Scatterplot ',
xlab=' Sepal Width ',
ylab=' Sepal Length ',
pch= 19 )
हम प्रति समूह बॉक्सप्लॉट बनाने के लिए बॉक्सप्लॉट() फ़ंक्शन का भी उपयोग कर सकते हैं:
#create scatterplot of sepal width vs. sepal length
boxplot(Sepal.Length~Species,
data=iris,
main=' Sepal Length by Species ',
xlab=' Species ',
ylab=' Sepal Length ',
col=' steelblue ',
border=' black ')
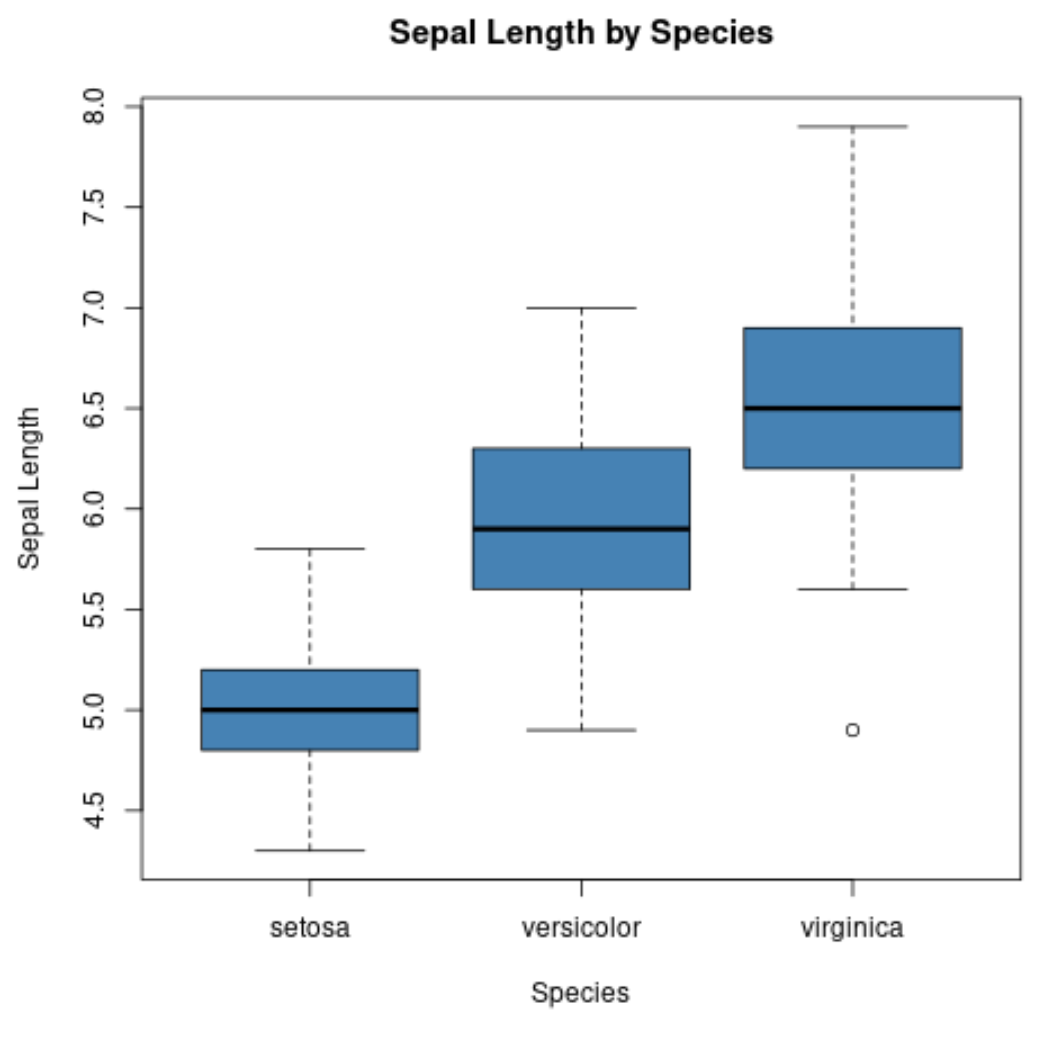
एक्स-अक्ष तीन प्रजातियों को प्रदर्शित करता है और वाई-अक्ष प्रत्येक प्रजाति के लिए सेपल लंबाई मानों का वितरण प्रदर्शित करता है।
इस प्रकार की साजिश हमें तुरंत यह देखने की अनुमति देती है कि बाह्यदलों की लंबाई वर्जिनिका प्रजाति के लिए सबसे बड़ी और सेटोसा प्रजाति के लिए सबसे छोटी होती है।
अतिरिक्त संसाधन
निम्नलिखित ट्यूटोरियल अधिक विस्तार से बताते हैं कि आर में डेटासेट को कैसे सारांशित किया जाए:
आर में सारांश तालिकाएँ बनाने का सबसे आसान तरीका
आर में पांच संख्याओं के सारांश की गणना कैसे करें
लेखक के बारे में
डॉ. बेंजामिन एंडरसन
नमस्ते, मैं बेंजामिन हूं, एक सेवानिवृत्त सांख्यिकी प्रोफेसर जो अब समर्पित Statorials शिक्षक बन गया है। सांख्यिकी के क्षेत्र में व्यापक अनुभव और विशेषज्ञता के साथ, मैं Statorials के माध्यम से छात्रों को सशक्त बनाने के लिए अपना ज्ञान साझा करने के लिए उत्सुक हूं। अधिक जाने