एक्सेल: दो कॉलमों के आधार पर डुप्लिकेट पंक्तियों को कैसे हटाएं
अक्सर आप एक्सेल में दो कॉलमों के आधार पर डुप्लिकेट पंक्तियों को हटाना चाह सकते हैं।
सौभाग्य से, डेटा टैब में डुप्लिकेट हटाएँ सुविधा का उपयोग करके ऐसा करना आसान है।
निम्नलिखित उदाहरण दिखाता है कि व्यवहार में इस फ़ंक्शन का उपयोग कैसे करें।
उदाहरण: एक्सेल में दो कॉलम के आधार पर डुप्लिकेट हटाएं
मान लीजिए कि हमारे पास निम्नलिखित डेटासेट है जो विभिन्न बास्केटबॉल खिलाड़ियों की टीम का नाम और स्थिति दिखाता है:
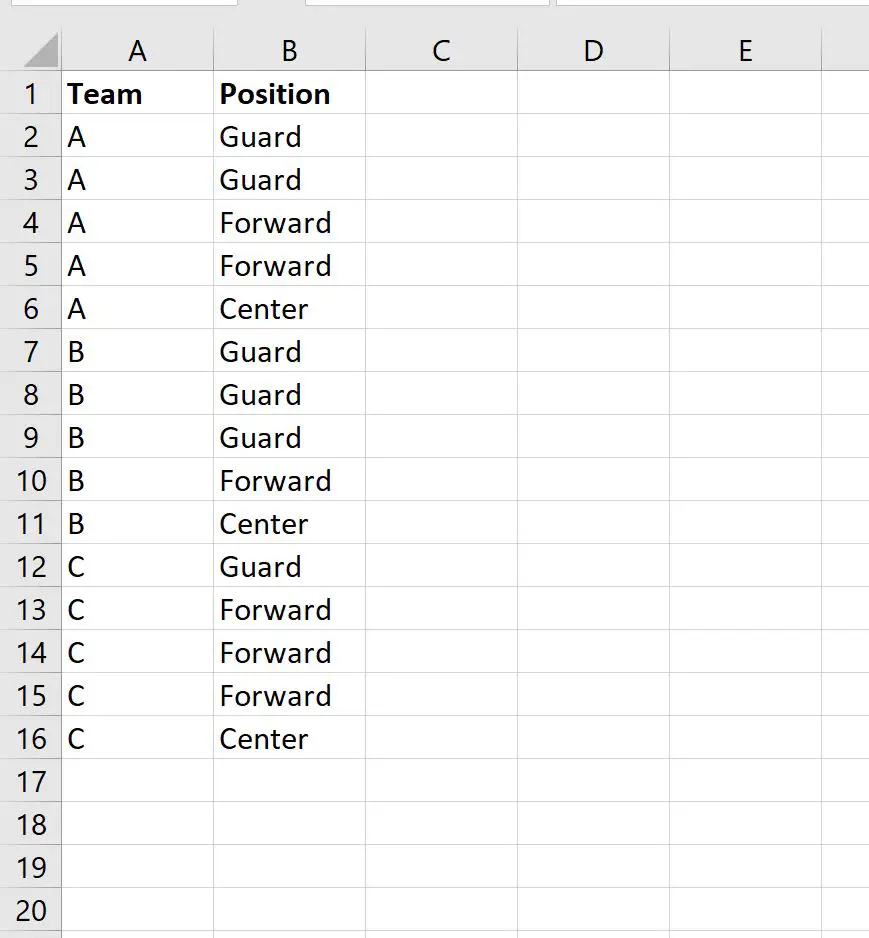
ध्यान दें कि दोनों कॉलम में कई डुप्लिकेट हैं।
उदाहरण के लिए:
- ऐसे कई खिलाड़ी हैं जिनके पास ए टीम और गार्ड पद है।
- ऐसे कई खिलाड़ी हैं जिनके पास ए टीम और स्ट्राइकर पोजीशन है।
और इसी तरह।
दो कॉलमों में डुप्लिकेट वाली इन पंक्तियों को हटाने के लिए, हमें सेल रेंज A1:B16 को हाइलाइट करना होगा, फिर शीर्ष रिबन के साथ डेटा टैब पर क्लिक करें, फिर डुप्लिकेट हटाएं पर क्लिक करें:
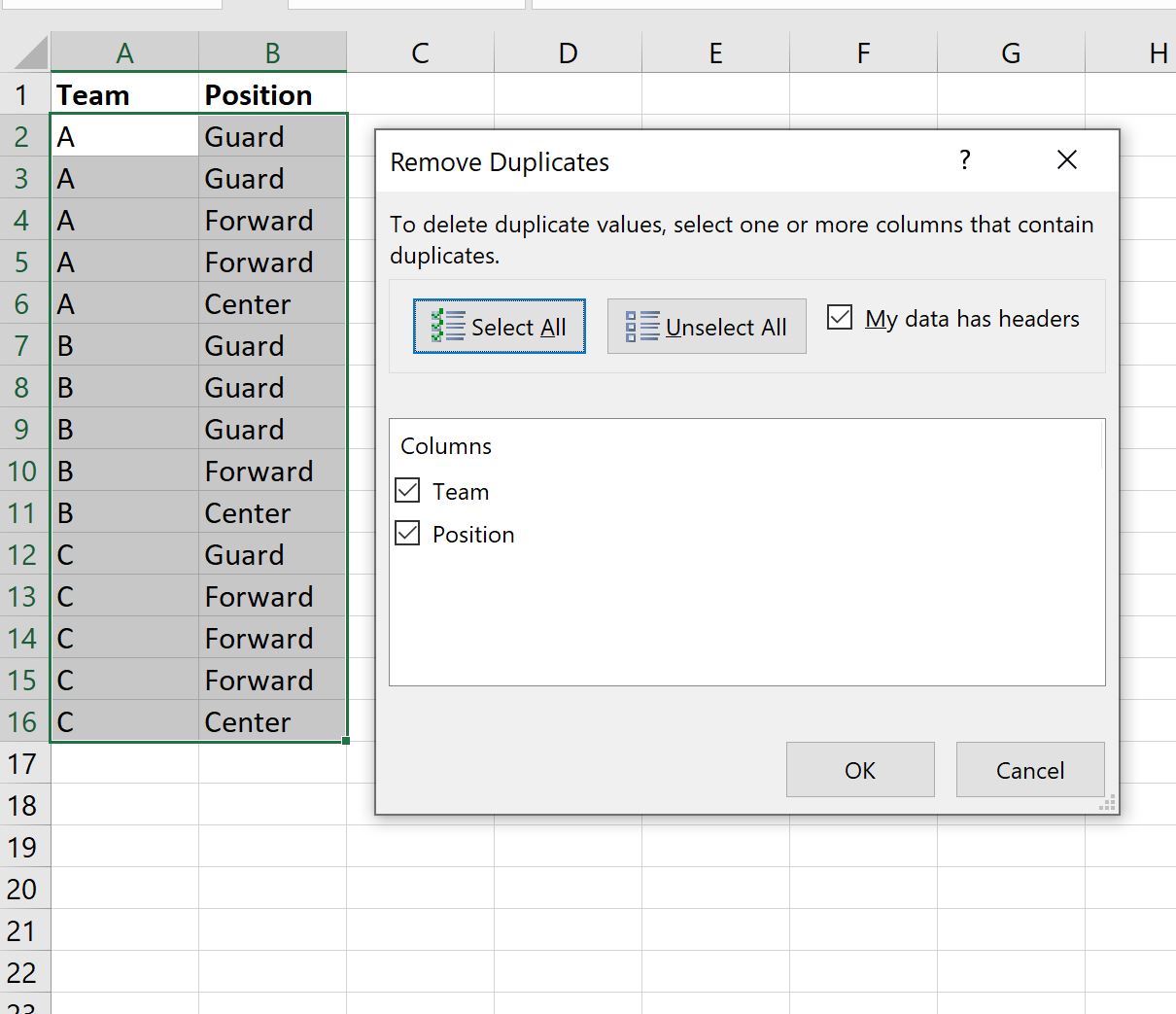
दिखाई देने वाली नई विंडो में, सुनिश्चित करें कि मेरे डेटा में हेडर के आगे वाला बॉक्स चेक किया गया है और सुनिश्चित करें कि टीम और स्थिति दोनों के आगे वाले बॉक्स चेक किए गए हैं:
एक बार जब आप ओके पर क्लिक करते हैं, तो दोनों कॉलम में डुप्लिकेट मान वाली पंक्तियाँ स्वचालित रूप से हटा दी जाएंगी:
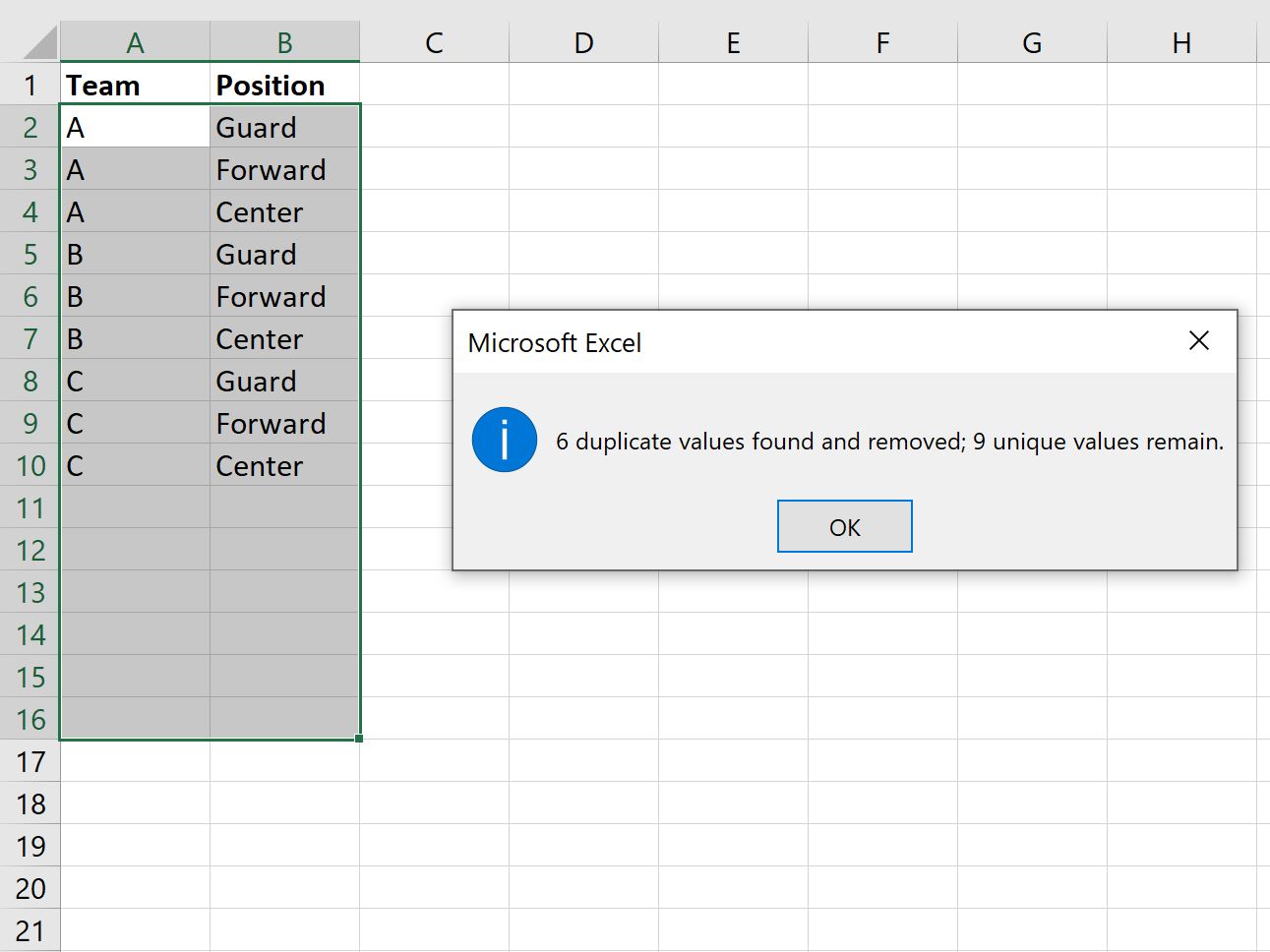
एक्सेल हमें बताता है कि 6 डुप्लिकेट पंक्तियाँ पाई गईं और हटा दी गईं और 9 अद्वितीय पंक्तियाँ शेष हैं।
ध्यान दें कि शेष किसी भी पंक्ति में किसी भी कॉलम में डुप्लिकेट मान नहीं हैं।
उदाहरण के लिए:
- केवल एक पंक्ति है जहां टीम ए के बराबर है और स्थिति गार्ड के बराबर है।
- केवल एक पंक्ति है जहां टीम ए के बराबर है और स्थिति फॉरवर्ड के बराबर है।
और इसी तरह।
अतिरिक्त संसाधन
निम्नलिखित ट्यूटोरियल बताते हैं कि एक्सेल में अन्य सामान्य ऑपरेशन कैसे करें:
एक्सेल: विशिष्ट टेक्स्ट वाली पंक्तियों को कैसे हटाएं
एक्सेल: फ़ार्मुलों का उपयोग करते समय रिक्त कक्षों को कैसे अनदेखा करें
एक्सेल उन्नत फ़िल्टर: गैर-रिक्त मानों वाली पंक्तियाँ दिखाएँ
लेखक के बारे में
डॉ. बेंजामिन एंडरसन
नमस्ते, मैं बेंजामिन हूं, एक सेवानिवृत्त सांख्यिकी प्रोफेसर जो अब समर्पित Statorials शिक्षक बन गया है। सांख्यिकी के क्षेत्र में व्यापक अनुभव और विशेषज्ञता के साथ, मैं Statorials के माध्यम से छात्रों को सशक्त बनाने के लिए अपना ज्ञान साझा करने के लिए उत्सुक हूं। अधिक जाने