एसएएस: दो वेरिएबल्स के आधार पर डेटासेट को कैसे मर्ज करें
आप दो चर के मिलान के आधार पर एसएएस में दो डेटा सेट को मर्ज करने के लिए निम्नलिखित मूल सिंटैक्स का उपयोग कर सकते हैं:
data final_data;
merge data1(in=a) data2(in=b);
by ID Store;
if a and b;
run ;
यह विशेष उदाहरण आईडी और स्टोर नामक वेरिएबल्स के आधार पर डेटा1 और डेटा2 नामक डेटा सेट को मर्ज करता है और केवल उन पंक्तियों को लौटाता है जहां दोनों डेटा सेट में एक मान मौजूद है।
निम्नलिखित उदाहरण दिखाता है कि व्यवहार में इस वाक्यविन्यास का उपयोग कैसे करें।
उदाहरण: दो वेरिएबल्स के आधार पर एसएएस में डेटा सेट मर्ज करें
मान लीजिए कि हमारे पास एसएएस में निम्नलिखित डेटासेट है जिसमें किसी कंपनी के सेल्सपर्सन के बारे में जानकारी है:
/*create first dataset*/
data data1;
inputStoreID $;
datalines ;
1A
1B
1 C
2A
2C
3A
3 B
;
run ;
/*view first dataset*/
title "data1";
proc print data = data1;
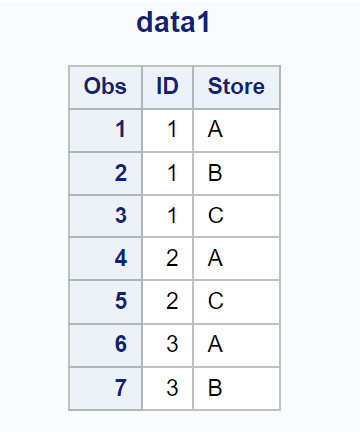
और मान लीजिए कि हमारे पास एक और डेटासेट है जिसमें प्रत्येक सहयोगी द्वारा विभिन्न दुकानों में की गई बिक्री के बारे में जानकारी है:
/*create second dataset*/
data data2;
input Store ID $Sales;
datalines ;
1 to 22
1 B 25
2 to 40
2 B 24
2 C 29
3 to 12
3 B 15
;
run ;
/*view second dataset*/
title "data2";
proc print data = data2;
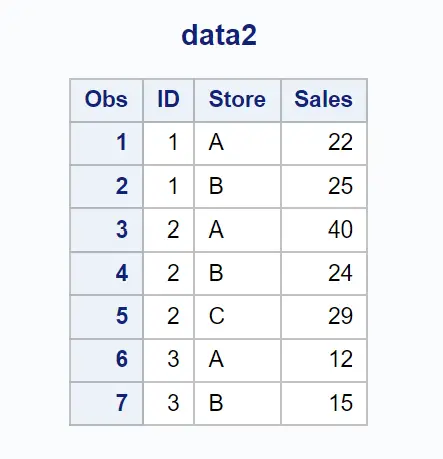
हम आईडी और स्टोर कॉलम में मेल खाने वाले मानों के आधार पर दो डेटासेट को मर्ज करने के लिए निम्नलिखित मर्ज स्टेटमेंट का उपयोग कर सकते हैं, फिर केवल उन पंक्तियों को लौटा सकते हैं जहां दोनों कॉलम में एक मान मौजूद है:
/*perform merge*/
data final_data;
merge data1(in=a) data2(in=b);
by ID Store;
if a and b;
run ;
/*view results*/
title "final_data";
proc print data =final_data;
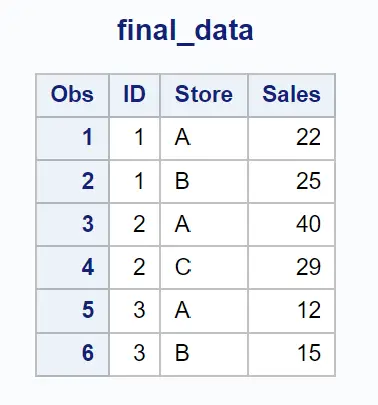
परिणामी डेटासेट पंक्तियाँ लौटाता है जिसमें आईडी और स्टोर कॉलम मान मेल खाते हैं।
नोट : आप एसएएस मर्ज स्टेटमेंट के लिए संपूर्ण दस्तावेज़ यहां पा सकते हैं।
अतिरिक्त संसाधन
निम्नलिखित ट्यूटोरियल बताते हैं कि एसएएस में अन्य सामान्य कार्य कैसे करें:
एसएएस: एक-से-अनेक मर्ज कैसे करें
एसएएस: मर्ज स्टेटमेंट में (in=a) का उपयोग कैसे करें
एसएएस: यदि ए बी नहीं है तो विलय कैसे करें
लेखक के बारे में
डॉ. बेंजामिन एंडरसन
नमस्ते, मैं बेंजामिन हूं, एक सेवानिवृत्त सांख्यिकी प्रोफेसर जो अब समर्पित Statorials शिक्षक बन गया है। सांख्यिकी के क्षेत्र में व्यापक अनुभव और विशेषज्ञता के साथ, मैं Statorials के माध्यम से छात्रों को सशक्त बनाने के लिए अपना ज्ञान साझा करने के लिए उत्सुक हूं। अधिक जाने