एसएएस में एलएसएमईएएनएस कथन का उपयोग कैसे करें (उदाहरण के साथ)
एक-तरफ़ा एनोवा का उपयोग यह निर्धारित करने के लिए किया जाता है कि तीन या अधिक स्वतंत्र समूहों के साधनों के बीच सांख्यिकीय रूप से महत्वपूर्ण अंतर है या नहीं।
यदि एनोवा तालिका का समग्र पी-मूल्य एक निश्चित स्तर के महत्व से नीचे है, तो हमारे पास यह कहने के लिए पर्याप्त सबूत हैं कि समूह का कम से कम एक साधन दूसरों से अलग है।
यह पता लगाने के लिए कि वास्तव में किस समूह के साधन भिन्न हैं, हमें एक पोस्ट हॉक परीक्षण करने की आवश्यकता है।
आप विभिन्न पोस्ट-हॉक परीक्षण करने के लिए एसएएस में एलएसएमईएएनएस कथन का उपयोग कर सकते हैं।
निम्नलिखित उदाहरण दिखाता है कि व्यवहार में LSMEANS कथन का उपयोग कैसे करें।
उदाहरण: एसएएस में एलएसएमईएएनएस कथन का उपयोग कैसे करें
मान लीजिए कि एक शोधकर्ता एक अध्ययन में भाग लेने के लिए 30 छात्रों की भर्ती करता है। छात्रों को परीक्षा की तैयारी के लिए तीन अध्ययन विधियों में से एक का उपयोग करने के लिए यादृच्छिक रूप से नियुक्त किया जाता है।
प्रत्येक छात्र के परीक्षा परिणाम नीचे दिखाए गए हैं:
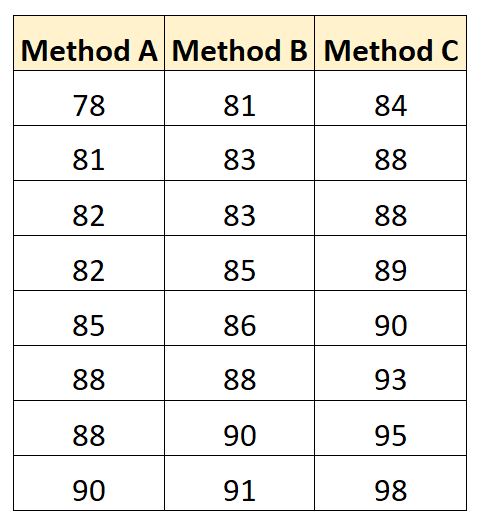
हम एसएएस में इस डेटासेट को बनाने के लिए निम्नलिखित कोड का उपयोग कर सकते हैं:
/*create dataset*/
data my_data;
input Method $Score;
datalines ;
At 78
At 81
At 82
At 82
At 85
At 88
At 88
At 90
B 81
B 83
B 83
B85
B 86
B 88
B90
B91
C 84
C 88
C 88
C 89
C 90
C 93
C 95
C 98
;
run ;
इसके बाद, हम एक-तरफ़ा एनोवा निष्पादित करने के लिए proc ANOVA का उपयोग करेंगे:
/*perform one-way ANOVA*/
proc ANOVA data =my_data;
classMethod ;
modelScore = Method;
run ;
यह निम्नलिखित एनोवा तालिका तैयार करता है:
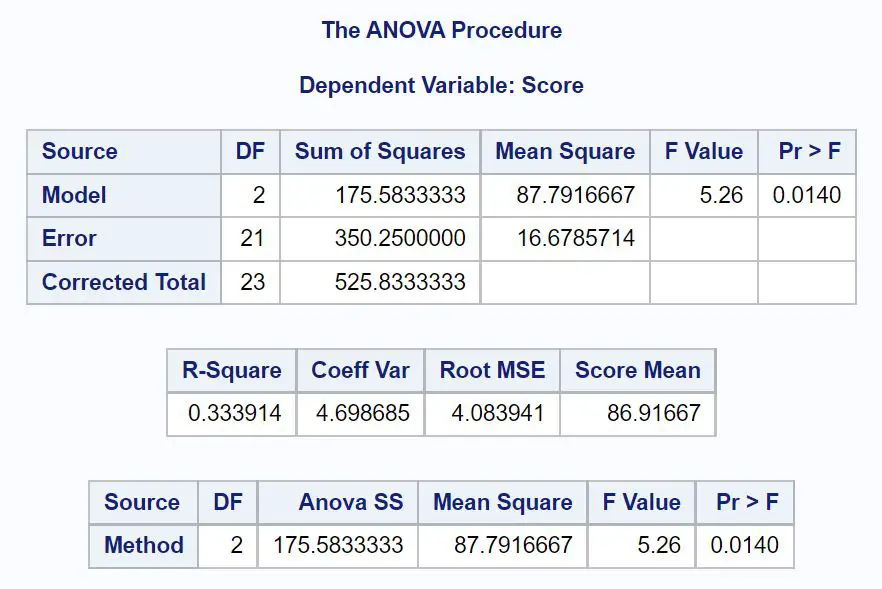
इस तालिका से हम देख सकते हैं:
- कुल एफ-वैल्यू: 5.26
- संगत पी-मान: 0.0140
याद रखें कि एक-तरफ़ा एनोवा निम्नलिखित शून्य और वैकल्पिक परिकल्पनाओं का उपयोग करता है:
- एच 0 : सभी समूह साधन समान हैं।
- एच ए : कम से कम एक समूह का औसत अलग है आराम।
चूँकि एनोवा तालिका का पी-मान ( 0.0140 ) α = 0.05 से कम है, हम शून्य परिकल्पना को अस्वीकार करते हैं।
यह हमें बताता है कि तीनों अध्ययन विधियों में औसत परीक्षा स्कोर बराबर नहीं है।
यह निर्धारित करने के लिए कि कौन से समूह के साधन भिन्न हैं, हम तुकी के पोस्ट-हॉक परीक्षण करने के लिए LSMEANS कथन और ADJUST=TUKEY विकल्प के साथ PROC GLIMMIX कथन का उपयोग कर सकते हैं:
/*perform Tukey post-hoc comparisons*/
proc glimmix data =my_data;
classMethod ;
modelScore = Method;
lsmeans Method / adjust =tukey alpha = .05 ;
run ;
अंतिम परिणाम तालिका तुकी की पोस्ट-हॉक तुलनाओं के परिणाम दिखाती है:

समूह साधनों में अंतर के लिए समायोजित पी-मूल्यों को देखने के लिए हम एडजे पी कॉलम को देख सकते हैं।
इस कॉलम में, हम देख सकते हैं कि 0.05 से कम समायोजित पी-मान वाली केवल एक पंक्ति है: वह पंक्ति जो समूह ए और समूह सी के बीच औसत अंतर की तुलना करती है।
यह हमें बताता है कि ग्रुप ए और ग्रुप सी के बीच औसत परीक्षा अंकों में सांख्यिकीय रूप से महत्वपूर्ण अंतर है।
सीधे तौर पर, हम देख सकते हैं:
- ग्रुप ए के छात्रों और ग्रुप बी के छात्रों के औसत परीक्षा अंकों के बीच का अंतर था – 6.375 । (यानी समूह ए के छात्रों का औसत परीक्षा स्कोर समूह सी के छात्रों की तुलना में 6.375 अंक कम था)
- साधनों में अंतर के लिए समायोजित पी-मान 0.0137 है।
- इन दो समूहों के बीच औसत परीक्षा स्कोर में वास्तविक अंतर के लिए समायोजित 95% आत्मविश्वास अंतराल [-11.5219, -1.2281] है।
अन्य समूहों के साधनों के बीच कोई सांख्यिकीय महत्वपूर्ण अंतर नहीं है।
नोट : इस उदाहरण में, हमने तुकी पोस्ट-हॉक तुलना करने के लिए ADJUST=TUKEY का उपयोग किया, लेकिन आप अन्य प्रकार की पोस्ट-हॉक तुलना करने के लिए BON , BUNNET , NELSON , SCHEFFE , SIDAK , और SMM भी निर्दिष्ट कर सकते हैं।
सम्बंधित: तुकी बनाम. बोनफेरोनी बनाम. शेफ़े: आपको कौन सा परीक्षण उपयोग करना चाहिए?
अतिरिक्त संसाधन
निम्नलिखित ट्यूटोरियल एनोवा मॉडल के बारे में अतिरिक्त जानकारी प्रदान करते हैं:
एनोवा के साथ पोस्ट-हॉक परीक्षण का उपयोग करने के लिए एक गाइड
एसएएस में वन-वे एनोवा कैसे निष्पादित करें
एसएएस में दो-तरफ़ा एनोवा कैसे निष्पादित करें
लेखक के बारे में
डॉ. बेंजामिन एंडरसन
नमस्ते, मैं बेंजामिन हूं, एक सेवानिवृत्त सांख्यिकी प्रोफेसर जो अब समर्पित Statorials शिक्षक बन गया है। सांख्यिकी के क्षेत्र में व्यापक अनुभव और विशेषज्ञता के साथ, मैं Statorials के माध्यम से छात्रों को सशक्त बनाने के लिए अपना ज्ञान साझा करने के लिए उत्सुक हूं। अधिक जाने