Z स्कोर सामान्यीकरण: परिभाषा और उदाहरण
Z-स्कोर सामान्यीकरण डेटा सेट में प्रत्येक मान को सामान्य करने की प्रक्रिया को संदर्भित करता है जैसे कि सभी मानों का माध्य 0 है और मानक विचलन 1 है।
डेटासेट में प्रत्येक मान पर z-स्कोर सामान्यीकरण करने के लिए हम निम्नलिखित सूत्र का उपयोग करते हैं:
नया मान = (x – μ) / σ
सोना:
- x : मूल मान
- μ : डेटा का औसत
- σ : डेटा का मानक विचलन
निम्नलिखित उदाहरण दिखाता है कि व्यवहार में डेटासेट पर z-स्कोर सामान्यीकरण कैसे किया जाता है।
उदाहरण: Z-स्कोर सामान्यीकरण करना
मान लीजिए हमारे पास निम्नलिखित डेटा सेट है:

कैलकुलेटर का उपयोग करके, हम देख सकते हैं कि डेटा सेट का माध्य 21.2 है और मानक विचलन 29.8 है।
डेटासेट में पहले मान पर z-स्कोर सामान्यीकरण करने के लिए, हम निम्नलिखित सूत्र का उपयोग कर सकते हैं:
- नया मान = (x – μ) / σ
- नया मान = (3 – 21.2) / 29.8
- नया मान = -0.61
हम डेटासेट में प्रत्येक मान पर z-स्कोर सामान्यीकरण करने के लिए इस सूत्र का उपयोग कर सकते हैं:
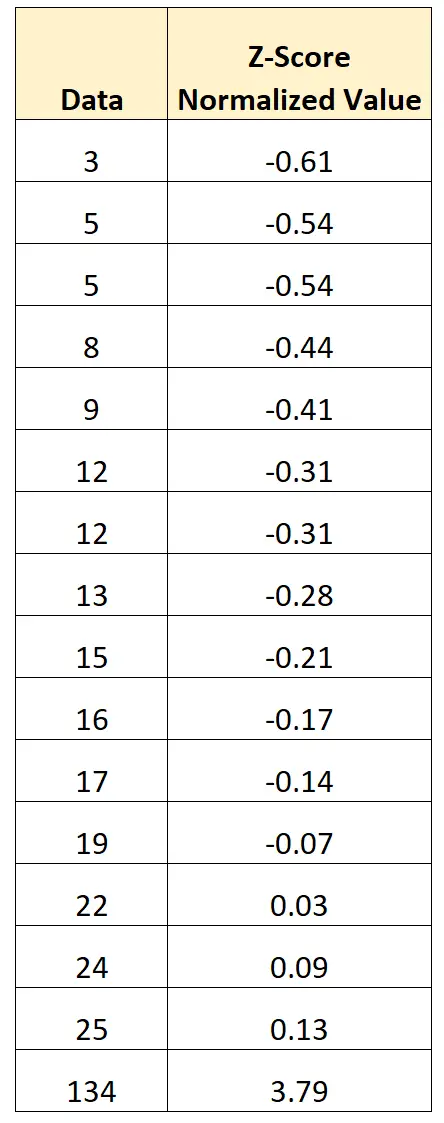
सामान्यीकृत मानों का माध्य 0 है और सामान्यीकृत मानों का मानक विचलन 1 है।
सामान्यीकृत मान मूल मान और माध्य के बीच मानक विचलन की संख्या का प्रतिनिधित्व करते हैं।
उदाहरण के लिए:
- डेटासेट में पहला मान माध्य से 0.61 मानक विचलन नीचे है।
- डेटासेट में दूसरा मान माध्य से 0.54 मानक विचलन नीचे है।
- …
- डेटासेट में अंतिम मान माध्य से 3.79 मानक विचलन ऊपर है।
इस प्रकार के सामान्यीकरण को निष्पादित करने का लाभ यह है कि डेटा सेट (134) में स्पष्ट आउटलेयर को इस तरह से बदल दिया गया है कि यह अब बड़े पैमाने पर आउटलेयर नहीं है।
यदि हम इस डेटासेट का उपयोग किसी प्रकार के मशीन लर्निंग मॉडल को फिट करने के लिए करते हैं, तो आउटलेयर का उतना प्रभाव नहीं होगा जितना मॉडल फिट पर हो सकता है।
अतिरिक्त संसाधन
निम्नलिखित ट्यूटोरियल विभिन्न सामान्यीकरण तकनीकों पर अतिरिक्त जानकारी प्रदान करते हैं:
मानकीकरण या सामान्यीकरण: क्या अंतर है?
0 और 1 के बीच डेटा को सामान्य कैसे करें
0 और 100 के बीच डेटा को सामान्य कैसे करें
लेखक के बारे में
डॉ. बेंजामिन एंडरसन
नमस्ते, मैं बेंजामिन हूं, एक सेवानिवृत्त सांख्यिकी प्रोफेसर जो अब समर्पित Statorials शिक्षक बन गया है। सांख्यिकी के क्षेत्र में व्यापक अनुभव और विशेषज्ञता के साथ, मैं Statorials के माध्यम से छात्रों को सशक्त बनाने के लिए अपना ज्ञान साझा करने के लिए उत्सुक हूं। अधिक जाने