डेटा को r में कैसे केन्द्रित करें (उदाहरण के साथ)
डेटा सेट को केन्द्रित करने का अर्थ है डेटा सेट में प्रत्येक व्यक्तिगत अवलोकन का औसत मूल्य घटाना।
उदाहरण के लिए, मान लें कि हमारे पास निम्नलिखित डेटा सेट है:
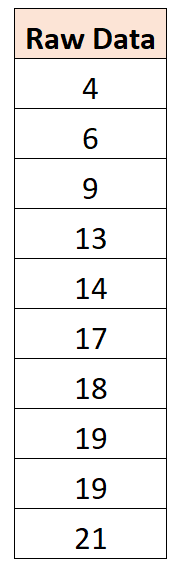
यह पता चला है कि औसत मान 14 है। इसलिए, इस डेटा सेट को केन्द्रित करने के लिए, हम प्रत्येक व्यक्तिगत अवलोकन से 14 घटाएंगे:
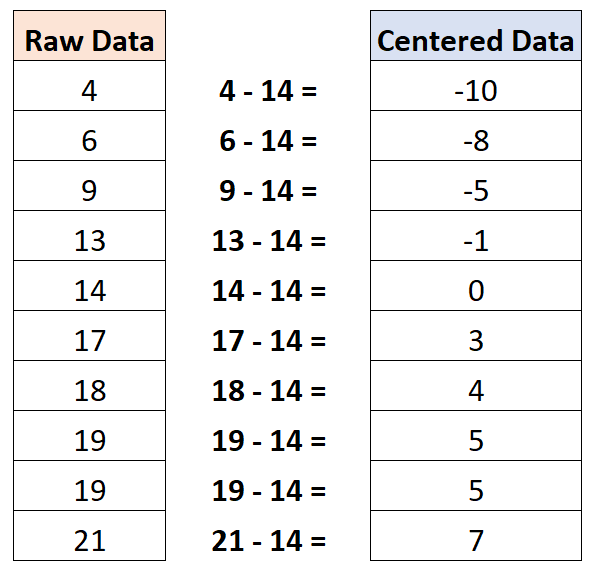
ध्यान दें कि केन्द्रित डेटासेट का माध्य मान शून्य है।
यह ट्यूटोरियल आर में डेटा को केन्द्रित करने के कई उदाहरण प्रदान करता है।
उदाहरण 1: एक वेक्टर के मानों को केन्द्रित करें
निम्नलिखित कोड दिखाता है कि वेक्टर में मूल्यों को केन्द्रित करने के लिए आधार R स्केल() फ़ंक्शन का उपयोग कैसे करें:
#createvector data <- c(4, 6, 9, 13, 14, 17, 18, 19, 19, 21) #subtract the mean value from each observation in the vector scale(data, scale= FALSE ) [,1] [1,] -10 [2,] -8 [3,] -5 [4,] -1 [5,] 0 [6,] 3 [7,] 4 [8,] 5 [9,] 5 [10,] 7 attr(,"scaled:center") [1] 14
परिणामी मान डेटासेट के केंद्रित मान हैं। स्केल() फ़ंक्शन हमें यह भी बताता है कि डेटासेट का औसत मूल्य 14 है।
ध्यान दें कि स्केल() फ़ंक्शन, डिफ़ॉल्ट रूप से, प्रत्येक व्यक्तिगत अवलोकन से माध्य घटाता है और फिर इसे मानक विचलन से विभाजित करता है।
स्केल = FALSE निर्दिष्ट करके हम R को मानक विचलन से विभाजित न करने के लिए कहते हैं।
उदाहरण 2: डेटा फ़्रेम में केंद्र स्तंभ
निम्नलिखित कोड दिखाता है कि डेटा फ़्रेम के प्रत्येक कॉलम के मानों को केंद्रित करने के लिए R डेटाबेस के sapply() फ़ंक्शन और स्केल() फ़ंक्शन का उपयोग कैसे करें:
#create data frame df <- data.frame(x = c(1, 4, 5, 6, 6, 8, 9), y = c(7, 7, 8, 8, 8, 9, 12), z = c(3, 3, 4, 4, 6, 7, 7)) #center each column in the data frame df_new <- sapply(df, function (x) scale(x, scale= FALSE )) #display data frame df_new X Y Z [1,] -4.5714286 -1.4285714 -1.8571429 [2,] -1.5714286 -1.4285714 -1.8571429 [3,] -0.5714286 -0.4285714 -0.8571429 [4,] 0.4285714 -0.4285714 -0.8571429 [5,] 0.4285714 -0.4285714 1.1428571 [6,] 2.4285714 0.5714286 2.1428571 [7,] 3.4285714 3.5714286 2.1428571
हम colMeans() फ़ंक्शन का उपयोग करके जांच सकते हैं कि नए डेटा फ़्रेम में प्रत्येक कॉलम का माध्य शून्य है:
colMeans(df_new)
xyz 2.537653e-16 -2.537653e-16 3.806479e-16
मान वैज्ञानिक संकेतन में दिखाए जाते हैं, लेकिन प्रत्येक मान मूलतः शून्य होता है।
अतिरिक्त संसाधन
आर में कॉलमों का औसत कैसे निकालें
आर में विशिष्ट कॉलमों का योग कैसे करें
आर में एकाधिक कॉलम से आउटलेर्स को कैसे हटाएं
लेखक के बारे में
डॉ. बेंजामिन एंडरसन
नमस्ते, मैं बेंजामिन हूं, एक सेवानिवृत्त सांख्यिकी प्रोफेसर जो अब समर्पित Statorials शिक्षक बन गया है। सांख्यिकी के क्षेत्र में व्यापक अनुभव और विशेषज्ञता के साथ, मैं Statorials के माध्यम से छात्रों को सशक्त बनाने के लिए अपना ज्ञान साझा करने के लिए उत्सुक हूं। अधिक जाने